Cómo transcribir audio con ruido y reducir errores por ruido de fondo (2026)
El ruido de fondo es la mayor causa de errores de transcripción. Una guía práctica para grabar audio más limpio, ajustar lo que importa, saber cuándo conviene o no aplicar reducción de ruido antes de transcribir y manejar audio que ya no se puede salvar.
El ruido de fondo es la causa principal de errores de transcripción. Incluso los modelos de reconocimiento de voz con IA más avanzados tienen dificultades cuando la señal de audio compite con tráfico, zumbido de HVAC, voces cruzadas o eco de la sala. Una grabación que se transcribe casi perfectamente en una habitación silenciosa puede degradarse con fuerza en un entorno ruidoso, convirtiendo una transcripción útil en algo que requiere mucha corrección manual.
La buena noticia es que la mayoría de los problemas de audio ruidoso son prevenibles o solucionables. Esta guía cubre toda la cadena: cómo grabar audio más limpio en primer lugar, cómo procesar grabaciones ruidosas antes de transcribir, cómo configurar los ajustes de transcripción para mejores resultados y cómo manejar los casos donde el audio es genuinamente irrecuperable.
Por qué el ruido de fondo afecta la precisión de la transcripción
Para entender por qué el ruido causa errores de transcripción, ayuda saber cómo funciona el reconocimiento automático de voz (ASR) a nivel básico.
Los modelos ASR convierten audio en texto analizando las propiedades acústicas del sonido, dividiendo la señal en pequeñas ventanas de tiempo y prediciendo qué palabras o fonemas son más probables en cada punto. El modelo ha sido entrenado con miles de horas de habla y ha aprendido los patrones estadísticos que distinguen una palabra de otra.
El ruido de fondo interrumpe este proceso al agregar energía acústica que no corresponde al habla. Cuando el zumbido de un ventilador o el murmullo de una multitud ocupa el mismo rango de frecuencia que la voz del hablante, el modelo no puede separar limpiamente las dos señales. Hace su mejor estimación, pero esas estimaciones se vuelven menos confiables a medida que aumenta el nivel de ruido.
El término técnico para esto es relación señal-ruido (SNR). La SNR mide cuánto más fuerte es la señal de voz comparada con el ruido de fondo, expresada en decibelios. Una SNR de 30 dB o más (la voz es mucho más fuerte que el ruido) produce buenos resultados de transcripción. Una SNR por debajo de 10 dB (la voz es apenas más fuerte que el ruido) lleva a una pérdida significativa de precisión. La caída es brusca, no gradual: las tasas de error suben con fuerza a medida que cae la SNR, por lo que un poco más de distancia al micrófono, o una sola unidad de aire acondicionado encendida, puede hundir la precisión.
La precisión de transcripción se mide típicamente usando la tasa de error de palabras (WER). Una entrevista tranquila y bien grabada puede quedar por debajo del 5% de WER; la misma conversación en un café concurrido puede superar el 20-25%. Las cifras exactas dependen del modelo, el idioma y el tipo de ruido — consulta precisión de transcripción por idioma para ver cuánto varía por sí sola la base con audio limpio — pero la brecha aquí se debe casi por completo al ruido.
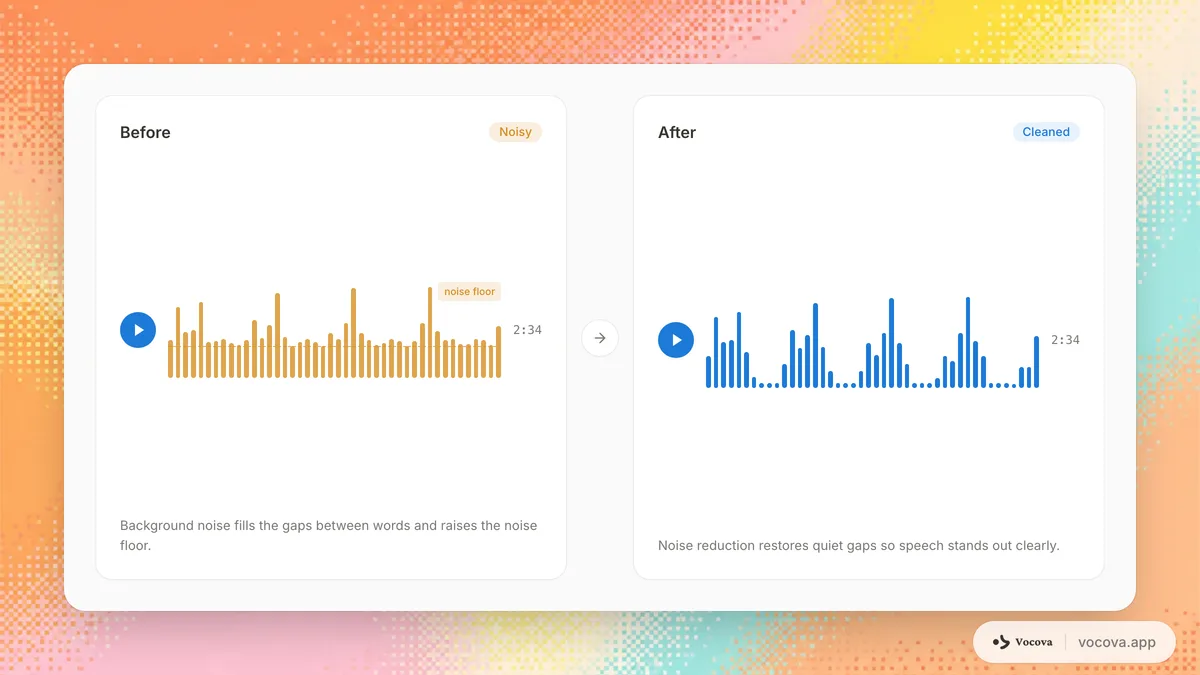
Tipos de ruido de audio
No todo el ruido afecta la transcripción por igual. Comprender el tipo de ruido en su grabación le ayuda a elegir el enfoque correcto para tratarlo.
Ruido ambiental
Sonidos de fondo constantes como aire acondicionado, tráfico, ventiladores o zumbido de refrigerador. Este tipo de ruido es relativamente consistente en volumen y frecuencia, lo que lo convierte en el más fácil de eliminar con herramientas de reducción de ruido. Sin embargo, si es lo suficientemente fuerte, aún degrada la precisión de transcripción.
Ruido electrónico
Siseo, zumbido o ruido introducido por el propio equipo de grabación. Las causas comunes incluyen micrófonos de baja calidad, bucles de tierra en configuraciones con cable, interferencia electromagnética de electrónicos cercanos e interfaces de audio con pisos de ruido altos. El ruido electrónico suele ser consistente y tratable con reducción de ruido.
Reverberación
Eco causado por el sonido rebotando en superficies duras en una habitación. La reverberación difumina la señal de voz a lo largo del tiempo, dificultando que los modelos ASR identifiquen los límites de las palabras. Un hablante en un baño con azulejos o una sala de conferencias vacía producirá significativamente más reverberación que uno en una oficina alfombrada y amueblada. La reverberación es más difícil de eliminar que el ruido ambiental porque es una versión transformada de la señal original.
Interferencia cruzada y superposición de voces
Múltiples personas hablando al mismo tiempo. Este es uno de los tipos de ruido más difíciles para la transcripción porque la señal interferente es en sí misma voz, y el modelo tiene dificultad para separar a los dos hablantes. La interferencia cruzada ocurre comúnmente en reuniones, paneles de discusión y entrevistas grupales.
Ruido de viento
Retumbo de baja frecuencia causado por el movimiento del aire a través del micrófono. El ruido de viento es común en grabaciones al aire libre y puede enmascarar completamente el habla en ráfagas fuertes. Afecta principalmente el extremo bajo del espectro de frecuencias y a menudo puede reducirse con un filtro de paso alto o parabrisas.
Ruido impulsivo
Sonidos repentinos de corta duración como clics de teclado, crujido de papel, toses o impactos de construcción. Estos son breves pero pueden corromper palabras o frases individuales. Los modelos ASR pueden malinterpretar un clic agudo como un sonido consonántico, insertando palabras fantasma en la transcripción.
Consejos previos a la grabación para audio más limpio
La forma más efectiva de obtener transcripciones precisas de ambientes ruidosos es capturar mejor audio en primer lugar. Unos minutos de preparación antes de presionar grabar pueden ahorrar horas de limpieza después.
Elija el micrófono correcto
La selección del micrófono tiene un impacto importante en el rechazo de ruido.
- Micrófonos lavalier (de solapa) se sujetan cerca de la boca del hablante, manteniendo la señal de voz fuerte en relación con el ruido de la sala. Son ideales para entrevistas y presentaciones.
- Micrófonos direccionales (cardioide o shotgun) capturan sonido principalmente desde el frente y rechazan sonido desde los lados y la parte trasera. Apúntelos al hablante y lejos de las fuentes de ruido.
- Micrófonos omnidireccionales capturan sonido por igual desde todas las direcciones. Son útiles para discusiones grupales pero captan más ruido ambiental.
- Micrófonos de diadema posicionan la cápsula cerca de la boca y son excelentes para ambientes ruidosos, por eso los centros de llamadas y los pilotos los usan.
Posicione el micrófono correctamente
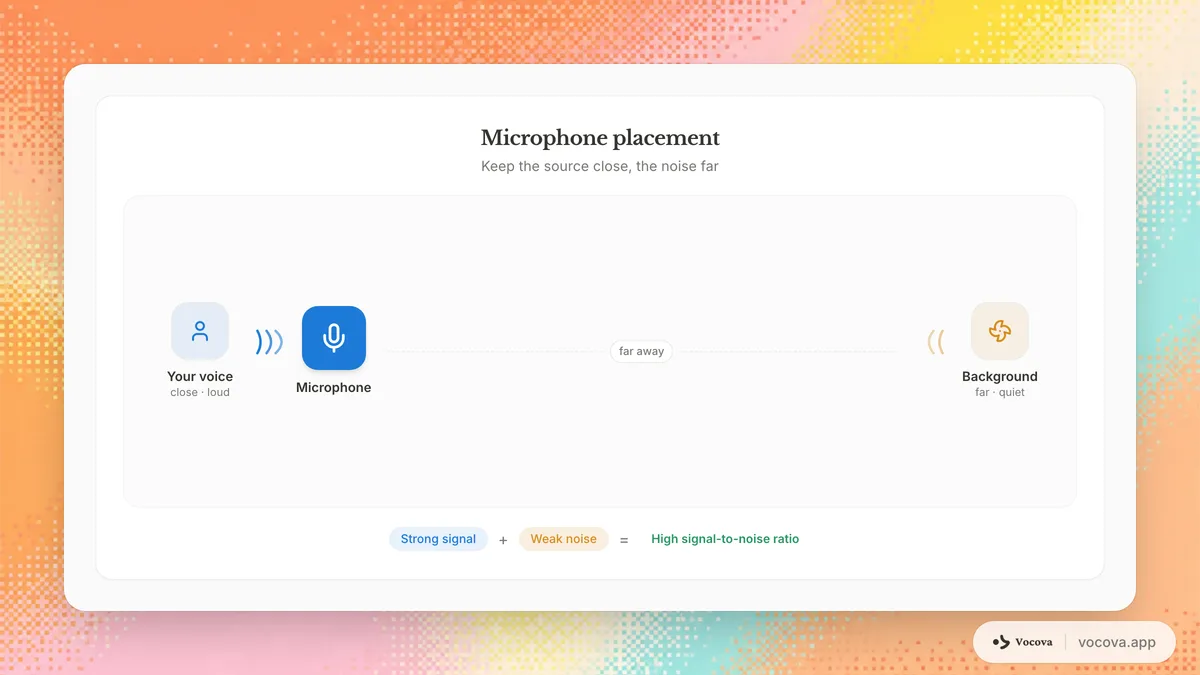
La distancia importa más de lo que la mayoría de las personas creen. Duplicar la distancia entre el micrófono y el hablante reduce la señal de voz en aproximadamente 6 dB mientras que el nivel de ruido de fondo permanece igual. Mantenga el micrófono lo más cerca posible del hablante.
Para un micrófono de solapa, sujételo 15-20 cm debajo de la barbilla. Para un micrófono de escritorio, posiciónelo a 15-30 cm de la boca del hablante. Evite colocar micrófonos cerca de fuentes de ruido como ventiladores de computadora, rejillas de ventilación o ventanas que dan a una calle concurrida.
Trate la sala
No necesita un estudio profesional para reducir significativamente el ruido y la reverberación.
- Cierre ventanas y puertas para bloquear el ruido externo
- Apague el aire acondicionado, ventiladores y electrónicos innecesarios durante la grabación
- Agregue materiales suaves (cortinas, alfombras, muebles tapizados) para reducir el eco
- Evite salas con superficies duras y paralelas (pisos de azulejo, paredes de vidrio) que crean reverberación
- Si graba en una oficina, elija una sala más pequeña y alfombrada en lugar de una sala de conferencias grande
Use un parabrisas al aire libre
Si está grabando al aire libre, use un parabrisas de espuma o una cubierta de viento peluda (a menudo llamada "dead cat") en su micrófono. El ruido de viento es extremadamente disruptivo para la transcripción y casi imposible de eliminar completamente en posprocesamiento.
Grabe una muestra de ruido de referencia
Antes de que el hablante comience a hablar, grabe de 10 a 15 segundos de solo el ruido de la sala. Esta "huella de ruido" es útil para herramientas de reducción de ruido, que la usan para aprender las características del ruido y restarlo de la grabación.
Ajustes de grabación que afectan la precisión de transcripción
Más allá de la elección del micrófono y el tratamiento de la sala, unos pocos ajustes técnicos de grabación determinan cuánto detalle vocal sobrevive hasta la etapa de transcripción.
Frecuencia de muestreo. La mayoría de los modelos modernos de ASR remuestrean todo internamente a 16 kHz — la frecuencia con la que fueron entrenados — así que una frecuencia mayor no mejora la precisión. Graba a 44.1 kHz o 48 kHz por compatibilidad y archivado limpio, no por precisión de transcripción; 16 kHz mono ya es suficiente para el modelo. Por encima de 48 kHz no hay beneficio para reconocimiento de voz.
Profundidad de bits. Grabe a 16 bits o 24 bits. La diferencia importa más en los pasajes silenciosos: 24 bits captura el habla suave con menos ruido de cuantización, lo que ayuda cuando el hablante está más lejos del micrófono.
Mono vs estéreo. Para un solo hablante, mono está bien y produce archivos más pequeños. Para múltiples hablantes, grabar cada voz en un canal separado mejora de forma medible la diarización de hablantes, porque el modelo puede separar voces que llegan en canales distintos y limpios.
Formato de archivo. WAV y FLAC son sin pérdidas e ideales para transcripción. MP3 a 192 kbps o más es aceptable; AAC/M4A (usado por la mayoría de los teléfonos) es ligeramente mejor que MP3 al mismo bitrate; OGG/Opus ofrece buena calidad a bitrates más bajos. Si el almacenamiento lo permite, archive en WAV o FLAC. La mayoría de las herramientas, incluido Vocova, aceptan todos los formatos comunes — la prioridad es preservar el detalle en la grabación misma, no el contenedor.
Cómo elegir el tipo de micrófono y la conexión
La guía de micrófonos anterior se enfoca en la direccionalidad para el rechazo de ruido. Otras dos elecciones establecen la calidad base de cualquier grabación.
- Condensador vs dinámico. Los micrófonos de condensador son más sensibles y capturan más detalle vocal, lo que ayuda en salas silenciosas y controladas — pero también captan más ruido ambiental. Los micrófonos dinámicos rechazan más ruido de fondo por diseño, lo que los convierte en la opción más segura en espacios sin tratar o ruidosos.
- USB vs XLR. Los micrófonos USB (por ejemplo el Rode NT-USB Mini o el Audio-Technica AT2020USB+) incluyen una interfaz de audio integrada y son la opción pragmática para la mayoría de las personas. Los micrófonos XLR necesitan una interfaz separada pero ofrecen pisos de ruido más bajos y más control — vale la pena principalmente si ya posee la interfaz.
Para la transcripción, el ambiente importa más que el micrófono específico. Un micrófono USB de $50–100 colocado correctamente en una habitación silenciosa produce audio de calidad para transcripción.
Consejos para escenarios de grabación específicos
- Reuniones: Use un micrófono de conferencia dedicado (como el Jabra Speak o el Anker PowerConf) en el centro de la mesa en lugar del micrófono de una laptop. Para reuniones remotas, grabe la salida de audio del software de reunión directamente y pida a los participantes que usen diademas para evitar el eco.
- Entrevistas: Dé al entrevistador y al entrevistado micrófonos separados — idealmente lavalier inalámbricos grabados en canales separados. Para entrevistas telefónicas, grabe a través de software en lugar de apuntar un micrófono a un altavoz.
- Conferencias: Un micrófono lavalier en el presentador es la configuración más confiable. Haga que el presentador repita las preguntas de la audiencia antes de responder, ya que el audio de la audiencia rara vez se captura limpiamente.
- Pódcasts: Dé a cada anfitrión e invitado su propio micrófono en una pista separada. Para grabación remota, haga que cada participante grabe localmente (con herramientas como Riverside.fm o Zencastr) y combine las pistas después para evitar artefactos de compresión de videollamada.
Errores comunes de grabación que perjudican la transcripción
- Teléfono en un bolsillo o bolso. La tela amortigua las frecuencias altas necesarias para distinguir consonantes, y el movimiento agrega ruido de roce. Coloque el teléfono en una superficie estable orientado hacia el hablante.
- Sentarse demasiado lejos del micrófono. La distancia debilita la señal de voz mientras el ruido de fondo permanece constante, por lo que la grabación termina dominada por el ruido. Manténgase cerca.
- Ganancia ajustada demasiado alta. El recorte es una distorsión permanente que no se puede reparar. Ajuste los niveles para que el habla normal alcance picos alrededor de -12 dB a -6 dB.
- Ganancia ajustada demasiado baja. Grabar demasiado bajo le obliga a amplificar después, lo que también amplifica el piso de ruido.
- Grabar por Bluetooth. El perfil de manos libres de Bluetooth comprime fuertemente el audio de llamada. Use una conexión con cable para grabar siempre que sea posible.
- Sin grabación de prueba. Grabe y reproduzca 30 segundos antes de la sesión real. Detectar el eco de la sala, el zumbido o el ruido de manipulación de antemano es mucho más barato que descubrirlo después de una grabación de dos horas.
Cómo limpiar audio ruidoso antes de transcribir
Si ya tiene una grabación ruidosa, las herramientas de procesamiento de audio pueden mejorar la calidad de la señal antes de enviarla a un servicio de transcripción. Los resultados no igualarán una grabación limpia original, pero pueden ayudar.
Una advertencia que sorprende: quitar ruido no siempre ayuda a la transcripción con IA. Los modelos tipo Whisper fueron entrenados con mucho audio imperfecto, y varios estudios de 2025-2026 (por ejemplo, When De-noising Hurts, 2025, y When Denoising Hinders, 2026) encontraron que las herramientas de mejora de voz y reducción de ruido pueden aumentar la tasa de error de palabras — a veces mucho — aunque el audio suene más limpio para una persona, porque el procesamiento introduce artefactos que el modelo nunca vio durante el entrenamiento. La regla fiable: procesa una muestra corta de ambas formas, transcribe cada versión y conserva la que gane. Sorprendentemente a menudo, gana el audio sin procesar. Las herramientas de abajo ayudan más con ruido estable y bien definido; ayudan menos, e incluso pueden perjudicar, con interferencias parecidas al habla y reverberación.
Audacity (gratis, código abierto)
Audacity es un editor de audio gratuito con una herramienta de reducción de ruido integrada.
- Seleccione una porción del audio que contenga solo ruido (sin voz)
- Vaya a Efecto > Reducción de ruido > Obtener perfil de ruido
- Seleccione toda la pista de audio
- Aplique Reducción de ruido con ajustes de aproximadamente 12 dB de reducción, 6 de sensibilidad y 3 de suavizado de frecuencia
- Previsualice el resultado y ajuste si la voz suena distorsionada
Audacity también tiene un filtro de paso alto (Efecto > Curva de filtro) que puede eliminar el retumbo de baja frecuencia del viento o sistemas HVAC. Corte frecuencias por debajo de 80-100 Hz para grabaciones de voz hablada.
Adobe Podcast Enhance Speech (gratis, basado en la web)
Adobe ofrece una herramienta gratuita en línea que usa IA para mejorar grabaciones de voz. Suba su archivo de audio y la herramienta intenta aislar la voz, reducir el ruido y normalizar el volumen. Funciona bien para niveles de ruido moderados y es lo suficientemente simple para usuarios no técnicos. La limitación es un tope de tamaño de archivo y el hecho de que procesa todo el archivo sin control granular.
iZotope RX
iZotope RX es una suite profesional de reparación de audio utilizada en producción de transmisiones y cine. Ofrece herramientas avanzadas para reducción de ruido, de-reverb, de-click, de-hum y aislamiento de diálogo. Es la opción más capaz pero viene con una curva de aprendizaje significativa y costo. Para trabajo regular de transcripción con audio desafiante, vale la pena la inversión.
Consejos generales para limpieza de audio
- Aplique reducción de ruido de forma conservadora. Los ajustes agresivos eliminan el ruido pero introducen artefactos que suenan como gorjeo metálico. Estos artefactos pueden confundir a los modelos ASR tanto como el ruido original.
- Use un filtro de paso alto para eliminar retumbo por debajo de 80 Hz. El habla humana no contiene información significativa por debajo de esta frecuencia.
- Normalice el nivel de audio para que los picos de voz estén alrededor de -3 dB a -6 dB. Los modelos ASR rinden mejor con niveles de volumen consistentes.
- No comprima el rango dinámico excesivamente. Algo de compresión ayuda con habla susurrada o gritada, pero la compresión pesada eleva el piso de ruido.
Ajustes de transcripción con IA para audio ruidoso
Una vez que haya limpiado su audio tanto como sea posible, los ajustes de transcripción correctos pueden mejorar aún más la precisión.
Especifique el idioma
La mayoría de los sistemas ASR rinden mejor cuando usted especifica el idioma hablado en lugar de depender de la detección automática. La detección automática agrega un paso de inferencia extra que puede fallar con audio ruidoso, potencialmente seleccionando el modelo de idioma incorrecto por completo. Si conoce el idioma, configúrelo explícitamente.
Elija el nivel de modelo correcto
Muchos servicios de transcripción ofrecen múltiples niveles de modelo, y los niveles de mayor precisión generalmente manejan mejor el ruido porque usan modelos más grandes con más capacidad para separar el habla de la interferencia. Si su proveedor tiene uno, vale la pena probarlo con una muestra difícil; puede hacerlo con su propio clip en la herramienta de audio a texto.
Use la diarización de hablantes con precaución
La diarización de hablantes, el proceso de identificar quién dijo qué, se basa en detectar diferencias acústicas entre hablantes. El ruido de fondo puede enmascarar estas diferencias, causando que el modelo de diarización divida a un hablante en múltiples etiquetas o fusione diferentes hablantes en una sola. Si su audio es ruidoso y los resultados de diarización parecen poco confiables, puede obtener mejores resultados transcribiendo sin diarización y agregando etiquetas de hablante manualmente.
Divida grabaciones largas en segmentos
Si solo partes de una grabación larga son ruidosas, considere dividir el archivo en segmentos y transcribirlos por separado. Esto evita que una sección ruidosa afecte el rendimiento del modelo en las porciones más limpias. También puede aplicar diferentes ajustes de reducción de ruido a diferentes segmentos según sus características de ruido.
Consejos de limpieza post-transcripción
Incluso con preparación óptima del audio y ajustes de transcripción, las grabaciones ruidosas producirán transcripciones que necesitan revisión manual. Aquí hay estrategias para una limpieza eficiente.
Enfóquese primero en las secciones con más errores
Escuche el audio junto con la transcripción e identifique las secciones donde la transcripción diverge más del habla real. Estas son usualmente los momentos con los niveles de ruido más altos. Priorice corregir estas secciones en lugar de leer toda la transcripción linealmente.
Use marcas de tiempo para navegar
Las herramientas de transcripción que proporcionan marcas de tiempo a nivel de palabra o segmento le permiten hacer clic directamente en la posición de audio relevante. Esto hace mucho más rápido verificar y corregir palabras individuales comparado con desplazarse por el audio manualmente. Vocova proporciona marcas de tiempo para cada segmento, para que pueda saltar directamente a cualquier punto de la grabación.
Esté atento a errores comunes inducidos por ruido
El audio ruidoso produce errores de transcripción característicos:
- Palabras fantasma insertadas donde el modelo interpretó ruido como habla
- Palabras omitidas donde el ruido enmascaró completamente la señal de voz
- Homófonos y casi-aciertos donde el modelo eligió una palabra de sonido similar porque el ruido oscureció los sonidos diferenciadores
- Nombres propios distorsionados ya que los nombres y términos técnicos son menos predecibles por contexto
Use buscar y reemplazar para errores sistemáticos
Si el modelo transcribe consistentemente mal un término específico a lo largo de la grabación (un nombre de persona, un nombre de empresa, una palabra técnica), use buscar y reemplazar para corregir todas las instancias a la vez en lugar de corregirlas individualmente.
Considere una segunda pasada con traducción
Si la transcripción original tiene errores significativos y también necesita una versión traducida, corregir la transcripción fuente primero es crítico. Los modelos de traducción propagan y a veces amplifican los errores del texto fuente. Limpie la transcripción antes de traducir.
Cuando el audio ruidoso es irrecuperable
Hay situaciones donde ninguna cantidad de reducción de ruido o ajuste de IA producirá una transcripción utilizable. Reconocer estos casos temprano ahorra tiempo y frustración.
Señales de que el audio puede ser irrecuperable:
- No puede entender el habla usted mismo al escuchar cuidadosamente con auriculares
- Múltiples hablantes hablan simultáneamente por períodos prolongados sin una voz dominante clara
- La SNR está por debajo de 5 dB, lo que significa que el ruido es casi tan fuerte o más fuerte que la voz
- Recorte severo (distorsión por nivel de grabación demasiado alto) ha corrompido permanentemente la forma de onda
- Reverberación severa hace que el habla suene como si fuera grabada en un túnel o escalera
Opciones cuando la transcripción con IA falla
- Transcripción humana por un profesional que puede usar pistas contextuales, lectura de labios (si hay video disponible) y experiencia en la materia para descifrar audio difícil. Esto es más lento y costoso pero maneja casos extremos que la IA no puede. Para una comparación más profunda, consulte nuestra guía sobre IA vs transcripción humana.
- Volver a grabar si es posible. Si el contenido lo permite, programar una nueva sesión de grabación con mejor equipo y ambiente es a menudo más rápido que intentar salvar una grabación severamente degradada.
- Transcripción parcial. Transcriba las secciones con calidad de audio aceptable y marque los vacíos. Una transcripción con secciones claramente marcadas como [inaudible] es más útil que una llena de suposiciones incorrectas.
Preguntas frecuentes
¿Cuál es el factor más importante que afecta la precisión de transcripción?
La relación señal-ruido. Cuanto más fuerte sea la voz en relación con el ruido de fondo, más precisamente cualquier herramienta de transcripción, ya sea IA o humana, puede identificar las palabras. Un micrófono posicionado de cerca en una habitación silenciosa produce los mejores resultados. Consulte las secciones anteriores sobre ajustes de grabación, elección del micrófono y reducción del ruido de fondo para conocer las formas más rápidas de aumentarla.
¿Pueden las herramientas de transcripción con IA manejar música de fondo?
Moderadamente. Si la música es suave y la voz es clara, la mayoría de los modelos ASR modernos pueden transcribir a través de ella. La música fuerte, especialmente con voces, causa problemas significativos de precisión porque el modelo no puede distinguir confiablemente el habla objetivo del canto. La música instrumental de fondo a bajo volumen es menos disruptiva que la música vocal a cualquier volumen.
¿Debería usar reducción de ruido antes de subir audio para transcripción?
No automáticamente: pruébalo primero. Es intuitivo pensar que un audio más limpio se transcribe mejor, pero modelos modernos como Whisper fueron entrenados con datos ruidosos, y estudios de 2025-2026 encontraron que la reducción de ruido y la mejora de voz con frecuencia aumentaban la tasa de error de palabras aunque el audio sonara mejor para una persona, porque el procesamiento agrega artefactos que el modelo no vio durante el entrenamiento. El enfoque fiable es transcribir una muestra corta en bruto y otra con reducción de ruido, y quedarse con la más precisa. Si reduces ruido, hazlo con suavidad: los ajustes agresivos introducen artefactos metálicos que perjudican más de lo que ayudan.
¿Especificar el idioma mejora la precisión para audio ruidoso?
Sí. Cuando configura manualmente el idioma, el modelo ASR usa el vocabulario y modelo de lenguaje correctos desde el inicio. Con audio ruidoso, el paso de detección automática tiene más probabilidad de identificar incorrectamente el idioma, lo que luego aplica el modelo incorrecto para toda la transcripción. Siempre especifique el idioma cuando lo conozca.
¿Cuánto afecta la calidad del audio a la tasa de error de palabras?
Mucho, aunque las cifras exactas varían por modelo, idioma y tipo de ruido, así que trátalas como ejemplos aproximados y no como garantías medidas. El audio limpio de estudio suele quedar por debajo del 5% de WER con ASR moderno; el ruido moderado de oficina o tráfico ligero suele caer en los dos dígitos bajos; un restaurante concurrido o una obra puede superar el 30%. La relación no es lineal: la precisión se degrada rápido cuando la SNR cae por debajo de unos 15 dB. Para ver cuánto varía la base de audio limpio entre idiomas, consulta precisión de transcripción por idioma.
¿Es mejor transcribir audio ruidoso con IA o con un transcriptor humano?
Para audio moderadamente ruidoso, las herramientas de IA son usualmente suficientes y mucho más rápidas. Para audio severamente degradado donde incluso escuchar cuidadosamente es difícil, un transcriptor humano hábil típicamente superará a la IA porque puede usar razonamiento contextual, conocimiento de la materia y señales visuales del video para llenar vacíos. La comparación entre IA y transcripción humana depende en gran medida de las condiciones específicas de ruido y sus requisitos de precisión.
¿Cuál es el mejor formato de audio para transcripción?
WAV y FLAC son los mejores porque son sin pérdidas y preservan todo el detalle del audio. En la práctica, MP3 a 192 kbps o más también funciona bien. La mayoría de las herramientas de transcripción con IA aceptan todos los formatos comunes, así que la prioridad es grabar a un bitrate alto en lugar de preocuparse por el formato de contenedor específico.
¿Vale la pena comprar un micrófono caro para transcripción?
Usualmente no. Un micrófono USB de $50–100 en una habitación silenciosa con la colocación correcta produce audio de calidad para transcripción. Los micrófonos caros agregan riqueza vocal que importa más para música y transmisión que para la precisión de voz a texto. Invierta en el tratamiento de la sala y la colocación del micrófono antes de actualizar el micrófono en sí.
Fuentes y lecturas recomendadas
- Chondhekar et al., "When De-noising Hurts: A Systematic Study of Speech Enhancement Effects on Modern Medical ASR Systems" (arXiv, 2025) -- la mejora de voz aumentó la tasa de error de palabras en modelos de la familia de Whisper, aunque el audio sonara más limpio
- Islam, Nahar & Hamid, "When Denoising Hinders: Revisiting Zero-Shot ASR with SAM-Audio and Whisper" (arXiv, 2026)
- Mu et al., "Performance evaluation of automatic speech recognition systems on integrated noise-network distorted speech", Frontiers in Signal Processing (2022) -- WER frente a SNR
- Hugging Face Audio Course -- preprocessing -- los modelos ASR modernos esperan audio a 16 kHz
- Engineering ToolBox -- inverse-square law -- la regla práctica de unos 6 dB por cada duplicación de distancia
- National Center for Voice and Speech -- fundamental frequency -- contexto para el corte de paso alto entre 80 y 100 Hz
