Verrauschtes Audio transkribieren und Fehler durch Hintergrundgeräusche reduzieren (2026)
Hintergrundgeräusche sind die größte Ursache für Transkriptionsfehler. Ein praktischer Leitfaden zu saubererer Aufnahme, wichtigen Einstellungen, wann Rauschunterdrückung vor der Transkription hilft oder schadet und wie Sie mit nicht mehr rettbarem Audio umgehen.
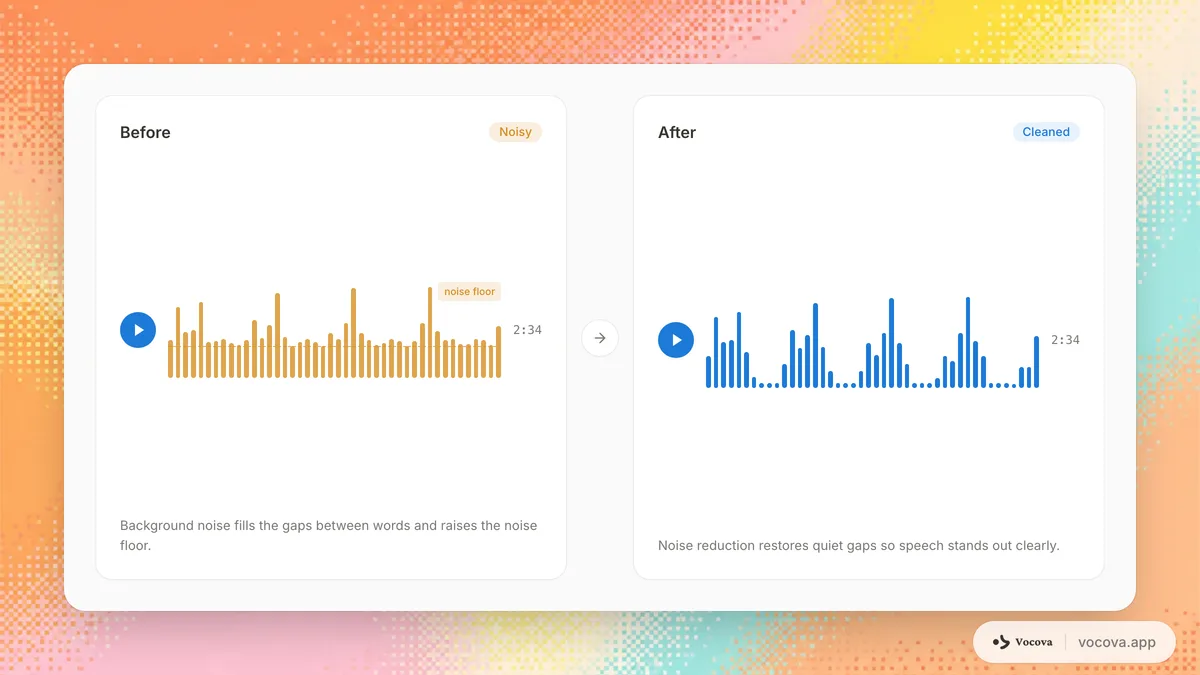
Hintergrundgeräusche sind die häufigste Ursache für Transkriptionsfehler. Selbst die fortschrittlichsten KI-Spracherkennungsmodelle haben Schwierigkeiten, wenn das Audiosignal mit Verkehr, Klimaanlagenbrummen, Nebengesprächen oder Raumhall konkurriert. Eine Aufnahme, die in einem ruhigen Raum nahezu perfekt transkribiert wird, kann in einer lauten Umgebung stark einbrechen und ein nützliches Transkript in etwas verwandeln, das umfangreiche manuelle Korrektur erfordert.
Die gute Nachricht ist, dass die meisten Probleme mit verrauschtem Audio entweder vermeidbar oder behebbar sind. Dieser Leitfaden behandelt die gesamte Kette: wie Sie von vornherein saubereres Audio aufnehmen, wie Sie verrauschte Aufnahmen vor der Transkription verarbeiten, wie Sie Ihre Transkriptionseinstellungen für optimale Ergebnisse konfigurieren und wie Sie mit Fällen umgehen, in denen das Audio wirklich nicht mehr zu retten ist.
Warum Hintergrundgeräusche die Transkriptionsgenauigkeit beeinflussen
Um zu verstehen, warum Geräusche Transkriptionsfehler verursachen, hilft es zu wissen, wie automatische Spracherkennung (ASR) auf grundlegender Ebene funktioniert.
ASR-Modelle wandeln Audio in Text um, indem sie die akustischen Eigenschaften des Klangs analysieren, das Signal in kleine Zeitfenster aufteilen und vorhersagen, welche Wörter oder Phoneme an jedem Punkt am wahrscheinlichsten sind. Das Modell wurde auf Tausenden von Stunden Sprache trainiert und hat die statistischen Muster gelernt, die ein Wort von einem anderen unterscheiden.
Hintergrundgeräusche stören diesen Prozess, indem sie akustische Energie hinzufügen, die nicht der Sprache entspricht. Wenn ein Lüfterbrummen oder Gemurmel einer Menschenmenge denselben Frequenzbereich wie die Stimme des Sprechers einnimmt, kann das Modell die beiden Signale nicht sauber trennen. Es trifft seine beste Schätzung, aber diese Schätzungen werden weniger zuverlässig, je mehr der Geräuschpegel steigt.
Der Fachbegriff dafür ist Signal-Rausch-Verhältnis (SNR). Das SNR misst, wie viel lauter das Sprachsignal im Vergleich zum Hintergrundgeräusch ist, ausgedrückt in Dezibel. Ein SNR von 30 dB oder höher (Sprache ist viel lauter als Rauschen) liefert gute Transkriptionsergebnisse. Ein SNR unter 10 dB (Sprache ist kaum lauter als Rauschen) führt zu erheblichem Genauigkeitsverlust. Der Verlust ist steil, nicht allmählich: Die Fehlerrate steigt stark an, sobald das SNR fällt. Deshalb kann schon etwas mehr Mikrofonabstand oder eine einzige laufende Klimaanlage die Genauigkeit kippen.
Transkriptionsgenauigkeit wird typischerweise mit der Wortfehlerrate (WER) gemessen. Ein ruhiges, gut aufgenommenes Interview kann unter 5 % WER liegen; dieselbe Unterhaltung in einem belebten Cafe kann über 20-25 % steigen. Die genauen Werte hängen von Modell, Sprache und Geräuschtyp ab — siehe Transkriptionsgenauigkeit nach Sprache, um zu sehen, wie stark schon die Clean-Audio-Basis je nach Sprache variiert — aber die Lücke hier ist fast vollständig auf Geräusche zurückzuführen.
Arten von Audiogeräuschen
Nicht alle Geräusche beeinflussen die Transkription gleichermaßen. Das Verständnis der Art des Geräusches in Ihrer Aufnahme hilft Ihnen, den richtigen Ansatz zu wählen.
Umgebungsgeräusche
Konstante Hintergrundgeräusche wie Klimaanlagen, Verkehr, Ventilatoren oder Kühlschrankbrummen. Diese Art von Geräusch ist in Lautstärke und Frequenz relativ konstant, was es am einfachsten macht, es mit Rauschunterdrückungstools zu entfernen. Wenn es jedoch laut genug ist, beeinträchtigt es dennoch die Transkriptionsgenauigkeit.
Elektronisches Rauschen
Rauschen, Brummen oder Summen, das von der Aufnahmegerätschaft selbst eingeführt wird. Häufige Ursachen sind minderwertige Mikrofone, Erdungsschleifen bei kabelgebundenen Setups, elektromagnetische Interferenzen von benachbarter Elektronik und Audio-Interfaces mit hohem Rauschpegel. Elektronisches Rauschen ist normalerweise konstant und mit Rauschunterdrückung behandelbar.
Nachhall
Echo, das durch Schallreflexion an harten Oberflächen in einem Raum verursacht wird. Nachhall verschmiert das Sprachsignal über die Zeit und erschwert es ASR-Modellen, Wortgrenzen zu identifizieren. Ein Sprecher in einem gefliesten Badezimmer oder leeren Konferenzraum erzeugt deutlich mehr Nachhall als einer in einem teppichbelegten, möblierten Büro. Nachhall ist schwieriger zu entfernen als Umgebungsgeräusche, da er eine transformierte Version des Originalsignals ist.
Nebengespräche und überlappende Sprache
Mehrere Personen, die gleichzeitig sprechen. Dies ist eine der schwierigsten Geräuscharten für die Transkription, da das störende Signal selbst Sprache ist und das Modell Schwierigkeiten hat, die beiden Sprecher zu trennen. Nebengespräche treten häufig in Meetings, Podiumsdiskussionen und Gruppeninterviews auf.
Windgeräusche
Tieffrequentes Rumpeln, das durch Luftbewegung über dem Mikrofon verursacht wird. Windgeräusche sind bei Außenaufnahmen häufig und können bei starken Böen die Sprache vollständig maskieren. Sie betreffen hauptsächlich den Tieftonbereich des Frequenzspektrums und können oft mit einem Hochpassfilter oder einer Windschutzhaube reduziert werden.
Impulsgeräusche
Plötzliche, kurzzeitige Geräusche wie Tastaturklicks, Papierschlurfen, Husten oder Baustellenschläge. Diese sind kurz, können aber einzelne Wörter oder Phrasen verfälschen. ASR-Modelle können ein scharfes Klicken als Konsonantenklang fehlinterpretieren und Phantomwörter in das Transkript einfügen.
Tipps für saubereres Audio vor der Aufnahme
Der effektivste Weg, genaue Transkriptionen aus verrauschten Umgebungen zu erhalten, ist, von vornherein besseres Audio aufzunehmen. Ein paar Minuten Vorbereitung vor dem Drücken der Aufnahmetaste können Stunden nachträglicher Bereinigung ersparen.
Das richtige Mikrofon wählen
Die Mikrofonwahl hat einen großen Einfluss auf die Geräuschunterdrückung.
- Lavalier-Mikrofone (Ansteckmikrofone) werden nah am Mund des Sprechers befestigt und halten das Sprachsignal im Verhältnis zum Raumgeräusch stark. Sie sind ideal für Interviews und Präsentationen.
- Richtmikrofone (Niere oder Shotgun) nehmen Schall hauptsächlich von vorne auf und weisen Schall von den Seiten und hinten ab. Richten Sie sie auf den Sprecher und weg von Geräuschquellen.
- Omnidirektionale Mikrofone nehmen Schall gleichmäßig aus allen Richtungen auf. Sie sind nützlich für Gruppendiskussionen, nehmen aber mehr Umgebungsgeräusche auf.
- Headset-Mikrofone positionieren die Kapsel nah am Mund und sind hervorragend für laute Umgebungen -- daher werden sie in Callcentern und von Piloten verwendet.
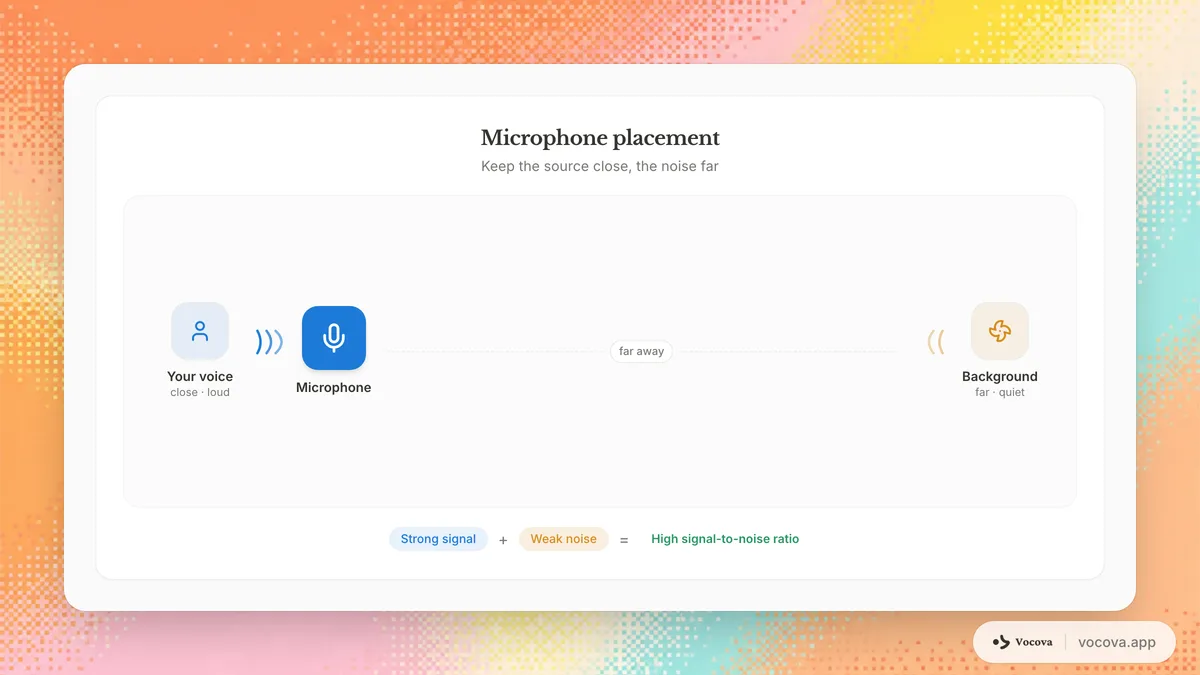
Das Mikrofon richtig positionieren
Abstand ist wichtiger, als die meisten Menschen annehmen. Eine Verdopplung des Abstands zwischen Mikrofon und Sprecher reduziert das Sprachsignal um etwa 6 dB, während der Hintergrundgeräuschpegel gleich bleibt. Halten Sie das Mikrofon so nah am Sprecher wie praktisch möglich.
Für ein Lavalier-Mikrofon befestigen Sie es 15-20 cm unterhalb des Kinns. Für ein Tischmikrofon positionieren Sie es 15-30 cm vom Mund des Sprechers entfernt. Vermeiden Sie es, Mikrofone in der Nähe von Geräuschquellen wie Computerlüftern, Lüftungsschlitzen oder Fenstern zu einer belebten Straße zu platzieren.
Den Raum behandeln
Sie brauchen kein professionelles Studio, um Geräusche und Nachhall deutlich zu reduzieren.
- Schließen Sie Fenster und Türen, um externe Geräusche zu blockieren
- Schalten Sie Klimaanlagen, Ventilatoren und unnötige Elektronik während der Aufnahme aus
- Fügen Sie weiche Materialien (Vorhänge, Teppiche, gepolsterte Möbel) hinzu, um Echo zu reduzieren
- Vermeiden Sie Räume mit harten, parallelen Oberflächen (Fliesenboden, Glaswände), die Nachhall erzeugen
- Wenn Sie im Büro aufnehmen, wählen Sie einen kleineren, teppichbelegten Raum anstelle eines großen Konferenzraums
Einen Windschutz im Freien verwenden
Wenn Sie draußen aufnehmen, verwenden Sie einen Schaumstoff-Windschutz oder einen pelzigen Windüberzug (oft „Katze" genannt) auf Ihrem Mikrofon. Windgeräusche sind extrem störend für die Transkription und fast unmöglich, in der Nachbearbeitung vollständig zu entfernen.
Eine Referenz-Geräuschprobe aufnehmen
Bevor der Sprecher zu reden beginnt, nehmen Sie 10 bis 15 Sekunden nur des Raumgeräuschs auf. Dieser „Geräusch-Abdruck" ist nützlich für Rauschunterdrückungstools, die ihn verwenden, um die Eigenschaften des Geräuschs zu lernen und es von der Aufnahme zu subtrahieren.
Aufnahmeeinstellungen, die die Transkriptionsgenauigkeit beeinflussen
Über die Mikrofonwahl und Raumbehandlung hinaus bestimmen einige technische Aufnahmeeinstellungen, wie viel stimmliches Detail bis zur Transkriptionsstufe erhalten bleibt.
Abtastrate. Die meisten modernen ASR-Modelle resamplen alles intern auf 16 kHz — die Rate, auf der sie trainiert wurden — daher bringt eine höhere Abtastrate keinen Genauigkeitsvorteil. Nehmen Sie mit 44,1 kHz oder 48 kHz für Kompatibilität und saubere Archivierung auf, nicht für bessere Transkriptionsgenauigkeit; 16 kHz mono ist für das Modell bereits ausreichend. Über 48 kHz gibt es keinen Vorteil für Spracherkennung.
Bittiefe. Nehmen Sie mit 16 Bit oder 24 Bit auf. Der Unterschied ist bei leisen Passagen am wichtigsten: 24 Bit erfasst leise Sprache mit weniger Quantisierungsrauschen, was hilft, wenn der Sprecher weiter vom Mikrofon entfernt ist.
Mono vs. Stereo. Für einen einzelnen Sprecher ist Mono in Ordnung und erzeugt kleinere Dateien. Für mehrere Sprecher verbessert die Aufnahme jeder Stimme auf einen separaten Kanal die Sprecherdiarisierung messbar, weil das Modell Stimmen trennen kann, die auf eigenen, sauberen Kanälen ankommen.
Dateiformat. WAV und FLAC sind verlustfrei und ideal für die Transkription. MP3 mit 192 kbps oder höher ist akzeptabel; AAC/M4A (von den meisten Telefonen verwendet) ist bei gleicher Bitrate etwas besser als MP3; OGG/Opus bietet gute Qualität bei niedrigeren Bitraten. Wenn der Speicherplatz es zulässt, archivieren Sie in WAV oder FLAC. Die meisten Tools, einschließlich Vocova, akzeptieren alle gängigen Formate -- die Priorität liegt darin, das Detail in der Aufnahme selbst zu erhalten, nicht im Container.
Mikrofontyp und Anschluss wählen
Die obigen Mikrofonhinweise konzentrieren sich auf die Richtcharakteristik zur Geräuschunterdrückung. Zwei weitere Entscheidungen legen die Grundqualität jeder Aufnahme fest.
- Kondensator vs. dynamisch. Kondensatormikrofone sind empfindlicher und erfassen mehr stimmliches Detail, was in ruhigen, kontrollierten Räumen hilft -- sie nehmen aber auch mehr Umgebungsgeräusche auf. Dynamische Mikrofone weisen konstruktionsbedingt mehr Hintergrundgeräusche ab, was sie zur sichereren Wahl in unbehandelten oder lauten Räumen macht.
- USB vs. XLR. USB-Mikrofone (zum Beispiel das Rode NT-USB Mini oder Audio-Technica AT2020USB+) enthalten ein integriertes Audio-Interface und sind für die meisten Menschen die pragmatische Wahl. XLR-Mikrofone benötigen ein separates Interface, bieten aber einen niedrigeren Rauschpegel und mehr Kontrolle -- vor allem dann lohnenswert, wenn Sie das Interface bereits besitzen.
Für die Transkription ist die Umgebung wichtiger als das spezifische Mikrofon. Ein USB-Mikrofon für 50–100 $, richtig in einem ruhigen Raum platziert, erzeugt Audio in Transkriptionsqualität.
Tipps für spezifische Aufnahmeszenarien
- Meetings: Verwenden Sie ein spezielles Konferenzmikrofon (wie das Jabra Speak oder Anker PowerConf) in der Mitte des Tisches statt eines Laptop-Mikrofons. Bei Remote-Meetings nehmen Sie die Audioausgabe der Meeting-Software direkt auf und bitten Sie die Teilnehmer, Headsets zu tragen, um Echo zu vermeiden.
- Interviews: Geben Sie dem Interviewer und dem Interviewten separate Mikrofone -- idealerweise drahtlose Lavalier-Mikrofone, die auf separate Kanäle aufgenommen werden. Bei Telefoninterviews nehmen Sie über Software auf, statt ein Mikrofon auf einen Freisprech-Lautsprecher zu richten.
- Vorträge: Ein Lavalier-Mikrofon am Vortragenden ist das zuverlässigste Setup. Lassen Sie den Vortragenden Publikumsfragen wiederholen, bevor er antwortet, da Publikumston selten sauber erfasst wird.
- Podcasts: Geben Sie jedem Host und Gast ein eigenes Mikrofon auf einer separaten Spur. Bei Remote-Aufnahmen lassen Sie jeden Teilnehmer lokal aufnehmen (mit Tools wie Riverside.fm oder Zencastr) und kombinieren die Spuren anschließend, um Komprimierungsartefakte von Videoanrufen zu vermeiden.
Häufige Aufnahmefehler, die die Transkription beeinträchtigen
- Telefon in einer Tasche oder einem Beutel. Stoff dämpft die hohen Frequenzen, die zur Unterscheidung von Konsonanten nötig sind, und Bewegung fügt Rascheln hinzu. Legen Sie das Telefon auf eine stabile Oberfläche, dem Sprecher zugewandt.
- Zu weit vom Mikrofon entfernt sitzen. Abstand schwächt das Sprachsignal, während das Hintergrundgeräusch konstant bleibt, sodass die Aufnahme am Ende geräuschdominiert ist. Bleiben Sie nah dran.
- Gain zu hoch eingestellt. Clipping ist eine dauerhafte Verzerrung, die nicht repariert werden kann. Stellen Sie die Pegel so ein, dass normale Sprache bei etwa -12 dB bis -6 dB Spitzen erreicht.
- Gain zu niedrig eingestellt. Zu leise aufzunehmen zwingt Sie, später zu verstärken, was auch den Rauschpegel verstärkt.
- Aufnahme über Bluetooth. Das Bluetooth-Freisprechprofil komprimiert Anrufaudio stark. Verwenden Sie für die Aufnahme nach Möglichkeit eine kabelgebundene Verbindung.
- Keine Testaufnahme. Nehmen Sie 30 Sekunden auf und spielen Sie sie ab, bevor die eigentliche Sitzung beginnt. Raumhall, Brummen oder Griffgeräusche vorab zu erkennen ist weitaus günstiger, als sie nach einer zweistündigen Aufnahme zu entdecken.
So bereinigen Sie verrauschtes Audio vor der Transkription
Wenn Sie bereits eine verrauschte Aufnahme haben, können Audioverarbeitungstools die Signalqualität verbessern, bevor Sie sie an einen Transkriptionsdienst senden. Die Ergebnisse werden nicht an eine saubere Originalaufnahme heranreichen, können aber helfen.
Ein überraschender Vorbehalt: Entrauschen hilft KI-Transkription nicht immer. Whisper-ähnliche Modelle wurden mit viel unperfektem Audio trainiert, und mehrere Studien aus 2025-2026 (zum Beispiel When De-noising Hurts, 2025, und When Denoising Hinders, 2026) fanden, dass Speech-Enhancement- und Denoising-Tools die Wortfehlerrate sogar erhöhen können — teils deutlich — selbst wenn das Audio für Menschen sauberer klingt. Der Grund sind Artefakte, auf die das Modell nicht trainiert wurde. Die verlässliche Regel lautet: Verarbeiten Sie eine kurze Probe auf beide Arten, transkribieren Sie beide und behalten Sie die bessere Version. Erstaunlich oft ist das die Rohaufnahme. Die Tools unten helfen am meisten bei konstantem, gut charakterisierbarem Rauschen; am wenigsten helfen sie — und können schaden — bei sprachähnlichen Störungen und Hall.
Audacity (kostenlos, Open Source)
Audacity ist ein kostenloser Audio-Editor mit integriertem Rauschunterdrückungstool.
- Wählen Sie einen Abschnitt des Audios, der nur Geräusche enthält (keine Sprache)
- Gehen Sie zu Effekt > Rauschunterdrückung > Rauschprofil erstellen
- Wählen Sie die gesamte Audiospur
- Wenden Sie die Rauschunterdrückung mit Einstellungen um 12 dB Reduzierung, 6 Empfindlichkeit und 3 Frequenzglättung an
- Hören Sie sich das Ergebnis vorab an und passen Sie es an, wenn die Sprache verzerrt klingt
Audacity hat auch einen Hochpassfilter (Effekt > Filterkurve), der tieffrequentes Rumpeln von Wind- oder HLK-Systemen entfernen kann. Schneiden Sie Frequenzen unter 80-100 Hz für Sprachaufnahmen ab.
Adobe Podcast Enhance Speech (kostenlos, webbasiert)
Adobe bietet ein kostenloses Online-Tool, das KI verwendet, um Sprachaufnahmen zu verbessern. Laden Sie Ihre Audiodatei hoch, und das Tool versucht, die Stimme zu isolieren, Geräusche zu reduzieren und die Lautstärke zu normalisieren. Es funktioniert gut bei moderaten Geräuschpegeln und ist einfach genug für nicht-technische Benutzer. Die Einschränkung ist ein Dateigrößenlimit und die Tatsache, dass es die gesamte Datei ohne granulare Kontrolle verarbeitet.
iZotope RX
iZotope RX ist eine professionelle Audio-Reparatur-Suite, die in der Broadcast- und Film-Postproduktion verwendet wird. Sie bietet fortschrittliche Tools für Rauschunterdrückung, De-Reverb, De-Click, De-Hum und Dialog-Isolation. Es ist die leistungsfähigste Option, hat aber eine erhebliche Lernkurve und Kosten. Für regelmäßige Transkriptionsarbeit mit herausforderndem Audio lohnt sich die Investition.
Allgemeine Tipps zur Audio-Bereinigung
- Wenden Sie Rauschunterdrückung konservativ an. Aggressive Einstellungen entfernen Geräusche, führen aber Artefakte ein, die wie metallisches Wabern klingen. Diese Artefakte können ASR-Modelle genauso verwirren wie das ursprüngliche Geräusch.
- Verwenden Sie einen Hochpassfilter, um Rumpeln unter 80 Hz zu entfernen. Menschliche Sprache enthält unterhalb dieser Frequenz keine bedeutungsvollen Informationen.
- Normalisieren Sie den Audiopegel, sodass die Sprachspitzen bei etwa -3 dB bis -6 dB liegen. ASR-Modelle arbeiten besser mit konsistenten Lautstärkepegeln.
- Komprimieren Sie den Dynamikbereich nicht übermäßig. Etwas Kompression hilft bei geflüsterter oder geschrieener Sprache, aber starke Kompression hebt den Rauschpegel an.
KI-Transkriptionseinstellungen für verrauschtes Audio
Nachdem Sie Ihr Audio so gut wie möglich bereinigt haben, können die richtigen Transkriptionseinstellungen die Genauigkeit weiter verbessern.
Die Sprache angeben
Die meisten ASR-Systeme arbeiten besser, wenn Sie die gesprochene Sprache angeben, anstatt sich auf die automatische Erkennung zu verlassen. Die automatische Erkennung fügt einen zusätzlichen Inferenzschritt hinzu, der bei verrauschtem Audio fehlschlagen kann und möglicherweise das falsche Sprachmodell auswählt. Wenn Sie die Sprache kennen, stellen Sie sie explizit ein.
Die richtige Modellstufe wählen
Viele Transkriptionsdienste bieten mehrere Modellstufen an, und Stufen mit höherer Genauigkeit kommen mit Geräuschen in der Regel besser zurecht, weil sie größere Modelle mit mehr Kapazität zur Trennung von Sprache und Störungen verwenden. Wenn Ihr Anbieter eine solche Stufe hat, lohnt sich ein Test mit einer schwierigen Probe -- Sie können sie mit Ihrem eigenen Clip im Audio-zu-Text-Tool ausprobieren.
Sprecherdiarisierung sorgfältig einsetzen
Sprecherdiarisierung -- der Prozess der Identifizierung, wer was gesagt hat -- basiert auf der Erkennung akustischer Unterschiede zwischen Sprechern. Hintergrundgeräusche können diese Unterschiede maskieren und dazu führen, dass das Diarisierungsmodell einen Sprecher in mehrere Labels aufteilt oder verschiedene Sprecher zu einem zusammenführt. Wenn Ihr Audio verrauscht ist und die Diarisierungsergebnisse unzuverlässig erscheinen, erzielen Sie möglicherweise bessere Ergebnisse, wenn Sie ohne Diarisierung transkribieren und Sprecherkennzeichnungen manuell hinzufügen.
Lange Aufnahmen in Segmente aufteilen
Wenn nur Teile einer langen Aufnahme verrauscht sind, erwägen Sie, die Datei in Segmente aufzuteilen und sie separat zu transkribieren. Dies verhindert, dass ein verrauschter Abschnitt die Leistung des Modells bei den saubereren Teilen beeinträchtigt. Sie können auch verschiedene Rauschunterdrückungseinstellungen auf verschiedene Segmente basierend auf ihren Geräuscheigenschaften anwenden.
Tipps zur Nachbearbeitung von Transkriptionen
Selbst bei optimaler Audio-Vorbereitung und Transkriptionseinstellungen werden verrauschte Aufnahmen Transkripte produzieren, die manuelle Überprüfung benötigen. Hier sind Strategien für eine effiziente Bereinigung.
Zuerst auf Abschnitte mit hoher Fehlerrate konzentrieren
Hören Sie sich das Audio zusammen mit dem Transkript an und identifizieren Sie die Abschnitte, in denen die Transkription am stärksten von der tatsächlichen Sprache abweicht. Dies sind normalerweise die Momente mit dem höchsten Geräuschpegel. Priorisieren Sie die Korrektur dieser Abschnitte, anstatt das gesamte Transkript linear durchzulesen.
Zeitstempel zum Navigieren verwenden
Transkriptionstools, die Zeitstempel auf Wort- oder Segmentebene bereitstellen, ermöglichen es Ihnen, direkt zur relevanten Audioposition zu klicken. Dies macht es viel schneller, einzelne Wörter zu überprüfen und zu korrigieren, als manuell durch das Audio zu scrubben. Vocova stellt Zeitstempel für jedes Segment bereit, sodass Sie direkt zu jedem Punkt in der Aufnahme springen können.
Auf typische geräuschbedingte Fehler achten
Verrauschtes Audio erzeugt charakteristische Transkriptionsfehler:
- Phantomwörter, die eingefügt werden, wo das Modell Geräusche als Sprache interpretiert hat
- Ausgelassene Wörter, bei denen Geräusche das Sprachsignal vollständig maskiert haben
- Homophone und Beinahe-Treffer, bei denen das Modell ein ähnlich klingendes Wort gewählt hat, weil das Geräusch die unterscheidenden Laute verdeckt hat
- Verfälschte Eigennamen, da Namen und Fachbegriffe weniger aus dem Kontext vorhersagbar sind
Suchen und Ersetzen für systematische Fehler verwenden
Wenn das Modell einen bestimmten Begriff durchgängig in der Aufnahme falsch transkribiert (einen Personennamen, einen Firmennamen, ein technisches Wort), verwenden Sie Suchen und Ersetzen, um alle Vorkommen auf einmal zu korrigieren, anstatt sie einzeln zu beheben.
Einen zweiten Durchgang mit Übersetzung in Betracht ziehen
Wenn die ursprüngliche Transkription erhebliche Fehler aufweist und Sie auch eine übersetzte Version benötigen, ist es entscheidend, zuerst das Quelltranskript zu korrigieren. Übersetzungsmodelle verbreiten und verstärken manchmal Fehler aus dem Quelltext. Bereinigen Sie das Transkript vor dem Übersetzen.
Wenn verrauschtes Audio nicht mehr zu retten ist
Es gibt Situationen, in denen keine Menge an Rauschunterdrückung oder KI-Abstimmung ein nutzbares Transkript produzieren wird. Diese Fälle frühzeitig zu erkennen, spart Zeit und Frustration.
Anzeichen, dass das Audio möglicherweise nicht mehr zu retten ist:
- Sie können die Sprache selbst nicht verstehen, wenn Sie aufmerksam mit Kopfhörern zuhören
- Mehrere Sprecher reden gleichzeitig über längere Zeiträume ohne eine klar dominante Stimme
- Das SNR liegt unter 5 dB, was bedeutet, dass das Geräusch fast so laut oder lauter als die Sprache ist
- Starkes Clipping (Verzerrung durch zu hohen Aufnahmepegel) hat die Wellenform dauerhaft beschädigt
- Starker Nachhall lässt die Sprache klingen, als wäre sie in einem Tunnel oder Treppenhaus aufgenommen worden
Optionen, wenn KI-Transkription versagt
- Menschliche Transkription durch einen Fachmann, der kontextuelle Hinweise, Lippenlesen (wenn Video verfügbar ist) und Fachexpertise nutzen kann, um schwieriges Audio zu entschlüsseln. Dies ist langsamer und teurer, bewältigt aber Grenzfälle, die KI nicht kann. Für einen tieferen Vergleich siehe unseren Leitfaden zu KI vs menschliche Transkription.
- Erneut aufnehmen, wenn möglich. Wenn der Inhalt es erlaubt, ist die Planung einer neuen Aufnahmesitzung mit besserer Ausrüstung und Umgebung oft schneller, als zu versuchen, eine schwer beschädigte Aufnahme zu retten.
- Teiltranskription. Transkribieren Sie die Abschnitte mit akzeptabler Audioqualität und vermerken Sie die Lücken. Ein Transkript mit klar markierten [unverständlich]-Abschnitten ist nützlicher als eines voller falscher Vermutungen.
Häufig gestellte Fragen
Was ist der größte Faktor, der die Transkriptionsgenauigkeit beeinflusst?
Das Signal-Rausch-Verhältnis. Je lauter die Sprache im Verhältnis zum Hintergrundgeräusch ist, desto genauer kann jedes Transkriptionstool -- ob KI oder Mensch -- die Wörter identifizieren. Ein nah positioniertes Mikrofon in einem ruhigen Raum liefert die besten Ergebnisse. Die Abschnitte oben zu Aufnahmeeinstellungen, Mikrofonwahl und der Reduzierung von Hintergrundgeräuschen zeigen die schnellsten Wege, es zu erhöhen.
Können KI-Transkriptionstools Hintergrundmusik bewältigen?
Bedingt. Wenn die Musik leise ist und die Sprache klar, können die meisten modernen ASR-Modelle durch sie hindurch transkribieren. Laute Musik, besonders mit Gesang, verursacht erhebliche Genauigkeitsprobleme, weil das Modell die Zielsprache nicht zuverlässig vom Gesang unterscheiden kann. Instrumentale Hintergrundmusik bei niedriger Lautstärke ist weniger störend als Vokalmusik bei jeder Lautstärke.
Sollte ich Rauschunterdrückung verwenden, bevor ich Audio zum Transkribieren hochlade?
Nicht automatisch — testen Sie es zuerst. Es ist intuitiv, dass sauberer klingendes Audio besser transkribiert wird, aber moderne KI-Modelle wie Whisper wurden mit verrauschten Daten trainiert. Studien aus 2025-2026 fanden, dass Denoising- und Speech-Enhancement-Tools die Wortfehlerrate häufig erhöhten, obwohl das Audio für Menschen besser klang, weil die Verarbeitung Artefakte hinzufügt, auf die das Modell nicht trainiert wurde. Der zuverlässige Ansatz ist, eine kurze Probe roh und entrauscht zu transkribieren und die genauere Version zu behalten. Wenn Sie entrauschen, tun Sie es vorsichtig: aggressive Einstellungen erzeugen metallische Artefakte, die mehr schaden als helfen.
Verbessert die Angabe der Sprache die Genauigkeit bei verrauschtem Audio?
Ja. Wenn Sie die Sprache manuell festlegen, verwendet das ASR-Modell von Anfang an das richtige Vokabular und Sprachmodell. Bei verrauschtem Audio ist der automatische Erkennungsschritt eher anfällig dafür, die Sprache falsch zu identifizieren, was dann das falsche Modell für die gesamte Transkription anwendet. Geben Sie die Sprache immer an, wenn Sie sie kennen.
Wie stark beeinflusst die Audioqualität die Wortfehlerrate?
Erheblich, wobei die genauen Zahlen je nach Modell, Sprache und Geräuschtyp variieren. Behandeln Sie diese Werte daher als grobe Illustration, nicht als Messgarantie. Sauberes Studioaudio liegt mit modernen ASR-Modellen oft unter 5 % WER; moderate Büro- oder leichte Verkehrsgeräusche landen meist im niedrigen zweistelligen Bereich; ein volles Restaurant oder eine Baustelle kann über 30 % treiben. Die Beziehung ist nicht linear — die Genauigkeit fällt schnell, sobald das SNR unter etwa 15 dB sinkt. Wie stark schon die Clean-Audio-Basis zwischen Sprachen variiert, zeigt Transkriptionsgenauigkeit nach Sprache.
Ist es besser, verrauschtes Audio mit KI oder einem menschlichen Transkribierer zu transkribieren?
Für mäßig verrauschtes Audio sind KI-Tools normalerweise ausreichend und viel schneller. Für schwer degradiertes Audio, bei dem selbst aufmerksames Zuhören schwierig ist, wird ein erfahrener menschlicher Transkribierer typischerweise besser abschneiden als KI, weil er kontextuelles Denken, Fachwissen und visuelle Hinweise aus dem Video nutzen kann, um Lücken zu füllen. Der Vergleich zwischen KI und menschlicher Transkription hängt stark von den spezifischen Geräuschbedingungen und Ihren Genauigkeitsanforderungen ab.
Was ist das beste Audioformat für die Transkription?
WAV und FLAC sind am besten, weil sie verlustfrei sind und das volle Audiodetail erhalten. In der Praxis funktioniert auch MP3 mit 192 kbps oder höher gut. Die meisten KI-Transkriptionstools akzeptieren alle gängigen Formate, daher liegt die Priorität darin, mit hoher Bitrate aufzunehmen, statt sich um das spezifische Containerformat zu sorgen.
Lohnt sich der Kauf eines teuren Mikrofons für die Transkription?
Meistens nicht. Ein USB-Mikrofon für 50–100 $ in einem ruhigen Raum mit korrekter Platzierung erzeugt Audio in Transkriptionsqualität. Teure Mikrofone fügen stimmliche Fülle hinzu, die für Musik und Broadcast wichtiger ist als für die Genauigkeit von Speech-to-Text. Investieren Sie in Raumbehandlung und Mikrofonplatzierung, bevor Sie das Mikrofon selbst aufrüsten.
Quellen und weiterführende Lektüre
- Chondhekar et al., "When De-noising Hurts: A Systematic Study of Speech Enhancement Effects on Modern Medical ASR Systems" (arXiv, 2025) -- Speech Enhancement erhöhte bei Whisper-ähnlichen Modellen teils die Wortfehlerrate, obwohl das Audio sauberer klang
- Islam, Nahar & Hamid, "When Denoising Hinders: Revisiting Zero-Shot ASR with SAM-Audio and Whisper" (arXiv, 2026)
- Mu et al., "Performance evaluation of automatic speech recognition systems on integrated noise-network distorted speech", Frontiers in Signal Processing (2022) -- WER im Verhältnis zum SNR
- Hugging Face Audio Course -- preprocessing -- moderne ASR-Modelle erwarten 16-kHz-Audio
- Engineering ToolBox -- inverse-square law -- die Faustregel von etwa 6 dB Verlust pro Verdopplung der Entfernung
- National Center for Voice and Speech -- fundamental frequency -- Kontext für den Hochpass-Cutoff bei 80-100 Hz
