Come trascrivere audio rumoroso e ridurre gli errori da rumore di fondo (2026)
Il rumore di fondo è la principale causa di errori di trascrizione. Una guida pratica per registrare audio più pulito, scegliere le impostazioni giuste, capire quando denoising e riduzione del rumore aiutano o peggiorano prima della trascrizione, e gestire l'audio ormai irrecuperabile.
Il rumore di fondo è la causa principale di errori di trascrizione. Anche i modelli di riconoscimento vocale AI più avanzati hanno difficoltà quando il segnale audio compete con traffico, ronzio dell'aria condizionata, sovrapposizioni di voci o eco nella stanza. Una registrazione che in una stanza silenziosa si trascrive quasi perfettamente può degradare molto in un ambiente rumoroso, trasformando una trascrizione utile in qualcosa che richiede una correzione manuale estensiva.
La buona notizia è che la maggior parte dei problemi di audio rumoroso è prevenibile o risolvibile. Questa guida copre l'intera catena: come registrare audio più pulito in primo luogo, come elaborare registrazioni rumorose prima della trascrizione, come configurare le impostazioni di trascrizione per i migliori risultati e come gestire i casi in cui l'audio è genuinamente irrecuperabile.
Perché il rumore di fondo influisce sulla precisione della trascrizione
Per capire perché il rumore causa errori di trascrizione, è utile sapere come funziona il riconoscimento vocale automatico (ASR) a un livello base.
I modelli ASR convertono l'audio in testo analizzando le proprietà acustiche del suono, suddividendo il segnale in piccole finestre temporali e prevedendo quali parole o fonemi sono più probabili in ogni punto. Il modello è stato addestrato su migliaia di ore di parlato e ha appreso i pattern statistici che distinguono una parola dall'altra.
Il rumore di fondo disturba questo processo aggiungendo energia acustica che non corrisponde al parlato. Quando il ronzio di un ventilatore o il mormorio della folla occupa la stessa gamma di frequenze della voce dello speaker, il modello non riesce a separare nettamente i due segnali. Fa la sua migliore stima, ma queste stime diventano meno affidabili man mano che il livello di rumore aumenta.
Il termine tecnico per questo è rapporto segnale-rumore (SNR). L'SNR misura quanto più forte è il segnale vocale rispetto al rumore di fondo, espresso in decibel. Un SNR di 30 dB o superiore (il parlato è molto più forte del rumore) produce buoni risultati di trascrizione. Un SNR inferiore a 10 dB (il parlato è appena più forte del rumore) porta a una significativa perdita di precisione. La perdita è ripida, non graduale: il tasso di errore sale bruscamente man mano che l'SNR diminuisce, ed è per questo che anche un po' di distanza in più dal microfono, o una singola unità di aria condizionata accesa, può far crollare l'accuratezza.
La precisione della trascrizione viene tipicamente misurata con il tasso di errore per parola (WER). Un'intervista tranquilla e ben registrata può restare sotto il 5% WER; la stessa conversazione in un bar affollato può superare il 20-25%. I numeri esatti dipendono da modello, lingua e tipo di rumore — vedi accuratezza della trascrizione per lingua per capire quanto varia già la base con audio pulito — ma qui il divario è quasi interamente attribuibile al rumore.
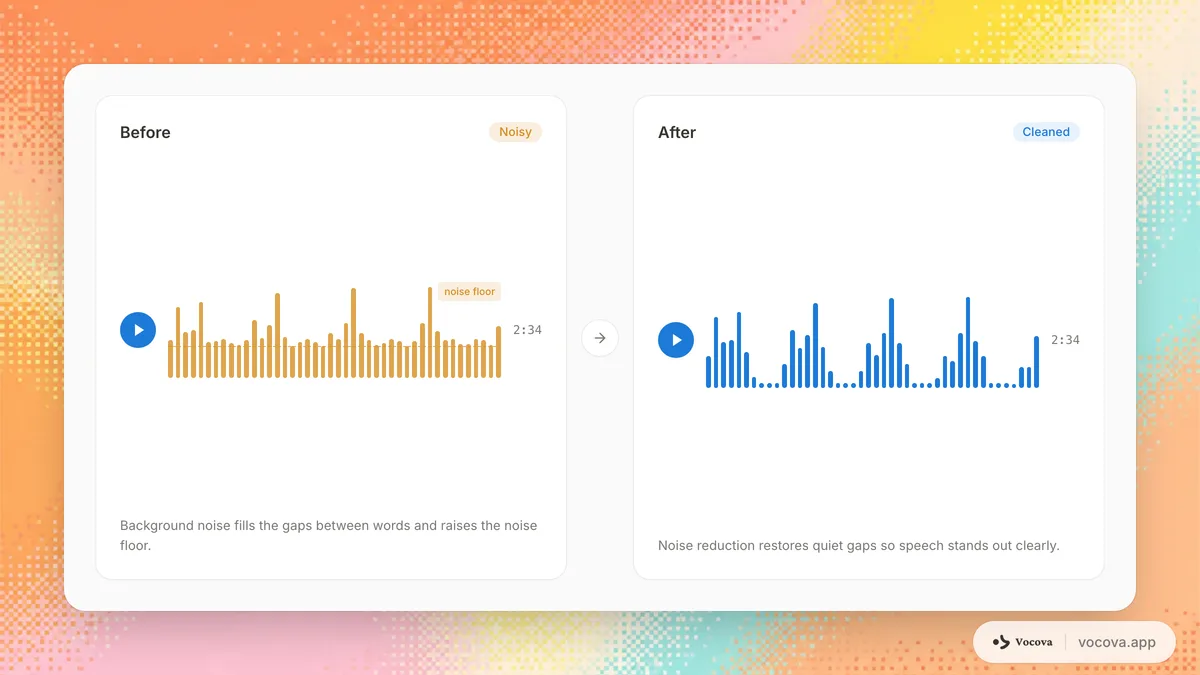
Tipi di rumore audio
Non tutti i rumori influiscono sulla trascrizione allo stesso modo. Capire il tipo di rumore nella registrazione aiuta a scegliere l'approccio giusto per gestirlo.
Rumore ambientale
Suoni di fondo costanti come aria condizionata, traffico, ventilatori o ronzio del frigorifero. Questo tipo di rumore è relativamente costante in volume e frequenza, il che lo rende il più facile da rimuovere con strumenti di riduzione del rumore. Tuttavia, se è abbastanza forte, degrada comunque la precisione della trascrizione.
Rumore elettronico
Fruscio, ronzio o sibilo introdotto dall'apparecchiatura di registrazione stessa. Le cause comuni includono microfoni di bassa qualità, loop di massa nei setup cablati, interferenze elettromagnetiche da dispositivi elettronici vicini e interfacce audio con un alto livello di rumore di base. Il rumore elettronico è solitamente costante e trattabile con la riduzione del rumore.
Riverbero
Eco causata dal suono che rimbalza sulle superfici dure in una stanza. Il riverbero "spalma" il segnale vocale nel tempo, rendendo più difficile per i modelli ASR identificare i confini delle parole. Uno speaker in un bagno piastrellato o in una sala conferenze vuota produrrà significativamente più riverbero di uno in un ufficio con moquette e arredato. Il riverbero è più difficile da rimuovere rispetto al rumore ambientale perché è una versione trasformata del segnale originale.
Sovrapposizione di voci e crosstalk
Più persone che parlano contemporaneamente. Questo è uno dei tipi di rumore più difficili per la trascrizione perché il segnale interferente è esso stesso parlato, e il modello ha difficoltà a separare i due speaker. Il crosstalk si verifica comunemente nelle riunioni, nei dibattiti e nelle interviste di gruppo.
Rumore del vento
Rombo a bassa frequenza causato dal movimento dell'aria sul microfono. Il rumore del vento è comune nelle registrazioni all'aperto e può mascherare completamente il parlato in caso di raffiche forti. Colpisce principalmente la fascia bassa dello spettro di frequenza e può spesso essere ridotto con un filtro passa-alto o un frangivento.
Rumore impulsivo
Suoni improvvisi e di breve durata come clic della tastiera, fruscio di carta, tosse o impatti da lavori edili. Sono brevi ma possono corrompere singole parole o frasi. I modelli ASR possono interpretare erroneamente un clic netto come un suono consonantico, inserendo parole fantasma nella trascrizione.
Consigli pre-registrazione per un audio più pulito
Il modo più efficace per ottenere trascrizioni accurate da ambienti rumorosi è catturare un audio migliore in partenza. Pochi minuti di preparazione prima di premere il tasto di registrazione possono risparmiare ore di pulizia successiva.
Scegliere il microfono giusto
La scelta del microfono ha un grande impatto sulla reiezione del rumore.
- Microfoni lavalier (da bavero) si fissano vicino alla bocca dello speaker, mantenendo il segnale vocale forte rispetto al rumore della stanza. Sono ideali per interviste e presentazioni.
- Microfoni direzionali (cardioidi o shotgun) catturano il suono principalmente dalla parte anteriore e rifiutano il suono dai lati e dal retro. Si puntano verso lo speaker e lontano dalle fonti di rumore.
- Microfoni omnidirezionali catturano il suono equamente da tutte le direzioni. Sono utili per le discussioni di gruppo ma captano più rumore ambientale.
- Microfoni con archetto posizionano la capsula vicino alla bocca e sono eccellenti per ambienti rumorosi, motivo per cui li usano i call center e i piloti.
Posizionare correttamente il microfono
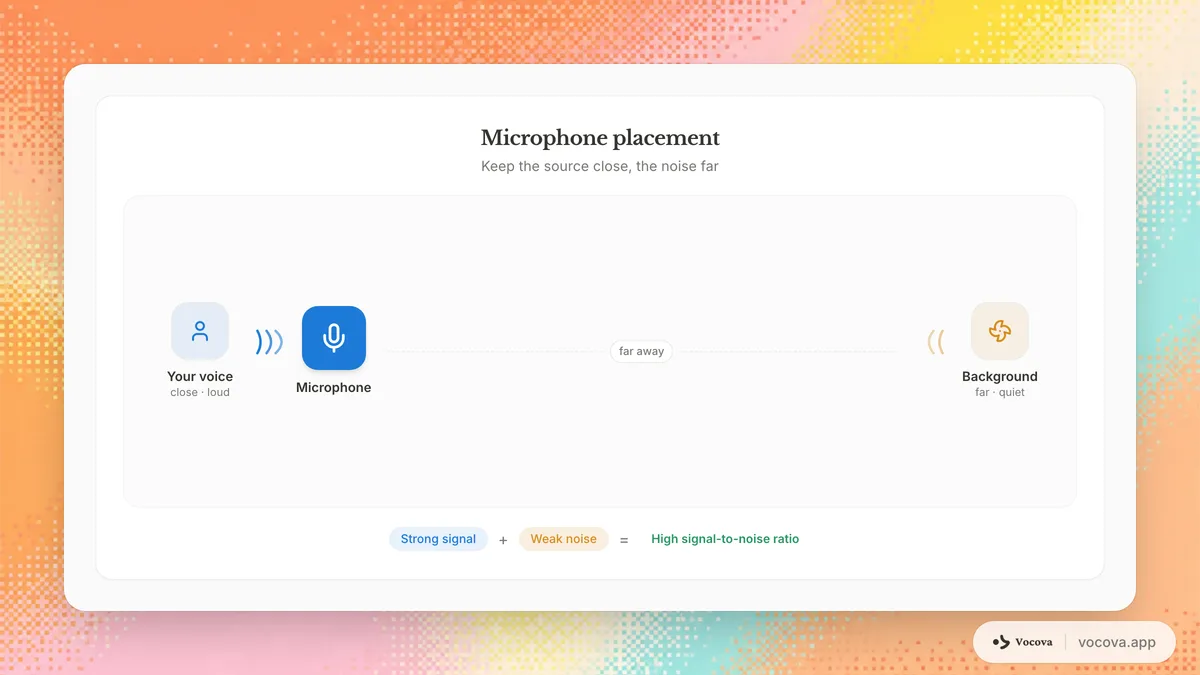
La distanza conta più di quanto la maggior parte delle persone pensi. Raddoppiare la distanza tra il microfono e lo speaker riduce il segnale vocale di circa 6 dB mentre il livello del rumore di fondo rimane lo stesso. Tenere il microfono il più vicino possibile allo speaker.
Per un microfono da bavero, fissarlo a 15-20 cm sotto il mento. Per un microfono da scrivania, posizionarlo a 15-30 cm dalla bocca dello speaker. Evitare di posizionare i microfoni vicino a fonti di rumore come ventole del computer, bocchette dell'aria o finestre che danno su una strada trafficata.
Trattare la stanza
Non serve uno studio professionale per ridurre significativamente rumore e riverbero.
- Chiudere finestre e porte per bloccare il rumore esterno
- Spegnere aria condizionata, ventilatori e dispositivi elettronici non necessari durante la registrazione
- Aggiungere materiali morbidi (tende, tappeti, mobili imbottiti) per ridurre l'eco
- Evitare stanze con superfici dure e parallele (pavimenti in piastrelle, pareti in vetro) che creano riverbero
- Se si registra in ufficio, scegliere una stanza più piccola con moquette piuttosto che una grande sala conferenze
Usare un frangivento all'aperto
Se si registra all'esterno, usare un frangivento in schiuma o una copertura pelosa (spesso chiamata "dead cat") sul microfono. Il rumore del vento è estremamente disturbante per la trascrizione e quasi impossibile da rimuovere completamente in post-produzione.
Registrare un campione di rumore di riferimento
Prima che lo speaker inizi a parlare, registrare da 10 a 15 secondi del solo rumore della stanza. Questa "impronta del rumore" è utile per gli strumenti di riduzione del rumore, che la usano per apprendere le caratteristiche del rumore e sottrarlo dalla registrazione.
Impostazioni di registrazione che influiscono sulla precisione della trascrizione
Oltre alla scelta del microfono e al trattamento della stanza, alcune impostazioni tecniche di registrazione determinano quanto dettaglio vocale arriva alla fase di trascrizione.
Frequenza di campionamento. La maggior parte dei modelli ASR moderni ricampiona tutto internamente a 16 kHz — la frequenza su cui sono stati addestrati — quindi una frequenza più alta non migliora l'accuratezza. Registra a 44,1 kHz o 48 kHz per compatibilità e archivio pulito, non per accuratezza di trascrizione; 16 kHz mono è già sufficiente per il modello. Oltre 48 kHz non c'è alcun beneficio per il riconoscimento vocale.
Profondità di bit. Registrare a 16 bit o 24 bit. La differenza conta soprattutto per i passaggi a basso volume: 24 bit cattura il parlato sommesso con meno rumore di quantizzazione, il che aiuta quando lo speaker è più lontano dal microfono.
Mono vs stereo. Per un singolo speaker, il mono va bene e produce file più piccoli. Per più speaker, registrare ogni voce su un canale separato migliora in modo misurabile la diarizzazione degli speaker, perché il modello può separare voci che arrivano su canali distinti e puliti.
Formato del file. WAV e FLAC sono senza perdita e ideali per la trascrizione. MP3 a 192 kbps o superiore è accettabile; AAC/M4A (usato dalla maggior parte dei telefoni) è leggermente migliore di MP3 allo stesso bitrate; OGG/Opus offre buona qualità a bitrate più bassi. Se lo spazio di archiviazione lo consente, archiviare in WAV o FLAC. La maggior parte degli strumenti, incluso Vocova, accetta tutti i formati comuni: la priorità è preservare il dettaglio nella registrazione stessa, non il contenitore.
Scegliere tipo di microfono e connessione
Le indicazioni sui microfoni sopra si concentrano sulla direzionalità per la reiezione del rumore. Due ulteriori scelte definiscono la qualità di base di qualsiasi registrazione.
- Condensatore vs dinamico. I microfoni a condensatore sono più sensibili e catturano più dettaglio vocale, il che aiuta in stanze silenziose e controllate, ma captano anche più rumore ambientale. I microfoni dinamici rifiutano per natura più rumore di fondo, rendendoli la scelta più sicura in spazi non trattati o rumorosi.
- USB vs XLR. I microfoni USB (per esempio il Rode NT-USB Mini o l'Audio-Technica AT2020USB+) includono un'interfaccia audio integrata e sono la scelta pragmatica per la maggior parte delle persone. I microfoni XLR necessitano di un'interfaccia separata ma offrono un livello di rumore di base più basso e maggiore controllo: ne vale la pena principalmente se si possiede già l'interfaccia.
Per la trascrizione, l'ambiente conta più del microfono specifico. Un microfono USB da 50–100 $ posizionato correttamente in una stanza silenziosa produce audio di qualità adatta alla trascrizione.
Consigli per scenari di registrazione specifici
- Riunioni: Usare un microfono da conferenza dedicato (come il Jabra Speak o l'Anker PowerConf) al centro del tavolo piuttosto che il microfono del portatile. Per le riunioni a distanza, registrare direttamente l'uscita audio del software di videoconferenza e chiedere ai partecipanti di indossare archetti per evitare l'eco.
- Interviste: Dare all'intervistatore e all'intervistato microfoni separati, idealmente microfoni lavalier wireless registrati su canali separati. Per le interviste telefoniche, registrare tramite software piuttosto che puntare un microfono verso un vivavoce.
- Lezioni: Un microfono lavalier sul relatore è il setup più affidabile. Far ripetere al relatore le domande del pubblico prima di rispondere, dato che l'audio del pubblico viene raramente catturato in modo pulito.
- Podcast: Dare a ogni conduttore e ospite il proprio microfono su una traccia separata. Per la registrazione a distanza, far registrare ogni partecipante localmente (con strumenti come Riverside.fm o Zencastr) e combinare le tracce successivamente per evitare gli artefatti di compressione delle videochiamate.
Errori comuni di registrazione che danneggiano la trascrizione
- Telefono in tasca o in borsa. Il tessuto attutisce le alte frequenze necessarie a distinguere le consonanti, e il movimento aggiunge fruscio. Posizionare il telefono su una superficie stabile rivolto verso lo speaker.
- Sedersi troppo lontano dal microfono. La distanza indebolisce il segnale vocale mentre il rumore di fondo rimane costante, quindi la registrazione finisce per essere dominata dal rumore. Stare vicini.
- Guadagno impostato troppo alto. Il clipping è una distorsione permanente che non può essere riparata. Impostare i livelli in modo che i picchi del parlato normale siano intorno a -12 dB / -6 dB.
- Guadagno impostato troppo basso. Registrare a volume troppo basso costringe ad amplificare successivamente, il che amplifica anche il livello di base del rumore.
- Registrare via Bluetooth. Il profilo Bluetooth vivavoce comprime pesantemente l'audio delle chiamate. Usare una connessione cablata per la registrazione ogni volta che è possibile.
- Nessuna registrazione di prova. Registrare e riascoltare 30 secondi prima della sessione vera. Individuare in anticipo eco, ronzio o rumore di manipolazione è molto più economico che scoprirlo dopo una registrazione di due ore.
Come pulire audio rumoroso prima della trascrizione
Se si ha già una registrazione rumorosa, gli strumenti di elaborazione audio possono migliorare la qualità del segnale prima di inviarlo a un servizio di trascrizione. I risultati non eguaglieranno una registrazione originale pulita, ma possono aiutare.
Un'avvertenza che sorprende: il denoising non aiuta sempre la trascrizione AI. I modelli di classe Whisper sono stati addestrati su molto audio imperfetto, e diversi studi del 2025-2026 (per esempio When De-noising Hurts, 2025, e When Denoising Hinders, 2026) hanno trovato che strumenti di speech enhancement e denoising possono in realtà aumentare il tasso di errore per parola — talvolta molto — anche quando l'audio suona più pulito a un essere umano, perché il processo introduce artefatti che il modello non ha mai visto in addestramento. La regola affidabile: processa un breve campione in entrambi i modi, trascrivi entrambe le versioni e tieni quella che vince. Sorprendentemente spesso, è l'audio grezzo. Gli strumenti sotto aiutano di più su rumori stabili e ben caratterizzati; aiutano meno, e possono peggiorare, su interferenze simili al parlato e riverbero.
Audacity (gratuito, open source)
Audacity è un editor audio gratuito con uno strumento di riduzione del rumore integrato.
- Selezionare una porzione dell'audio che contiene solo rumore (senza parlato)
- Andare su Effetti > Riduzione rumore > Acquisisci profilo rumore
- Selezionare l'intera traccia audio
- Applicare la Riduzione rumore con impostazioni intorno a 12 dB di riduzione, 6 di sensibilità e 3 di smoothing in frequenza
- Anteprima del risultato e regolazione se il parlato suona distorto
Audacity ha anche un filtro passa-alto (Effetti > Curva filtro) che può rimuovere il rombo a bassa frequenza dal vento o dai sistemi HVAC. Tagliare le frequenze sotto 80-100 Hz per le registrazioni di voce parlata.
Adobe Podcast Enhance Speech (gratuito, basato sul web)
Adobe offre uno strumento online gratuito che usa l'AI per migliorare le registrazioni vocali. Si carica il file audio e lo strumento tenta di isolare la voce, ridurre il rumore e normalizzare il volume. Funziona bene per livelli di rumore moderati ed è abbastanza semplice per utenti non tecnici. La limitazione è un tetto sulla dimensione del file e il fatto che elabora l'intero file senza controllo granulare.
iZotope RX
iZotope RX è una suite professionale di riparazione audio utilizzata nella post-produzione broadcast e cinematografica. Offre strumenti avanzati per riduzione del rumore, de-riverbero, de-click, de-hum e isolamento del dialogo. È l'opzione più capace ma comporta una curva di apprendimento significativa e un costo. Per il lavoro di trascrizione regolare con audio difficile, vale l'investimento.
Consigli generali per la pulizia audio
- Applicare la riduzione del rumore in modo conservativo. Impostazioni aggressive rimuovono il rumore ma introducono artefatti che suonano come un warbling metallico. Questi artefatti possono confondere i modelli ASR tanto quanto il rumore originale.
- Usare un filtro passa-alto per rimuovere il rombo sotto gli 80 Hz. Il parlato umano non contiene informazioni significative sotto questa frequenza.
- Normalizzare il livello audio in modo che i picchi del parlato siano intorno a -3 dB a -6 dB. I modelli ASR funzionano meglio con livelli di volume consistenti.
- Non comprimere eccessivamente la gamma dinamica. Un po' di compressione aiuta con il parlato sussurrato o urlato, ma una compressione pesante alza il livello di base del rumore.
Impostazioni di trascrizione AI per audio rumoroso
Una volta pulito l'audio il più possibile, le impostazioni di trascrizione corrette possono migliorare ulteriormente la precisione.
Specificare la lingua
La maggior parte dei sistemi ASR funziona meglio quando si specifica la lingua parlata piuttosto che affidarsi al rilevamento automatico. Il rilevamento automatico aggiunge un passo di inferenza extra che può andare storto con audio rumoroso, potenzialmente selezionando il modello linguistico sbagliato per l'intera trascrizione. Se si conosce la lingua, impostarla esplicitamente.
Scegliere il livello di modello giusto
Molti servizi di trascrizione offrono più livelli di modello, e i livelli a maggiore precisione generalmente gestiscono meglio il rumore perché usano modelli più grandi con maggiore capacità di separare il parlato dall'interferenza. Se il tuo provider ne offre uno, vale la pena provarlo su un campione difficile: puoi testarlo con una tua clip tramite lo strumento audio-to-text.
Usare la diarizzazione degli speaker con cautela
La diarizzazione degli speaker, il processo di identificazione di chi ha detto cosa, si basa sulla rilevazione delle differenze acustiche tra gli speaker. Il rumore di fondo può mascherare queste differenze, causando al modello di diarizzazione la suddivisione di uno speaker in più etichette o la fusione di speaker diversi in uno solo. Se l'audio è rumoroso e i risultati della diarizzazione appaiono inaffidabili, si potrebbero ottenere risultati migliori trascrivendo senza diarizzazione e aggiungendo le etichette degli speaker manualmente.
Suddividere registrazioni lunghe in segmenti
Se solo alcune porzioni di una registrazione lunga sono rumorose, considerare di dividere il file in segmenti e trascriverli separatamente. Questo previene che una sezione rumorosa influisca sulle prestazioni del modello sulle porzioni più pulite. È anche possibile applicare impostazioni di riduzione del rumore diverse a segmenti diversi in base alle loro caratteristiche di rumore.
Consigli per la pulizia post-trascrizione
Anche con una preparazione audio ottimale e le migliori impostazioni di trascrizione, le registrazioni rumorose produrranno trascrizioni che necessitano di revisione manuale. Ecco le strategie per una pulizia efficiente.
Concentrarsi prima sulle sezioni con più errori
Ascoltare l'audio insieme alla trascrizione e identificare le sezioni dove la trascrizione diverge maggiormente dal parlato effettivo. Questi sono solitamente i momenti con i livelli di rumore più alti. Dare la priorità alla correzione di queste sezioni piuttosto che leggere l'intera trascrizione linearmente.
Usare i timestamp per navigare
Gli strumenti di trascrizione che forniscono timestamp a livello di parola o di segmento permettono di cliccare direttamente sulla posizione audio rilevante. Questo rende molto più veloce verificare e correggere singole parole rispetto allo scorrimento manuale dell'audio. Vocova fornisce timestamp per ogni segmento, così è possibile saltare direttamente a qualsiasi punto della registrazione.
Prestare attenzione agli errori comuni indotti dal rumore
L'audio rumoroso produce errori di trascrizione caratteristici:
- Parole fantasma inserite dove il modello ha interpretato il rumore come parlato
- Parole mancanti dove il rumore ha mascherato completamente il segnale vocale
- Omofoni e quasi-corrispondenze dove il modello ha scelto una parola dal suono simile perché il rumore ha oscurato i suoni distintivi
- Nomi propri incomprensibili poiché nomi e termini tecnici sono meno prevedibili dal contesto
Usare cerca e sostituisci per errori sistematici
Se il modello trascrive costantemente un termine specifico in modo errato nell'intera registrazione (il nome di una persona, un nome aziendale, una parola tecnica), usare cerca e sostituisci per correggere tutte le istanze contemporaneamente piuttosto che correggerle individualmente.
Considerare un secondo passaggio con la traduzione
Se la trascrizione originale ha errori significativi e si necessita anche di una versione tradotta, correggere prima la trascrizione di partenza è fondamentale. I modelli di traduzione propagano e talvolta amplificano gli errori dal testo di partenza. Pulire la trascrizione prima di tradurre.
Quando l'audio rumoroso è irrecuperabile
Ci sono situazioni in cui nessuna riduzione del rumore o ottimizzazione AI produrrà una trascrizione utilizzabile. Riconoscere questi casi presto fa risparmiare tempo e frustrazione.
Segnali che l'audio potrebbe essere irrecuperabile:
- Non è possibile comprendere il parlato nemmeno ascoltando attentamente con le cuffie
- Più speaker parlano simultaneamente per periodi prolungati senza una voce dominante chiara
- L'SNR è inferiore a 5 dB, il che significa che il rumore è quasi forte quanto o più forte del parlato
- Un clipping severo (distorsione da un livello di registrazione troppo alto) ha corrotto permanentemente la forma d'onda
- Un riverbero pesante fa sembrare il parlato come se fosse stato registrato in un tunnel o in una tromba delle scale
Opzioni quando la trascrizione AI fallisce
- Trascrizione umana da un professionista che può usare indizi contestuali, lettura labiale (se il video è disponibile) e competenze tematiche per decodificare audio difficile. Questo è più lento e costoso ma gestisce casi limite che l'AI non può. Per un confronto più approfondito, consulti la nostra guida sulla trascrizione AI vs umana.
- Ri-registrare se possibile. Se il contenuto lo permette, programmare una nuova sessione di registrazione con attrezzature e ambiente migliori è spesso più veloce che cercare di recuperare una registrazione gravemente degradata.
- Trascrizione parziale. Trascrivere le sezioni con qualità audio accettabile e annotare le lacune. Una trascrizione con sezioni chiaramente contrassegnate come [incomprensibile] è più utile di una piena di ipotesi errate.
Domande frequenti
Qual è il fattore più importante che influisce sulla precisione della trascrizione?
Il rapporto segnale-rumore. Più forte è il parlato rispetto al rumore di fondo, più accuratamente qualsiasi strumento di trascrizione, sia AI che umano, può identificare le parole. Un microfono posizionato vicino in una stanza silenziosa produce i migliori risultati. Consulti le sezioni precedenti sulle impostazioni di registrazione, la scelta del microfono e la riduzione del rumore di fondo per i modi più rapidi di aumentarlo.
Gli strumenti di trascrizione AI possono gestire la musica di sottofondo?
Moderatamente. Se la musica è bassa e il parlato è chiaro, la maggior parte dei modelli ASR moderni può trascrivere attraverso di essa. Musica alta, specialmente con voce cantata, causa problemi di precisione significativi perché il modello non può distinguere in modo affidabile il parlato target dal canto. La musica strumentale di sottofondo a basso volume è meno disturbante della musica con voce a qualsiasi volume.
Dovrei usare la riduzione del rumore prima di caricare l'audio per la trascrizione?
Non automaticamente: testalo prima. È intuitivo pensare che un audio più pulito si trascriva meglio, ma i modelli AI moderni come Whisper sono stati addestrati su dati rumorosi, e studi del 2025-2026 hanno trovato che denoising e speech enhancement spesso aumentano il tasso di errore per parola anche quando l'audio suona meglio a un umano, perché il processo aggiunge artefatti non presenti nell'addestramento. L'approccio affidabile è trascrivere un breve campione sia grezzo sia denoised e tenere quello più accurato. Se applichi denoising, mantienilo leggero: impostazioni aggressive introducono artefatti metallici che fanno più male che bene.
Specificare la lingua migliora la precisione per audio rumoroso?
Sì. Quando si imposta manualmente la lingua, il modello ASR utilizza il vocabolario e il modello linguistico corretti fin dall'inizio. Con audio rumoroso, il passo di rilevamento automatico ha più probabilità di identificare erroneamente la lingua, il che poi applica il modello sbagliato per l'intera trascrizione. Specificare sempre la lingua quando la si conosce.
Quanto influisce la qualità audio sul tasso di errore per parola?
In modo sostanziale, anche se i numeri esatti variano per modello, lingua e tipo di rumore: trattali come esempi approssimativi, non garanzie misurate. Audio pulito da studio spesso resta sotto il 5% WER con ASR moderno; rumore moderato da ufficio o traffico leggero tende a finire nelle basse doppie cifre; un ristorante affollato o un cantiere può superare il 30%. La relazione non è lineare: la precisione degrada rapidamente quando l'SNR scende sotto circa 15 dB. Per quanto varia già la base con audio pulito tra le lingue, vedi accuratezza della trascrizione per lingua.
È meglio trascrivere audio rumoroso con l'AI o con un trascrittore umano?
Per audio moderatamente rumoroso, gli strumenti AI sono solitamente sufficienti e molto più veloci. Per audio gravemente degradato dove anche un ascolto attento è difficile, un trascrittore umano esperto supererà tipicamente l'AI perché può usare il ragionamento contestuale, la conoscenza della materia e indizi visivi dal video per colmare le lacune. Il confronto tra trascrizione AI e umana dipende fortemente dalle specifiche condizioni di rumore e dai requisiti di precisione.
Qual è il formato audio migliore per la trascrizione?
WAV e FLAC sono i migliori perché sono senza perdita e preservano l'intero dettaglio audio. In pratica, anche MP3 a 192 kbps o superiore funziona bene. La maggior parte degli strumenti di trascrizione AI accetta tutti i formati comuni, quindi la priorità è registrare a un bitrate elevato piuttosto che preoccuparsi del formato del contenitore specifico.
Vale la pena acquistare un microfono costoso per la trascrizione?
Di solito no. Un microfono USB da 50–100 $ in una stanza silenziosa con il posizionamento corretto produce audio di qualità adatta alla trascrizione. I microfoni costosi aggiungono una ricchezza vocale che conta più per la musica e il broadcast che per la precisione dello speech-to-text. Investire nel trattamento della stanza e nel posizionamento del microfono prima di aggiornare il microfono stesso.
Fonti e approfondimenti
- Chondhekar et al., "When De-noising Hurts: A Systematic Study of Speech Enhancement Effects on Modern Medical ASR Systems" (arXiv, 2025) -- il miglioramento del parlato ha aumentato il tasso di errore delle parole su modelli simili a Whisper, anche quando l'audio sembrava più pulito
- Islam, Nahar & Hamid, "When Denoising Hinders: Revisiting Zero-Shot ASR with SAM-Audio and Whisper" (arXiv, 2026)
- Mu et al., "Performance evaluation of automatic speech recognition systems on integrated noise-network distorted speech", Frontiers in Signal Processing (2022) -- WER rispetto a SNR
- Hugging Face Audio Course -- preprocessing -- i modelli ASR moderni si aspettano audio a 16 kHz
- Engineering ToolBox -- inverse-square law -- la regola pratica di circa 6 dB persi a ogni raddoppio della distanza
- National Center for Voice and Speech -- fundamental frequency -- contesto per il taglio passa-alto a 80-100 Hz
