ノイズの多い音声を文字起こしし、背景ノイズ由来の誤りを減らす方法(2026年)
背景ノイズは文字起こしエラーの最大要因です。よりクリーンに録音する方法、重要な設定、文字起こし前にノイズ除去すべき場合とすべきでない場合、救いようのない音声への対処を実践的に解説します。
背景ノイズは文字起こしエラーの最大の原因です。最も高度なAI音声認識モデルでさえ、音声信号が交通騒音、空調のハム音、クロストーク、部屋のエコーと競合する場合は苦戦します。静かな部屋ではほぼ完璧に文字起こしできる録音でも、ノイズの多い環境では急激に劣化し、使える文字起こしが大幅な手動修正を必要とするものに変わってしまいます。
良いニュースは、ほとんどのノイズの多い音声の問題は予防可能か修正可能だということです。このガイドでは、最初からよりクリーンな音声を録音する方法、文字起こし前にノイズの多い録音を処理する方法、最良の結果を得るための文字起こし設定の構成方法、そして音声が本当に救いようのない場合の対処方法の全チェーンをカバーします。
背景ノイズが文字起こし精度に影響する理由
ノイズが文字起こしエラーを引き起こす理由を理解するには、自動音声認識(ASR)が基本的にどのように機能するかを知ることが役立ちます。
ASRモデルは、音声の音響特性を分析し、信号を小さな時間窓に分割し、各ポイントでどの単語や音素が最も可能性が高いかを予測することで、音声をテキストに変換します。モデルは数千時間の音声で訓練され、ある単語を別の単語と区別する統計パターンを学習しています。
背景ノイズは、音声に対応しない音響エネルギーを追加することでこのプロセスを妨げます。ファンのドローン音やざわめきが話者の声と同じ周波数範囲を占める場合、モデルは2つの信号をきれいに分離できません。最善の推測を行いますが、ノイズレベルが増加するにつれて推測の信頼性は低下します。
この技術的な用語は**信号対雑音比(SNR)**です。SNRは、音声信号が背景ノイズに比べてどれだけ大きいかを、デシベルで表したものです。SNRが30dB以上(音声がノイズよりもはるかに大きい)であれば、良好な文字起こし結果が得られます。SNRが10dB未満(音声がノイズをほとんど上回っていない)の場合、精度が大幅に低下します。この低下は緩やかではなく急激です。SNRが下がるにつれてエラー率は急激に上昇します。そのため、マイクとの距離が少し伸びるだけでも、空調が1台動いているだけでも、精度は崩れます。
文字起こし精度は通常単語誤り率(WER)で測定されます。静かで適切に録音されたインタビューならWERは5%未満に収まることがありますが、同じ会話をにぎやかなカフェで録音すると20〜25%を超えることがあります。正確な数値はモデル、言語、ノイズの種類によって変わります。クリーン音声の基準値そのものが言語によってどれほど違うかは、言語別の文字起こし精度をご覧ください。ただし、この場面での差はほぼノイズに起因します。
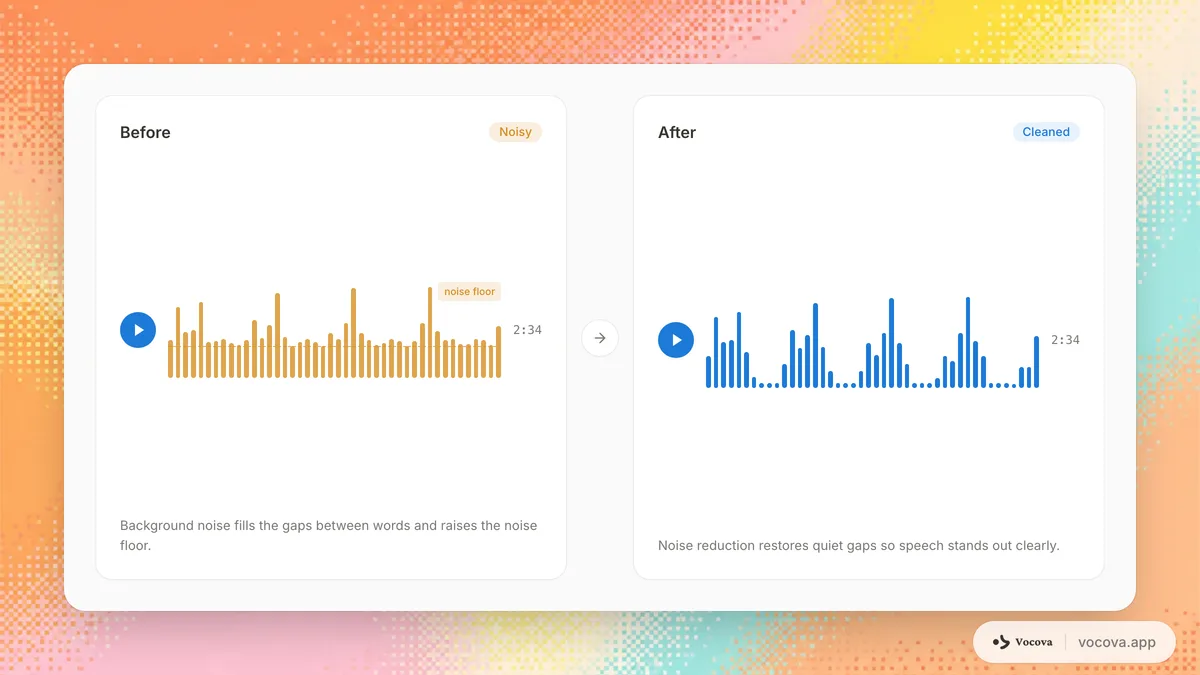
音声ノイズの種類
すべてのノイズが文字起こしに等しく影響するわけではありません。録音のノイズの種類を理解することで、対処のための適切なアプローチを選ぶ助けになります。
環境ノイズ
空調、交通、ファン、冷蔵庫のハム音などの一定の背景音。このタイプのノイズは音量と周波数が比較的一定であり、ノイズ除去ツールで除去するのが最も簡単です。ただし、十分に大きければ、文字起こし精度を低下させます。
電子ノイズ
録音機器自体によって導入されるヒス音、バズ音、ハム音。一般的な原因は、低品質のマイク、有線セットアップのグラウンドループ、近くの電子機器からの電磁干渉、ノイズフロアの高いオーディオインターフェースです。電子ノイズは通常一定であり、ノイズ除去で処理できます。
残響
硬い表面で音が反射することで生じるエコー。残響は時間的に音声信号をぼかし、ASRモデルが単語の境界を識別するのを困難にします。タイル張りのバスルームや空の会議室にいる話者は、カーペット敷きで家具のあるオフィスにいる話者よりも大幅に多くの残響を生じます。残響は元の信号の変形版であるため、環境ノイズよりも除去が困難です。
クロストークと重複音声
複数の人が同時に話す状態。これは文字起こしにとって最も困難なノイズタイプの一つです。干渉信号自体が音声であるため、モデルが2人の話者を分離するのが困難です。クロストークは会議、パネルディスカッション、グループインタビューでよく発生します。
風ノイズ
マイクに当たる空気の動きによる低周波のゴロゴロ音。風ノイズは屋外での録音でよく見られ、強い突風では音声を完全にマスクする可能性があります。主に低周波帯域に影響し、ハイパスフィルターやウィンドスクリーンで軽減できることが多いです。
衝撃ノイズ
キーボードのクリック、紙のシャッフル、咳、建設工事の衝撃などの突発的で短い音。これらは短いですが、個々の単語やフレーズを破壊する可能性があります。ASRモデルは鋭いクリック音を子音として解釈し、文字起こしにファントムワードを挿入する可能性があります。
録音前のよりクリーンな音声のためのヒント
ノイズの多い環境から正確な文字起こしを得る最も効果的な方法は、最初からより良い音声をキャプチャすることです。録音ボタンを押す前の数分の準備で、後のクリーンアップに何時間も節約できます。
適切なマイクを選ぶ
マイクの選択はノイズ除去に大きな影響を与えます。
- ラベリア(ピンマイク) は話者の口の近くにクリップで留め、部屋のノイズに対して音声信号を強く保ちます。インタビューやプレゼンテーションに最適です。
- 指向性(カーディオイドまたはショットガン)マイク は主に前方からの音をキャプチャし、側面や背後からの音を除去します。話者に向け、ノイズ源から離して向けてください。
- 全指向性マイク はすべての方向から均等に音をキャプチャします。グループディスカッションには便利ですが、より多くの環境ノイズを拾います。
- ヘッドセットマイク はカプセルを口の近くに配置し、ノイズの多い環境に優れています。コールセンターやパイロットが使用しているのはこのためです。
マイクを正しく配置する
距離はほとんどの人が認識している以上に重要です。マイクと話者の間の距離を2倍にすると、音声信号は約6dB低下しますが、背景ノイズレベルは同じままです。マイクを話者にできるだけ近づけてください。
ピンマイクの場合、あごの15〜20cm下にクリップで留めます。デスクマイクの場合、話者の口から15〜30cmの位置に配置します。コンピュータのファン、エアベント、交通量の多い道路に面した窓などのノイズ源の近くにマイクを置かないようにしてください。
部屋を処理する
プロのスタジオがなくても、ノイズと残響を大幅に軽減できます。
- 外部ノイズを遮断するために窓とドアを閉める
- 録音中は空調、ファン、不要な電子機器を切る
- エコーを軽減するために柔らかい素材(カーテン、ラグ、クッションの効いた家具)を追加する
- 残響を生じる硬い平行面(タイル床、ガラス壁)のある部屋を避ける
- オフィスで録音する場合、大きな会議室よりも小さくカーペット敷きの部屋を選ぶ
屋外ではウィンドスクリーンを使用する
屋外で録音する場合、マイクにフォームウィンドスクリーンまたは毛皮状のウィンドカバー(通称「デッドキャット」)を使用してください。風ノイズは文字起こしに非常に破壊的で、後処理で完全に除去するのはほぼ不可能です。
基準ノイズサンプルを録音する
話者が話し始める前に、部屋のノイズだけを10〜15秒録音してください。この「ノイズプリント」はノイズ除去ツールに有用で、ノイズの特性を学習して録音からそれを差し引くために使用されます。
文字起こし精度に影響する録音設定
マイクの選択や部屋の処理に加えて、いくつかの技術的な録音設定が、どれだけの声のディテールが文字起こしの段階まで生き残るかを左右します。
サンプルレート。 最新のASRモデルの多くは、内部で音声を16kHzにリサンプリングします。これはモデルが訓練されたレートです。そのため、より高いサンプルレートにしても精度は上がりません。44.1kHzまたは48kHzで録音するのは、互換性ときれいなアーカイブのためであり、文字起こし精度のためではありません。モデルには16kHzモノラルでも十分です。48kHzを超えても音声認識上のメリットはありません。
ビット深度。 16ビットまたは24ビットで録音してください。違いが最も重要になるのは静かな箇所です。24ビットは量子化ノイズを抑えて柔らかい音声をキャプチャするため、話者がマイクから遠い場合に役立ちます。
モノラル vs ステレオ。 1人の話者の場合、モノラルで問題なく、ファイルサイズも小さくなります。複数の話者の場合、各声を別々のチャンネルに録音すると話者ダイアライゼーションが測定可能なほど改善します。モデルが、別々のクリーンなチャンネルに届く声を分離できるためです。
ファイル形式。 WAVとFLACはロスレスで、文字起こしに理想的です。192kbps以上のMP3も許容できます。AAC/M4A(ほとんどのスマートフォンで使用)は同じビットレートのMP3よりもわずかに優れており、OGG/Opusはより低いビットレートで良好な品質を提供します。ストレージに余裕があれば、WAVまたはFLACでアーカイブしてください。Vocovaを含むほとんどのツールは一般的な形式をすべて受け付けます。優先すべきはコンテナではなく、録音自体のディテールを保つことです。
マイクの種類と接続方式を選ぶ
上記のマイクのガイダンスは、ノイズ除去のための指向性に焦点を当てています。さらに2つの選択が、あらゆる録音のベースライン品質を決めます。
- コンデンサー vs ダイナミック。 コンデンサーマイクはより高感度で、より多くの声のディテールをキャプチャするため、静かで管理された部屋で役立ちます。ただし、より多くの環境ノイズも拾います。ダイナミックマイクは設計上、より多くの背景ノイズを除去するため、処理されていない部屋やノイズの多い空間ではより安全な選択肢です。
- USB vs XLR。 USBマイク(例えばRode NT-USB MiniやAudio-Technica AT2020USB+)は組み込みのオーディオインターフェースを備えており、ほとんどの人にとって実用的な選択肢です。XLRマイクは別途インターフェースが必要ですが、より低いノイズフロアとより多くの制御を提供します。これはすでにインターフェースを所有している場合に主に価値があります。
文字起こしにとっては、特定のマイクよりも環境の方が重要です。50〜100ドルのUSBマイクを静かな部屋に正しく配置すれば、文字起こしに適した音声が得られます。
特定の録音シナリオ向けのヒント
- 会議: ノートパソコンのマイクではなく、テーブルの中央に専用の会議用マイク(JabraのSpeakやAnkerのPowerConfなど)を使用してください。リモート会議では、会議ソフトウェアの音声出力を直接録音し、エコーを避けるために参加者にヘッドセットの着用を依頼してください。
- インタビュー: インタビュアーとインタビュー対象者に別々のマイクを用意してください。理想的には別々のチャンネルに録音されるワイヤレスのラベリアです。電話インタビューの場合、スピーカーフォンにマイクを向けるのではなく、ソフトウェア経由で録音してください。
- 講義: プレゼンターにラベリアマイクを付けるのが最も信頼できるセットアップです。聴衆の音声がクリーンにキャプチャされることはまれなので、プレゼンターには回答する前に聴衆の質問を復唱してもらってください。
- ポッドキャスト: 各ホストとゲストに、それぞれ別のトラックで専用のマイクを用意してください。リモート録音の場合、ビデオ通話の圧縮アーティファクトを避けるために、各参加者にローカルで録音してもらい(Riverside.fmやZencastrなどのツールを使用)、後でトラックを結合してください。
文字起こしを損なうよくある録音ミス
- ポケットやバッグに入れたスマートフォン。 布地は子音の区別に必要な高周波をこもらせ、動きがガサガサというノイズを追加します。スマートフォンは話者の方に向けて安定した面に置いてください。
- マイクから遠すぎる位置に座る。 距離は音声信号を弱める一方で背景ノイズは一定のままなので、録音はノイズに支配されてしまいます。近くにいてください。
- ゲインが高すぎる。 クリッピングは修復できない永久的な歪みです。通常の音声のピークが-12dB〜-6dB付近になるようにレベルを設定してください。
- ゲインが低すぎる。 静かすぎる録音は後で増幅を強いられ、ノイズフロアも増幅されます。
- Bluetooth経由での録音。 ハンズフリーBluetoothプロファイルは通話音声を大きく圧縮します。録音にはできる限り有線接続を使用してください。
- テスト録音をしない。 本番セッションの前に30秒録音して再生してください。部屋のエコー、ハム音、取り扱いノイズを事前に発見する方が、2時間の録音後に気づくよりもはるかに安上がりです。
文字起こし前のノイズの多い音声のクリーンアップ方法
すでにノイズの多い録音がある場合、音声処理ツールを使って文字起こしサービスに送信する前に信号品質を改善できます。クリーンな元の録音には匹敵しませんが、役に立つ場合があります。
意外に思われがちな注意点:ノイズ除去はAI文字起こしに必ずしも有利ではありません。 Whisper系モデルは多くの不完全な音声で訓練されており、2025〜2026年の複数の研究(例えば When De-noising Hurts(2025年)や When Denoising Hinders(2026年))では、音声強調やノイズ除去ツールが、人間には音がきれいに聞こえる場合でも、単語誤り率を実際には上げることがあると報告されています。処理によって、モデルが訓練時に見ていないアーティファクトが入るためです。信頼できるルールは、短いサンプルを未処理版と処理版の両方で文字起こしし、勝った方を使うことです。意外なほど多くの場合、勝つのは生音声です。下のツールは、安定して特徴がはっきりしたノイズには最も効きますが、音声に似た干渉や残響には効きにくく、悪化させることもあります。
Audacity(無料、オープンソース)
Audacityは組み込みのノイズ除去ツールを備えた無料の音声エディターです。
- ノイズのみ(音声なし)を含む音声の部分を選択
- エフェクト > ノイズ除去 > ノイズプロファイルの取得 へ進む
- 音声トラック全体を選択
- 約12dBの除去、6の感度、3の周波数スムージングの設定でノイズ除去を適用
- 結果をプレビューし、音声が歪む場合は調整
Audacityにはハイパスフィルター(エフェクト > フィルターカーブ)もあり、風や空調システムからの低周波のゴロゴロ音を除去できます。音声録音では80〜100Hz以下の周波数をカットしてください。
Adobe Podcast Enhance Speech(無料、Webベース)
Adobeは、AI を使用して音声録音を強化する無料のオンラインツールを提供しています。音声ファイルをアップロードすると、ツールは音声を分離し、ノイズを軽減し、音量を正規化しようとします。適度なノイズレベルではうまく機能し、技術的でないユーザーにも十分にシンプルです。制限はファイルサイズの上限と、きめ細かい制御なしにファイル全体を処理することです。
iZotope RX
iZotope RXは、放送やフィルムのポストプロダクションで使用されるプロフェッショナルな音声修復スイートです。ノイズ除去、ディリバーブ、ディクリック、ディハム、ダイアログ分離のための高度なツールを提供しています。最も能力の高いオプションですが、大きな学習曲線とコストが伴います。困難な音声を扱う定期的な文字起こし作業には、投資する価値があります。
音声クリーンアップの一般的なヒント
- ノイズ除去は控えめに適用する。 攻撃的な設定はノイズを除去しますが、金属的なウォーブリングのようなアーティファクトを導入します。これらのアーティファクトは元のノイズと同じくらいASRモデルを混乱させる可能性があります。
- ハイパスフィルターを使用 して80Hz以下のゴロゴロ音を除去する。人間の音声はこの周波数以下に意味のある情報を含んでいません。
- 音声レベルを正規化 して、音声のピークが約-3dBから-6dBになるようにする。ASRモデルは一貫した音量レベルでより良く機能します。
- ダイナミックレンジを過度に圧縮しない。 ある程度の圧縮はささやきや叫びの音声に役立ちますが、強い圧縮はノイズフロアを上げます。
ノイズの多い音声のAI文字起こし設定
音声をできる限りクリーンアップしたら、適切な文字起こし設定でさらに精度を改善できます。
言語を指定する
ほとんどのASRシステムは、自動検出に依存するよりも、話されている言語を指定した方がパフォーマンスが向上します。自動検出は追加の推論ステップを追加し、ノイズの多い音声ではうまくいかず、間違った言語モデルを選択する可能性があります。言語がわかっている場合は、明示的に設定してください。
適切なモデルティアを選ぶ
多くの文字起こしサービスは複数のモデルティアを提供しており、高精度ティアは一般的に、音声と干渉を分離する容量が大きいモデルを使うため、ノイズをよりうまく処理します。利用中のサービスにそのようなティアがあるなら、難しいサンプルで試す価値があります。自分のクリップは音声テキスト変換ツールでテストできます。
話者ダイアライゼーションを慎重に使用する
話者ダイアライゼーション(誰が何を言ったかを識別するプロセス)は、話者間の音響的な違いの検出に依存しています。背景ノイズはこれらの違いをマスクし、ダイアライゼーションモデルが1人の話者を複数のラベルに分割したり、異なる話者を1つに統合したりする原因となります。音声がノイズが多く、ダイアライゼーション結果が信頼できないように見える場合、ダイアライゼーションなしで文字起こしし、話者ラベルを手動で追加した方がより良い結果が得られる場合があります。
長い録音をセグメントに分割する
長い録音の一部のみがノイズが多い場合、ファイルをセグメントに分割して個別に文字起こしすることを検討してください。これにより、ノイズの多いセクションがクリーンな部分でのモデルのパフォーマンスに影響を与えるのを防ぎます。ノイズ特性に基づいて、異なるセグメントに異なるノイズ除去設定を適用することもできます。
文字起こし後のクリーンアップのヒント
最適な音声準備と文字起こし設定を使っても、ノイズの多い録音は手動レビューが必要な文字起こしを生成します。効率的なクリーンアップのための戦略を以下に紹介します。
高エラーセクションから優先的に
文字起こしと一緒に音声を聴き、実際の音声から文字起こしが最も乖離しているセクションを特定します。これらは通常、最もノイズレベルが高い瞬間です。文字起こし全体を順に読むのではなく、これらのセクションの修正を優先してください。
タイムスタンプを使って移動する
単語レベルまたはセグメントレベルのタイムスタンプを提供する文字起こしツールでは、関連する音声位置に直接クリックして移動できます。これにより、音声を手動でスクラブするのと比較して、個々の単語の検証と修正がはるかに速くなります。Vocovaは各セグメントにタイムスタンプを提供するため、録音の任意のポイントに直接ジャンプできます。
一般的なノイズ起因のエラーに注意する
ノイズの多い音声は特徴的な文字起こしエラーを生じます:
- ファントムワード モデルがノイズを音声と解釈した場所に挿入される
- 欠落ワード ノイズが音声信号を完全にマスクした場所で発生
- 同音異義語と近似語 ノイズが区別する音を不明瞭にしたため、モデルが似た音の単語を選んだ場合
- 文字化けした固有名詞 名前や専門用語はコンテキストからの予測が難しいため
検索と置換を体系的なエラーに使用する
モデルが録音全体で特定の用語(人名、会社名、技術用語)を一貫して誤って文字起こししている場合、個別に修正するのではなく、検索と置換を使ってすべてのインスタンスを一度に修正してください。
翻訳を使った2回目のパスを検討する
元の文字起こしに重大なエラーがあり、翻訳版も必要な場合、ソース文字起こしを先に修正することが重要です。翻訳モデルはソーステキストのエラーを伝播させ、時には増幅させます。翻訳する前に文字起こしをクリーンアップしてください。
ノイズの多い音声が救いようのない場合
いかなるノイズ除去やAIのチューニングも使える文字起こしを生成できない状況があります。これらのケースを早期に認識することで、時間とフラストレーションを節約できます。
音声が救いようのない兆候:
- ヘッドフォンで注意深く聴いても、自分自身が音声を理解できない
- 複数の話者が長期間にわたって同時に話しており、明確に支配的な声がない
- SNRが5dB未満で、ノイズが音声とほぼ同じか、それよりも大きい
- 重度のクリッピング(録音レベルが高すぎたことによる歪み)が波形を永久に破壊している
- 重い残響により、音声がトンネルや階段室で録音されたように聞こえる
AI文字起こしが失敗した場合のオプション
- 人力文字起こし 文脈の手がかり、(動画がある場合の)読唇、テーマに関する専門知識を使ってAIでは解読できない困難な音声に対応できるプロフェッショナルによるもの。これは遅くてコストがかかりますが、エッジケースに対応します。より詳しい比較については、AI vs 人力文字起こしのガイドをご覧ください。
- 可能であれば再録音。 コンテンツが許す場合、より良い機材と環境で新しい録音セッションをスケジュールすることは、深刻に劣化した録音を救おうとするよりも速いことが多いです。
- 部分的な文字起こし。 許容可能な音声品質のセクションを文字起こしし、ギャップを注記する。明確に[聞き取り不能]とマークされたセクションのある文字起こしは、間違った推測で埋め尽くされたものよりも有用です。
よくある質問
文字起こし精度に影響する最大の要因は何ですか?
信号対雑音比です。背景ノイズに対して音声が大きいほど、AIでも人力でも、あらゆる文字起こしツールがより正確に単語を識別できます。静かな部屋で口元に近いマイクが最良の結果を生みます。これを最も速く高める方法については、上記の録音設定、マイクの選択、背景ノイズの軽減に関するセクションをご覧ください。
AI文字起こしツールは背景音楽に対応できますか?
ある程度は。音楽が静かで音声がクリアであれば、ほとんどの最新ASRモデルは音楽を通して文字起こしできます。ボーカル付きの大きな音楽は、モデルがターゲットの音声を歌声から確実に区別できないため、精度に重大な問題を引き起こします。低音量のインストゥルメンタルバックグラウンドミュージックは、あらゆる音量のボーカルミュージックよりも妨害が少ないです。
文字起こしのために音声をアップロードする前にノイズ除去を使うべきですか?
自動的に使うべきではありません。まずテストしてください。音がきれいなら文字起こしも良くなると思いがちですが、Whisperのような最新AIモデルはノイズを含むデータで訓練されています。2025〜2026年の研究では、ノイズ除去や音声強調が、人間には音が良く聞こえる場合でも、処理アーティファクトによって単語誤り率を上げることがしばしばありました。信頼できる方法は、短いサンプルを未処理版とノイズ除去版の両方で文字起こしし、より正確な方を採用することです。ノイズ除去する場合は控えめにしてください。強すぎる設定は金属的なアーティファクトを生み、助ける以上に害になります。
ノイズの多い音声で言語を指定すると精度が向上しますか?
はい。手動で言語を設定すると、ASRモデルは最初から正しい語彙と言語モデルを使用します。ノイズの多い音声では、自動検出ステップで言語を誤認識する可能性が高くなり、文字起こし全体に間違ったモデルが適用されます。言語がわかっている場合は常に指定してください。
音声品質は単語誤り率にどの程度影響しますか?
大幅に影響します。ただし正確な数値はモデル、言語、ノイズの種類によって変わるため、ここでは測定保証ではなく大まかな目安として見てください。クリーンなスタジオ音声は最新ASRで5%未満のWERに収まることが多く、オフィスや軽い交通騒音のような中程度のノイズでは二桁台前半になりがちです。混雑したレストランや建設現場では30%を超えることもあります。関係は直線的ではなく、SNRが約15dBを下回ると精度は急速に低下します。クリーン音声の基準値自体が言語間でどれほど違うかは、言語別の文字起こし精度をご覧ください。
ノイズの多い音声はAIと人力の文字起こし担当者のどちらで文字起こしすべきですか?
適度なノイズのある音声の場合、AIツールは通常十分であり、はるかに高速です。注意深く聴いても理解が困難なほど深刻に劣化した音声の場合、熟練した人力の文字起こし担当者は、文脈的な推論、テーマに関する知識、動画からの視覚的手がかりを使ってギャップを埋めることができるため、通常AIを上回ります。AIと人力文字起こしの比較は、特定のノイズ条件と精度要件に大きく依存します。
文字起こしに最適な音声形式は何ですか?
WAVとFLACはロスレスで完全な音声のディテールを保つため最適です。実際には、192kbps以上のMP3もうまく機能します。ほとんどのAI文字起こしツールは一般的な形式をすべて受け付けるので、優先すべきは特定のコンテナ形式を気にすることよりも、高いビットレートで録音することです。
文字起こしのために高価なマイクを買う価値はありますか?
たいていの場合はありません。50〜100ドルのUSBマイクを静かな部屋に正しく配置すれば、文字起こしに適した音声が得られます。高価なマイクは声の豊かさを加えますが、それは音声テキスト変換の精度よりも音楽や放送にとって重要です。マイク自体をアップグレードする前に、部屋の処理とマイクの配置に投資してください。
出典と参考資料
- Chondhekar et al., "When De-noising Hurts: A Systematic Study of Speech Enhancement Effects on Modern Medical ASR Systems"(arXiv, 2025)-- 音声強調によって、音がきれいに聞こえる場合でもWhisper系モデルの単語誤り率が上がるケースを報告
- Islam, Nahar & Hamid, "When Denoising Hinders: Revisiting Zero-Shot ASR with SAM-Audio and Whisper"(arXiv, 2026)
- Mu et al., "Performance evaluation of automatic speech recognition systems on integrated noise-network distorted speech", Frontiers in Signal Processing(2022)-- WERとSNRの関係
- Hugging Face Audio Course -- preprocessing -- 最新のASRモデルが16kHz音声を前提にする理由
- Engineering ToolBox -- inverse-square law -- 距離が2倍になるごとに約6dB下がるという目安
- National Center for Voice and Speech -- fundamental frequency -- 80〜100Hzのハイパスカットオフを考えるための背景
