소음이 있는 오디오를 전사하고 배경 소음 오류를 줄이는 방법 (2026)
배경 소음은 전사 오류의 가장 큰 원인입니다. 더 깨끗하게 녹음하는 법, 중요한 설정, 전사 전에 노이즈 제거를 해야 할 때와 하지 말아야 할 때, 구제하기 어려운 오디오를 처리하는 방법을 실용적으로 안내합니다.
배경 소음은 전사 오류의 가장 큰 원인입니다. 가장 진보된 AI 음성 인식 모델조차 오디오 신호가 교통 소음, HVAC 소음, 겹치는 말소리, 방 에코와 경쟁할 때 어려움을 겪습니다. 조용한 방에서는 거의 완벽하게 전사되는 녹음도 소음이 있는 환경에서는 급격히 나빠져, 유용한 텍스트가 광범위한 수동 수정이 필요한 것으로 바뀔 수 있습니다.
좋은 소식은 대부분의 소음 문제가 예방 가능하거나 수정 가능하다는 것입니다. 이 가이드에서는 전체 과정을 다룹니다: 처음부터 더 깨끗한 오디오를 녹음하는 방법, 음성 인식 전에 소음이 있는 녹음을 처리하는 방법, 최고의 결과를 위한 음성 인식 설정 구성 방법, 그리고 오디오가 정말로 구제 불가능한 경우를 처리하는 방법.
배경 소음이 음성 인식 정확도에 영향을 미치는 이유
소음이 왜 음성 인식 오류를 일으키는지 이해하려면, 자동 음성 인식(ASR)이 기본적으로 어떻게 작동하는지 아는 것이 도움됩니다.
ASR 모델은 소리의 음향 특성을 분석하고, 신호를 작은 시간 구간으로 나누어, 각 지점에서 가장 가능성 높은 단어나 음소를 예측하여 오디오를 텍스트로 변환합니다. 모델은 수천 시간의 음성으로 학습되었으며 한 단어와 다른 단어를 구별하는 통계적 패턴을 학습했습니다.
배경 소음은 음성에 해당하지 않는 음향 에너지를 추가하여 이 과정을 방해합니다. 팬 소음이나 군중 소음이 화자 음성과 같은 주파수 대역을 차지하면, 모델은 두 신호를 깨끗하게 분리할 수 없습니다. 최선의 추측을 하지만, 소음 수준이 증가할수록 추측의 신뢰도가 떨어집니다.
이것의 기술 용어는 **신호 대 잡음비(SNR)**입니다. SNR은 배경 소음에 비해 음성 신호가 얼마나 큰지를 데시벨로 나타냅니다. 30dB 이상의 SNR(음성이 소음보다 훨씬 큰 경우)은 좋은 전사 결과를 생성합니다. 10dB 미만의 SNR(음성이 소음보다 겨우 큰 경우)은 심각한 정확도 손실을 초래합니다. 손실은 완만하지 않고 가파릅니다. SNR이 떨어질수록 오류율이 가파르게 치솟기 때문에, 마이크와의 거리가 조금만 늘어나거나 HVAC 한 대가 켜져 있어도 정확도가 무너질 수 있습니다.
전사 정확도는 일반적으로 단어 오류율(WER)을 사용해 측정됩니다. 조용하고 잘 녹음된 인터뷰는 WER 5% 미만에 머물 수 있지만, 같은 대화를 붐비는 카페에서 녹음하면 20-25%를 넘을 수 있습니다. 정확한 수치는 모델, 언어, 소음 유형에 따라 달라집니다. 깨끗한 오디오 기준선 자체가 언어별로 얼마나 다른지는 언어별 전사 정확도를 참고하세요. 하지만 여기서의 격차는 거의 전적으로 소음 때문입니다.
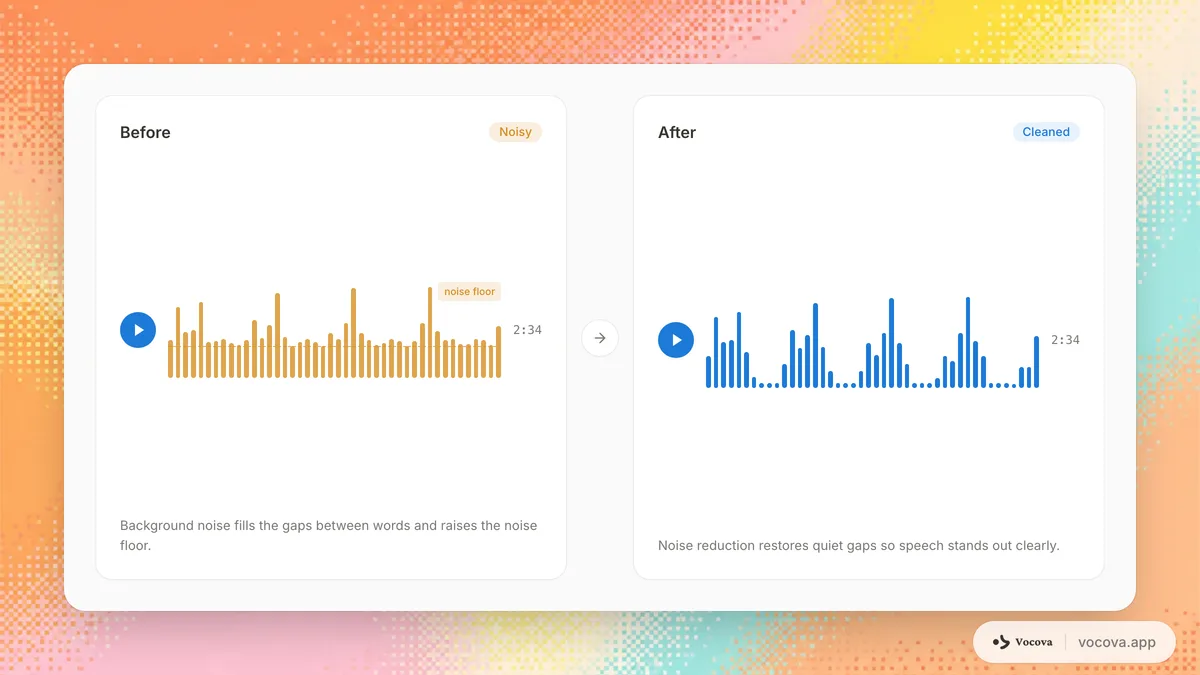
오디오 소음의 유형
모든 소음이 음성 인식에 동일한 영향을 미치는 것은 아닙니다. 녹음에 있는 소음의 유형을 이해하면 적절한 대처 방법을 선택하는 데 도움됩니다.
주변 소음
에어컨, 교통, 팬, 냉장고 소음과 같은 일정한 배경 소리. 이 유형의 소음은 음량과 주파수가 비교적 일정하여 소음 제거 도구로 가장 쉽게 제거됩니다. 하지만 충분히 크면 여전히 음성 인식 정확도를 떨어뜨립니다.
전자 소음
녹음 장비 자체에서 발생하는 히스, 버즈, 험. 일반적인 원인으로는 저품질 마이크, 유선 설정의 접지 루프, 근처 전자기기의 전자기 간섭, 높은 노이즈 플로어를 가진 오디오 인터페이스가 있습니다. 전자 소음은 보통 일정하며 소음 제거로 처리 가능합니다.
잔향
방의 딱딱한 표면에서 소리가 반사되어 발생하는 에코. 잔향은 시간에 걸쳐 음성 신호를 흩뜨려 ASR 모델이 단어 경계를 식별하기 어렵게 만듭니다. 타일 욕실이나 빈 회의실의 화자는 카펫이 깔린 가구가 있는 사무실보다 상당히 더 많은 잔향을 만듭니다. 잔향은 원본 신호의 변형된 버전이므로 주변 소음보다 제거하기 어렵습니다.
잡음과 겹침 발화
여러 사람이 동시에 말하는 것. 이것은 간섭 신호 자체가 음성이기 때문에 음성 인식에 가장 어려운 소음 유형 중 하나이며, 모델이 두 화자를 분리하기 어렵습니다. 잡음은 회의, 패널 토론, 그룹 인터뷰에서 흔히 발생합니다.
바람 소음
마이크를 가로지르는 공기 이동으로 인한 저주파 럼블. 바람 소음은 야외 녹음에서 흔하며, 강한 돌풍에서는 음성을 완전히 가릴 수 있습니다. 주로 주파수 스펙트럼의 저역대에 영향을 미치며, 고주파 필터나 윈드스크린으로 줄일 수 있습니다.
충격성 소음
키보드 클릭, 종이 섞기, 기침, 건설 충격과 같은 갑작스럽고 짧은 소리. 이것들은 짧지만 개별 단어나 구절을 손상시킬 수 있습니다. ASR 모델은 날카로운 클릭을 자음 소리로 잘못 해석하여 텍스트에 유령 단어를 삽입할 수 있습니다.
더 깨끗한 오디오를 위한 사전 녹음 팁
소음이 있는 환경에서 정확한 음성 인식을 얻는 가장 효과적인 방법은 처음부터 더 나은 오디오를 캡처하는 것입니다. 녹음 버튼을 누르기 전 몇 분의 준비가 이후 수 시간의 정리 작업을 절약할 수 있습니다.
올바른 마이크 선택
마이크 선택은 소음 거부에 큰 영향을 미칩니다.
- 핀(라발리에) 마이크는 화자의 입 가까이에 클립하여, 방 소음 대비 음성 신호를 강하게 유지합니다. 인터뷰와 프레젠테이션에 이상적입니다.
- 지향성(카디오이드 또는 샷건) 마이크는 주로 전면에서 소리를 캡처하고 측면과 후면에서 오는 소리를 거부합니다. 화자를 향하고 소음원에서 멀리 향하게 합니다.
- 전방향 마이크는 모든 방향에서 동일하게 소리를 캡처합니다. 그룹 토론에 유용하지만 더 많은 주변 소음을 포착합니다.
- 헤드셋 마이크는 캡슐을 입 가까이에 위치시키며, 소음이 많은 환경에 탁월합니다. 콜센터와 조종사가 사용하는 이유입니다.
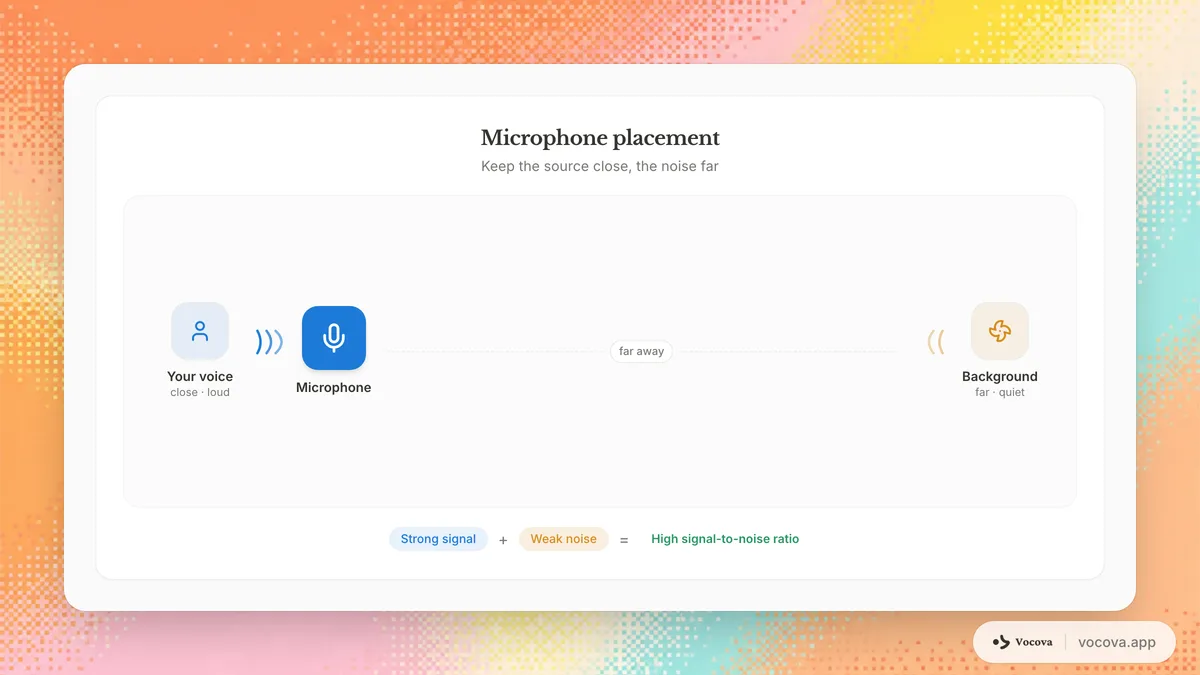
마이크를 올바르게 배치
거리는 대부분의 사람들이 인식하는 것보다 중요합니다. 마이크와 화자 사이의 거리를 두 배로 하면 음성 신호가 약 6dB 감소하는 반면, 배경 소음 수준은 동일하게 유지됩니다. 마이크를 화자에게 실용적으로 가능한 한 가까이 배치하세요.
핀 마이크는 턱 아래 15-20cm에 클립하세요. 데스크 마이크는 화자의 입에서 15-30cm 떨어진 곳에 배치하세요. 컴퓨터 팬, 에어 벤트, 교통량이 많은 도로를 마주하는 창문과 같은 소음원 근처에 마이크를 배치하지 마세요.
방음 처리
상당한 소음과 잔향을 줄이기 위해 전문 스튜디오가 필요하지 않습니다.
- 외부 소음을 차단하기 위해 창문과 문을 닫으세요
- 녹음 중 에어컨, 팬, 불필요한 전자기기를 끄세요
- 에코를 줄이기 위해 부드러운 소재(커튼, 러그, 쿠션 가구)를 추가하세요
- 잔향을 만드는 딱딱하고 평행한 표면(타일 바닥, 유리 벽)이 있는 방을 피하세요
- 사무실에서 녹음하는 경우, 큰 회의실보다 작고 카펫이 깔린 방을 선택하세요
야외에서 윈드스크린 사용
야외에서 녹음하는 경우, 마이크에 폼 윈드스크린이나 털 달린 바람막이("데드 캣"이라 불림)를 사용하세요. 바람 소음은 음성 인식에 극도로 방해가 되며 후처리에서 완전히 제거하기가 거의 불가능합니다.
기준 소음 샘플 녹음
화자가 말하기 전에 방 소음만 10-15초 녹음하세요. 이 "소음 프린트"는 소음의 특성을 학습하고 녹음에서 이를 빼내는 소음 제거 도구에 유용합니다.
음성 인식 정확도에 영향을 미치는 녹음 설정
마이크 선택과 방음 처리 외에도, 몇 가지 기술적인 녹음 설정이 음성 인식 단계까지 얼마나 많은 음성 디테일이 보존되는지를 결정합니다.
샘플 레이트. 대부분의 최신 ASR 모델은 내부적으로 모든 오디오를 16kHz로 리샘플링합니다. 모델이 훈련된 주파수이기 때문입니다. 따라서 더 높은 샘플 레이트는 정확도 이점을 주지 않습니다. 44.1kHz 또는 48kHz로 녹음하는 이유는 호환성과 깔끔한 보관을 위해서이지, 전사 정확도를 높이기 위해서가 아닙니다. 모델에는 16kHz 모노도 이미 충분합니다. 48kHz를 초과해도 음성 인식 이점은 없습니다.
비트 심도. 16비트 또는 24비트로 녹음하세요. 차이는 조용한 부분에서 가장 두드러집니다: 24비트는 더 적은 양자화 잡음으로 작은 음성을 캡처하여, 화자가 마이크에서 더 멀리 있을 때 도움이 됩니다.
모노 대 스테레오. 단일 화자의 경우 모노로 충분하며 더 작은 파일을 생성합니다. 여러 화자의 경우 각 음성을 별도의 채널로 녹음하면 화자 분리가 측정 가능할 정도로 향상되는데, 모델이 구별되고 깨끗한 채널로 도착하는 음성을 분리할 수 있기 때문입니다.
파일 형식. WAV와 FLAC은 무손실이며 음성 인식에 이상적입니다. 192kbps 이상의 MP3도 허용됩니다; AAC/M4A(대부분의 휴대폰에서 사용)는 같은 비트레이트에서 MP3보다 약간 낫습니다; OGG/Opus는 더 낮은 비트레이트에서 좋은 품질을 제공합니다. 저장 공간이 허용한다면 WAV나 FLAC으로 보관하세요. Vocova를 포함한 대부분의 도구는 모든 일반적인 형식을 허용합니다 — 우선순위는 컨테이너가 아니라 녹음 자체의 디테일을 보존하는 것입니다.
마이크 유형과 연결 방식 선택
위의 마이크 가이드는 소음 거부를 위한 지향성에 초점을 맞췄습니다. 두 가지 추가 선택이 모든 녹음의 기본 품질을 결정합니다.
- 콘덴서 대 다이내믹. 콘덴서 마이크는 더 민감하고 더 많은 음성 디테일을 캡처하여 조용하고 통제된 방에서 도움이 됩니다 — 하지만 더 많은 주변 소음도 포착합니다. 다이내믹 마이크는 설계상 더 많은 배경 소음을 거부하여, 방음 처리되지 않았거나 소음이 있는 공간에서 더 안전한 선택입니다.
- USB 대 XLR. USB 마이크(예: Rode NT-USB Mini 또는 Audio-Technica AT2020USB+)는 내장 오디오 인터페이스를 포함하며 대부분의 사람들에게 실용적인 선택입니다. XLR 마이크는 별도의 인터페이스가 필요하지만 더 낮은 노이즈 플로어와 더 많은 제어를 제공합니다 — 주로 이미 인터페이스를 가지고 있다면 그만한 가치가 있습니다.
음성 인식의 경우, 특정 마이크보다 환경이 더 중요합니다. 조용한 방에 올바르게 배치된 $50–100 USB 마이크는 음성 인식 수준의 오디오를 생성합니다.
특정 녹음 시나리오를 위한 팁
- 회의: 노트북 마이크 대신 테이블 중앙에 전용 회의용 마이크(예: Jabra Speak 또는 Anker PowerConf)를 사용하세요. 원격 회의의 경우, 회의 소프트웨어의 오디오 출력을 직접 녹음하고 참가자에게 에코를 피하기 위해 헤드셋을 착용하도록 요청하세요.
- 인터뷰: 인터뷰 진행자와 인터뷰 대상자에게 별도의 마이크를 제공하세요 — 이상적으로는 별도의 채널로 녹음되는 무선 핀 마이크가 좋습니다. 통화 인터뷰의 경우, 스피커폰에 마이크를 향하게 하기보다 소프트웨어를 통해 녹음하세요.
- 강의: 발표자에게 핀 마이크를 다는 것이 가장 신뢰할 수 있는 설정입니다. 청중 오디오는 깨끗하게 캡처되는 경우가 드물기 때문에, 발표자가 답변하기 전에 청중의 질문을 반복하도록 하세요.
- 팟캐스트: 각 진행자와 게스트에게 별도의 트랙으로 자신만의 마이크를 제공하세요. 원격 녹음의 경우, 각 참가자가 로컬에서 녹음(Riverside.fm나 Zencastr 같은 도구로)하고 이후 트랙을 결합하여 화상 통화 압축 아티팩트를 피하세요.
음성 인식을 해치는 일반적인 녹음 실수
- 주머니나 가방 안의 휴대폰. 천은 자음을 구별하는 데 필요한 고주파를 묻히게 하고, 움직임은 바스락거리는 소음을 더합니다. 휴대폰을 화자를 향하게 안정적인 표면에 놓으세요.
- 마이크에서 너무 멀리 앉기. 거리는 음성 신호를 약화시키는 반면 배경 소음은 일정하게 유지되어, 녹음이 결국 소음이 지배하게 됩니다. 가까이 있으세요.
- 게인이 너무 높게 설정됨. 클리핑은 복구할 수 없는 영구적인 왜곡입니다. 일반적인 음성이 -12dB에서 -6dB 정도에서 피크가 되도록 레벨을 설정하세요.
- 게인이 너무 낮게 설정됨. 너무 조용하게 녹음하면 나중에 증폭해야 하는데, 이는 노이즈 플로어도 증폭합니다.
- 블루투스로 녹음. 핸즈프리 블루투스 프로필은 통화 오디오를 심하게 압축합니다. 가능한 한 녹음에는 유선 연결을 사용하세요.
- 테스트 녹음 없음. 실제 세션 전에 30초를 녹음하고 재생해 보세요. 방 에코, 험, 핸들링 노이즈를 미리 잡아내는 것이 두 시간짜리 녹음 후에 발견하는 것보다 훨씬 저렴합니다.
음성 인식 전에 소음이 있는 오디오를 정리하는 방법
이미 소음이 있는 녹음이 있다면, 오디오 처리 도구로 전사 서비스에 보내기 전에 신호 품질을 개선할 수 있습니다. 결과가 깨끗한 원본 녹음과 같지는 않지만 도움이 될 수 있습니다.
놀랍지만 중요한 주의점: 노이즈 제거가 AI 전사에 항상 도움이 되지는 않습니다. Whisper 계열 모델은 불완전한 오디오도 많이 포함해 학습되었습니다. 2025-2026년 여러 연구(예를 들어 When De-noising Hurts, 2025와 When Denoising Hinders, 2026)에서는 음성 향상과 노이즈 제거 도구가, 사람이 듣기에는 더 깨끗하게 들리더라도, 단어 오류율을 실제로 높이는 경우가 있었습니다. 처리 과정이 모델이 학습하지 않은 아티팩트를 만들기 때문입니다. 신뢰할 수 있는 규칙은 간단합니다. 짧은 샘플을 원본과 처리본 두 가지로 전사한 뒤, 더 나은 쪽을 사용하세요. 의외로 원본 오디오가 이기는 경우가 많습니다. 아래 도구들은 안정적이고 특성이 뚜렷한 소음에 가장 도움이 되며, 말소리와 비슷한 간섭이나 잔향에는 덜 도움이 되고 오히려 해칠 수 있습니다.
Audacity (무료, 오픈소스)
Audacity는 내장 소음 제거 도구가 있는 무료 오디오 편집기입니다.
- 소음만 포함된(음성 없는) 오디오 부분을 선택
- Effect > Noise Reduction > Get Noise Profile로 이동
- 전체 오디오 트랙 선택
- 약 12dB 감소, 6 민감도, 3 주파수 스무딩 설정으로 Noise Reduction 적용
- 결과를 미리 듣고 음성이 왜곡되면 조정
Audacity에는 바람이나 HVAC 시스템의 저주파 럼블을 제거할 수 있는 고주파 필터(Effect > Filter Curve)도 있습니다. 음성 녹음의 경우 80-100Hz 이하의 주파수를 잘라내세요.
Adobe Podcast Enhance Speech (무료, 웹 기반)
Adobe는 AI를 사용하여 음성 녹음을 향상시키는 무료 온라인 도구를 제공합니다. 오디오 파일을 업로드하면 도구가 음성을 분리하고, 소음을 줄이며, 볼륨을 정규화하려고 시도합니다. 보통 수준의 소음에서 잘 작동하며 기술적이지 않은 사용자에게도 충분히 간단합니다. 제한은 파일 크기 제한과 세밀한 제어 없이 전체 파일을 처리한다는 점입니다.
iZotope RX
iZotope RX는 방송 및 영화 후반 작업에서 사용되는 전문 오디오 수리 도구입니다. 소음 감소, 잔향 제거, 클릭 제거, 험 제거, 대화 분리를 위한 고급 도구를 제공합니다. 가장 유능한 옵션이지만 상당한 학습 곡선과 비용이 따릅니다. 어려운 오디오를 다루는 정기적인 음성 인식 작업에는 투자할 가치가 있습니다.
오디오 정리를 위한 일반 팁
- 소음 제거를 보수적으로 적용하세요. 공격적인 설정은 소음을 제거하지만 금속적인 떨림처럼 들리는 아티팩트를 도입합니다. 이 아티팩트는 원래 소음만큼이나 ASR 모델을 혼란스럽게 할 수 있습니다.
- 80Hz 미만의 럼블을 제거하기 위해 고주파 필터를 사용하세요. 사람의 음성은 이 주파수 이하에 의미 있는 정보를 포함하지 않습니다.
- 음성 피크가 -3dB에서 -6dB 정도가 되도록 오디오 레벨을 정규화하세요. ASR 모델은 일관된 볼륨 레벨에서 더 잘 수행됩니다.
- 다이내믹 레인지를 과도하게 압축하지 마세요. 약간의 압축은 속삭임이나 외침에 도움되지만, 과도한 압축은 노이즈 플로어를 높입니다.
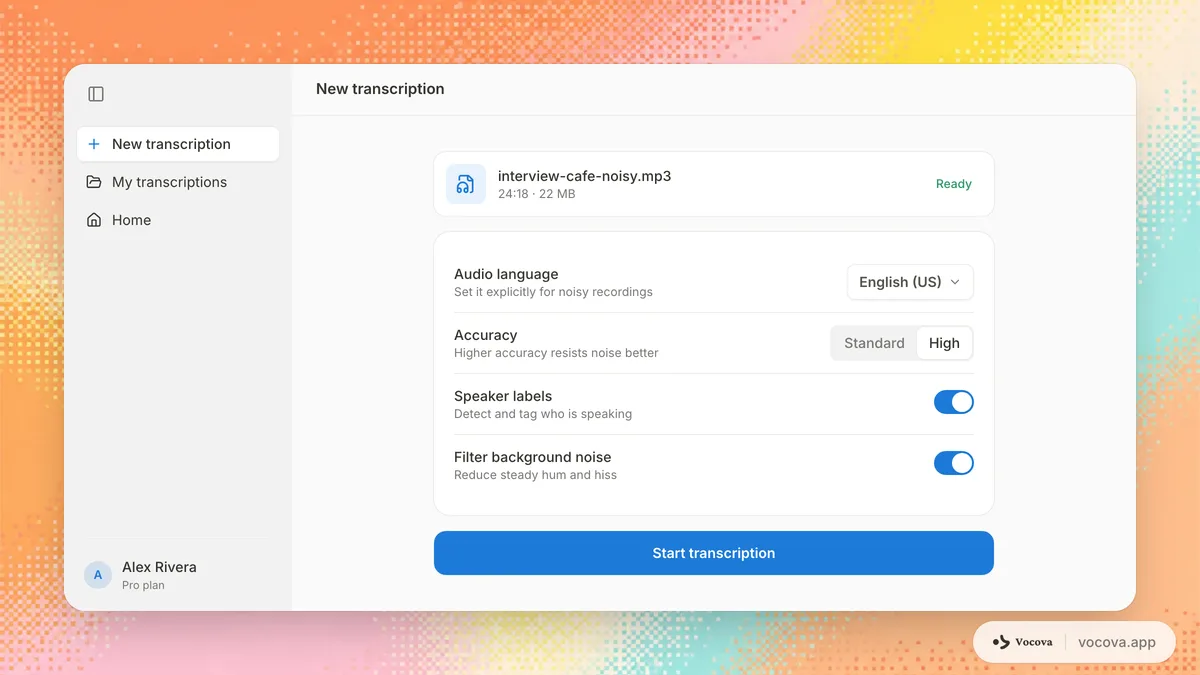
소음이 있는 오디오를 위한 AI 음성 인식 설정
가능한 한 오디오를 정리한 후, 올바른 음성 인식 설정이 정확도를 더 향상시킬 수 있습니다.
언어 지정
대부분의 ASR 시스템은 자동 감지에 의존하기보다 발화 언어를 지정할 때 더 잘 수행됩니다. 자동 감지는 소음이 있는 오디오에서 잘못될 수 있는 추가 추론 단계를 추가하여, 잘못된 언어 모델을 선택할 가능성이 있습니다. 언어를 알고 있다면 명시적으로 설정하세요.
올바른 모델 티어 선택
많은 전사 서비스가 여러 모델 티어를 제공하며, 더 높은 정확도 티어는 보통 음성과 간섭을 분리할 용량이 더 큰 모델을 사용하므로 소음을 더 잘 처리합니다. 제공업체에 그런 티어가 있다면 어려운 샘플에서 시험해 볼 가치가 있습니다. 직접 가진 클립은 오디오 텍스트 변환 도구로 테스트할 수 있습니다.
화자 분리를 신중하게 사용
화자 분리, 즉 누가 무엇을 말했는지 식별하는 과정은 화자 간의 음향적 차이를 감지하는 데 의존합니다. 배경 소음은 이러한 차이를 가려, 분리 모델이 한 화자를 여러 라벨로 분할하거나 다른 화자를 하나로 병합하게 할 수 있습니다. 오디오에 소음이 있고 분리 결과가 신뢰할 수 없어 보이면, 분리 없이 음성 인식한 후 화자 라벨을 수동으로 추가하는 것이 더 나은 결과를 얻을 수 있습니다.
긴 녹음을 세그먼트로 분할
긴 녹음의 일부분만 소음이 있다면, 파일을 세그먼트로 분할하여 개별적으로 음성 인식하는 것을 고려하세요. 이는 소음이 있는 부분이 깨끗한 부분의 모델 성능에 영향을 미치는 것을 방지합니다. 소음 특성에 따라 다른 세그먼트에 다른 소음 제거 설정을 적용할 수도 있습니다.
음성 인식 후 정리 팁
최적의 오디오 준비와 음성 인식 설정에도 불구하고, 소음이 있는 녹음은 수동 검토가 필요한 텍스트를 생성합니다. 효율적인 정리를 위한 전략은 다음과 같습니다.
오류가 많은 섹션을 먼저 집중
텍스트와 함께 오디오를 들으며 음성 인식이 실제 발화에서 가장 많이 벗어나는 섹션을 식별하세요. 이들은 보통 소음 수준이 가장 높은 순간입니다. 전체 텍스트를 순차적으로 읽기보다 이 섹션을 먼저 수정하는 것을 우선시하세요.
타임스탬프를 사용하여 탐색
단어 수준 또는 세그먼트 수준 타임스탬프를 제공하는 음성 인식 도구를 사용하면 관련 오디오 위치로 직접 클릭할 수 있습니다. 이는 수동으로 오디오를 스크러빙하는 것에 비해 개별 단어를 확인하고 수정하는 것을 훨씬 빠르게 만듭니다. Vocova는 각 세그먼트에 타임스탬프를 제공하여 녹음의 어떤 지점으로든 직접 이동할 수 있습니다.
소음으로 인한 일반적인 오류 주의
소음이 있는 오디오는 특징적인 음성 인식 오류를 만듭니다:
- 모델이 소음을 음성으로 해석하여 삽입된 유령 단어
- 소음이 음성 신호를 완전히 가린 누락된 단어
- 소음이 구별하는 소리를 가려 모델이 비슷한 소리의 단어를 선택한 동음이의어 및 유사 오류
- 이름과 전문 용어는 문맥에서 예측하기 어렵기 때문에 발생하는 변질된 고유 명사
체계적인 오류에 찾기-바꾸기 사용
모델이 녹음 전체에서 특정 용어를 일관되게 잘못 변환하는 경우(사람 이름, 회사 이름, 기술 용어), 개별적으로 수정하기보다 찾기-바꾸기를 사용하여 모든 인스턴스를 한 번에 수정하세요.
번역과 함께 두 번째 패스 고려
원본 텍스트에 상당한 오류가 있고 번역된 버전도 필요한 경우, 소스 텍스트를 먼저 수정하는 것이 중요합니다. 번역 모델은 소스 텍스트의 오류를 전파하고 때로는 증폭합니다. 번역하기 전에 텍스트를 정리하세요.
소음이 있는 오디오가 구제 불가능한 경우
아무리 소음 제거나 AI 튜닝을 해도 사용 가능한 텍스트를 생성할 수 없는 상황이 있습니다. 이러한 경우를 일찍 인식하면 시간과 좌절을 절약합니다.
오디오가 구제 불가능할 수 있는 징후:
- 헤드폰을 끼고 주의 깊게 들어도 직접 음성을 이해할 수 없는 경우
- 여러 화자가 확실한 주도적 음성 없이 장시간 동시에 말하는 경우
- SNR이 5dB 미만으로, 소음이 음성과 거의 같거나 더 큰 경우
- 심한 클리핑(녹음 레벨이 너무 높아 발생한 왜곡)이 파형을 영구적으로 손상시킨 경우
- 심한 잔향으로 음성이 터널이나 계단통에서 녹음된 것처럼 들리는 경우
AI 음성 인식이 실패했을 때의 옵션
- 문맥적 단서, 립리딩(비디오가 있는 경우), 주제 전문성을 사용하여 어려운 오디오를 해독할 수 있는 전문가에 의한 사람 음성 인식. 더 느리고 비용이 많이 들지만 AI가 할 수 없는 엣지 케이스를 처리합니다. 더 깊은 비교는 AI vs 사람 음성 인식 가이드를 참조하세요.
- 가능하다면 재녹음. 콘텐츠가 허용한다면, 더 나은 장비와 환경으로 새 녹음 세션을 예약하는 것이 심각하게 열화된 녹음을 구제하려는 것보다 종종 더 빠릅니다.
- 부분 음성 인식. 수용 가능한 오디오 품질의 섹션을 음성 인식하고 갈 수 없는 곳에 공백을 표시합니다. [불분명] 섹션이 명확하게 표시된 텍스트가 잘못된 추측으로 가득 찬 텍스트보다 더 유용합니다.
자주 묻는 질문
음성 인식 정확도에 가장 큰 영향을 미치는 요소는 무엇인가요?
신호 대 잡음비입니다. 배경 소음에 비해 음성이 클수록, AI든 사람이든 모든 음성 인식 도구가 단어를 더 정확하게 식별할 수 있습니다. 조용한 방에서 가까이 배치된 마이크가 최고의 결과를 생성합니다. 이를 가장 빠르게 높이는 방법은 위의 녹음 설정, 마이크 선택, 배경 소음 줄이기에 관한 섹션을 참조하세요.
AI 음성 인식 도구는 배경 음악을 처리할 수 있나요?
보통 수준으로 가능합니다. 음악이 조용하고 음성이 깨끗하면 대부분의 최신 ASR 모델이 음성 인식할 수 있습니다. 큰 음악, 특히 보컬이 있는 경우 모델이 대상 음성과 노래를 안정적으로 구별할 수 없기 때문에 상당한 정확도 문제를 일으킵니다. 낮은 볼륨의 기악 배경 음악은 어떤 볼륨의 보컬 음악보다 덜 방해가 됩니다.
음성 인식용 오디오를 업로드하기 전에 소음 제거를 사용해야 하나요?
자동으로 적용하지 말고 먼저 테스트하세요. 깨끗하게 들리는 오디오가 더 잘 전사될 것 같지만, Whisper 같은 최신 AI 모델은 소음이 있는 데이터로도 학습되었습니다. 2025-2026년 연구에서는 노이즈 제거와 음성 향상이 사람이 듣기에는 더 좋아도, 처리 아티팩트 때문에 단어 오류율을 자주 높였습니다. 믿을 수 있는 방법은 짧은 샘플을 원본과 노이즈 제거본으로 각각 전사하고 더 정확한 쪽을 쓰는 것입니다. 노이즈 제거를 한다면 부드럽게 적용하세요. 공격적인 설정은 금속성 아티팩트를 만들어 도움이 되기보다 해롭습니다.
소음이 있는 오디오에서 언어를 지정하면 정확도가 향상되나요?
네. 수동으로 언어를 설정하면 ASR 모델이 처음부터 올바른 어휘와 언어 모델을 사용합니다. 소음이 있는 오디오에서 자동 감지 단계는 언어를 잘못 식별할 가능성이 더 높아, 전체 음성 인식에 잘못된 모델을 적용합니다. 언어를 알고 있다면 항상 지정하세요.
오디오 품질은 단어 오류율에 얼마나 영향을 미치나요?
상당히 영향을 미칩니다. 다만 정확한 숫자는 모델, 언어, 소음 유형에 따라 달라지므로 측정 보장이 아니라 대략적인 예시로 보세요. 깨끗한 스튜디오 오디오는 최신 ASR에서 WER 5% 미만에 머무는 경우가 많고, 사무실 소음이나 가벼운 교통 소음은 낮은 두 자릿수로 올라가는 경향이 있습니다. 붐비는 레스토랑이나 건설 현장은 30%를 넘길 수 있습니다. 관계는 선형이 아니며, SNR이 약 15dB 아래로 떨어지면 정확도가 빠르게 나빠집니다. 깨끗한 오디오 기준선 자체가 언어별로 얼마나 다른지는 언어별 전사 정확도를 참고하세요.
소음이 있는 오디오를 AI와 사람 전사자 중 어디에 맡기는 것이 더 좋은가요?
보통 수준의 소음 오디오에는 AI 도구가 보통 충분하고 훨씬 빠릅니다. 주의 깊게 들어도 어려운 심하게 열화된 오디오에는 숙련된 사람 전사자가 일반적으로 AI를 능가하는데, 문맥적 추론, 주제 지식, 비디오의 시각적 단서를 사용하여 격차를 메울 수 있기 때문입니다. AI와 사람 음성 인식의 비교는 구체적인 소음 조건과 정확도 요구 사항에 따라 크게 달라집니다.
음성 인식에 가장 좋은 오디오 형식은 무엇인가요?
WAV와 FLAC이 가장 좋은데, 무손실이며 전체 오디오 디테일을 보존하기 때문입니다. 실제로는 192kbps 이상의 MP3도 잘 작동합니다. 대부분의 AI 음성 인식 도구는 모든 일반적인 형식을 허용하므로, 우선순위는 특정 컨테이너 형식을 걱정하기보다 높은 비트레이트로 녹음하는 것입니다.
음성 인식을 위해 비싼 마이크를 살 가치가 있나요?
대개 그렇지 않습니다. 올바르게 배치된 조용한 방의 $50–100 USB 마이크는 음성 인식 수준의 오디오를 생성합니다. 비싼 마이크는 음성 풍부함을 더하지만, 이는 음성-텍스트 변환 정확도보다 음악과 방송에 더 중요합니다. 마이크 자체를 업그레이드하기 전에 방음 처리와 마이크 배치에 투자하세요.
출처 및 추가 자료
- Chondhekar et al., "When De-noising Hurts: A Systematic Study of Speech Enhancement Effects on Modern Medical ASR Systems" (arXiv, 2025) -- 음성이 더 깨끗하게 들리더라도 음성 향상이 Whisper 계열 모델의 단어 오류율을 높일 수 있음을 보고
- Islam, Nahar & Hamid, "When Denoising Hinders: Revisiting Zero-Shot ASR with SAM-Audio and Whisper" (arXiv, 2026)
- Mu et al., "Performance evaluation of automatic speech recognition systems on integrated noise-network distorted speech", Frontiers in Signal Processing (2022) -- WER과 SNR의 관계
- Hugging Face Audio Course -- preprocessing -- 최신 ASR 모델이 16kHz 오디오를 전제로 하는 이유
- Engineering ToolBox -- inverse-square law -- 거리가 두 배가 될 때마다 약 6dB 감소한다는 경험칙
- National Center for Voice and Speech -- fundamental frequency -- 80-100Hz 하이패스 컷오프를 이해하기 위한 배경
