如何轉錄嘈雜音訊並降低背景噪音造成的錯誤(2026)
背景噪音是轉錄錯誤的最大原因。本指南說明如何錄到更乾淨的音訊、哪些設定真正重要、轉錄前何時該降噪或不該降噪,以及如何處理已無法挽救的音訊。
背景噪音是轉錄錯誤的最大單一原因。即使是最先進的 AI 語音辨識模型,在音訊信號與交通聲、空調嗡嗡聲、交叉對話或房間迴音競爭時也會遇到困難。在安靜房間中幾乎能完美轉錄的錄音,在嘈雜環境中可能大幅劣化,使原本有用的逐字稿變成需要大量手動修正的內容。
好消息是,大多數嘈雜音訊問題要嘛是可以預防的,要嘛是可以修復的。本指南涵蓋完整的流程:如何一開始就錄製更乾淨的音訊、如何在轉錄前處理嘈雜的錄音、如何設定轉錄參數以獲得最佳結果,以及如何處理音訊確實無法挽救的情況。
為什麼背景噪音影響轉錄準確度
要理解噪音為什麼導致轉錄錯誤,有助於了解自動語音辨識(ASR)的基本運作原理。
ASR 模型透過分析聲音的聲學特性來將音訊轉換為文字,將信號分解為小的時間窗口,並在每個時間點預測最可能的字詞或音素。模型已在數千小時的語音上訓練,並學習了區分不同字詞的統計模式。
背景噪音透過添加不對應語音的聲學能量來干擾這個過程。當風扇噪音或人群嘈雜聲佔據與說話者聲音相同的頻率範圍時,模型無法乾淨地分離這兩個信號。它做出最佳猜測,但隨著噪音程度增加,這些猜測變得越來越不可靠。
這個技術術語是信噪比(SNR)。SNR 衡量語音信號比背景噪音大多少,以分貝表示。30 dB 或更高的 SNR(語音比噪音大很多)能產生好的轉錄結果。低於 10 dB 的 SNR(語音僅比噪音略大)則導致顯著的準確度損失。這種損失是陡峭的,不是平滑漸進的:隨著 SNR 下降,錯誤率會急遽攀升,這也是為什麼麥克風距離稍微遠一點,或一台空調持續運轉,就能讓準確度崩掉。
轉錄準確度通常使用字詞錯誤率(WER)來衡量。安靜、錄音品質良好的訪談可能低於 5% WER;同樣的對話若在繁忙咖啡廳錄製,可能超過 20-25%。實際數字取決於模型、語言與噪音類型;若想了解乾淨音訊的基準本身在不同語言間差多少,請參考各語言轉錄準確度。但這裡的落差幾乎完全歸因於噪音。
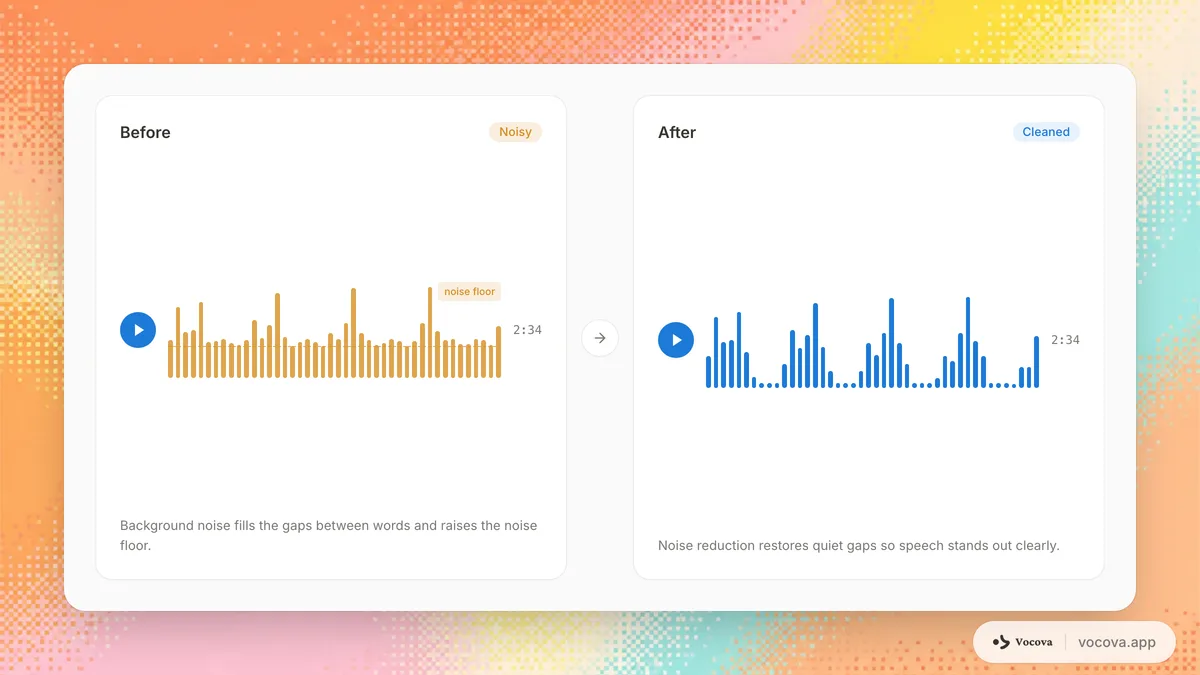
音訊噪音的類型
並非所有噪音對轉錄的影響都相同。了解錄音中的噪音類型有助於您選擇正確的處理方式。
環境噪音
空調、交通、風扇或冰箱嗡嗡聲等持續的背景聲音。這類噪音在音量和頻率上相對一致,使其成為最容易用噪音消除工具移除的類型。但是,如果聲音足夠大,仍然會降低轉錄準確度。
電子噪音
錄音設備本身引入的嘶嘶聲、嗡嗡聲或雜音。常見原因包括低品質麥克風、有線設置中的接地迴路、附近電子設備的電磁干擾,以及高底噪的音訊介面。電子噪音通常是一致的,可以用噪音消除處理。
殘響
聲音在房間硬表面彈跳產生的迴音。殘響使語音信號在時間上模糊,使 ASR 模型更難辨識字詞邊界。在磁磚浴室或空會議室中的說話者會產生比在鋪地毯、有家具的辦公室中明顯更多的殘響。殘響比環境噪音更難移除,因為它是原始信號的變形版本。
交叉對話和重疊語音
多人同時說話。這是對轉錄來說最困難的噪音類型之一,因為干擾信號本身也是語音,模型難以分離兩個說話者。交叉對話通常出現在會議、座談和團體訪談中。
風噪
空氣運動穿過麥克風產生的低頻隆隆聲。風噪在戶外錄音中很常見,在強風中可以完全遮蓋語音。它主要影響頻譜的低端,通常可以用高通濾波器或防風罩來減輕。
脈衝噪音
突然的、短時間的聲音,如鍵盤點擊、翻紙、咳嗽或建築撞擊聲。這些聲音短暫但可能損壞個別字詞或短語。ASR 模型可能將尖銳的點擊聲誤解為輔音,在逐字稿中插入幻影字詞。
錄音前獲得更乾淨音訊的技巧
從嘈雜環境中獲得準確轉錄最有效的方法是一開始就捕捉更好的音訊。錄音前幾分鐘的準備可以節省事後幾小時的清理工作。
選擇正確的麥克風
麥克風選擇對噪音抑制有重大影響。
- 領夾式(胸針)麥克風夾在靠近說話者嘴巴的位置,保持語音信號相對於房間噪音的強度。它們適合訪談和簡報。
- 指向性(心形或槍式)麥克風主要從前方捕捉聲音,抑制側面和後方的聲音。將它們對準說話者,遠離噪音來源。
- 全向麥克風從所有方向均等地捕捉聲音。它們適合團體討論,但會拾取更多環境噪音。
- 耳機式麥克風將麥克風置於靠近嘴巴的位置,非常適合嘈雜環境——這就是為什麼客服中心和飛行員使用它們。
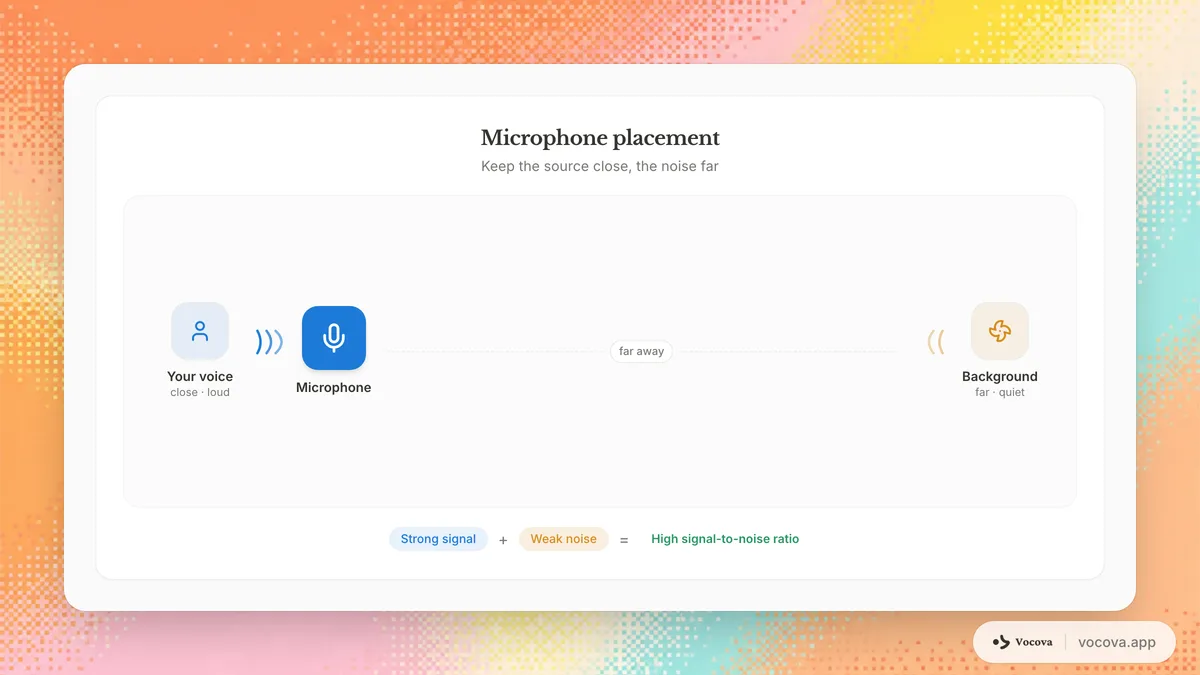
正確放置麥克風
距離比大多數人意識到的更重要。麥克風和說話者之間的距離翻倍會使語音信號減少約 6 dB,而背景噪音程度保持不變。盡可能將麥克風靠近說話者。
領夾式麥克風應夾在下巴以下 15-20 公分處。桌上麥克風應放在距說話者嘴巴 15-30 公分處。避免將麥克風放在電腦風扇、通風口或面向繁忙街道的窗戶等噪音來源附近。
處理房間
您不需要專業錄音室也能顯著減少噪音和殘響。
- 關閉窗戶和門以阻擋外部噪音
- 錄音期間關閉空調、風扇和不必要的電子設備
- 添加柔軟材料(窗簾、地毯、軟墊家具)以減少迴音
- 避免有硬質平行表面(磁磚地板、玻璃牆)的房間,因為它們會產生殘響
- 如果在辦公室錄音,選擇較小的鋪地毯房間而非大會議室
戶外使用防風罩
如果您在戶外錄音,請在麥克風上使用泡棉防風罩或毛絨防風套(通常稱為「dead cat」)。風噪對轉錄有極大的干擾,在後製中幾乎不可能完全移除。
錄製參考噪音樣本
在說話者開始說話前,錄製 10 到 15 秒的純房間噪音。這個「噪音指紋」對噪音消除工具很有用,工具會用它來學習噪音的特性並從錄音中減去它。
影響轉錄準確度的錄音設定
除了麥克風選擇和房間處理之外,有幾項技術性的錄音設定決定了有多少人聲細節能保留到轉錄階段。
取樣率。 多數現代 ASR 模型都會在內部把音訊重新取樣到 16 kHz——也就是它們訓練時使用的取樣率——因此更高的取樣率不會帶來準確度提升。使用 44.1 kHz 或 48 kHz 錄製是為了相容性與乾淨封存,不是為了提高轉錄準確度;對模型而言,16 kHz 單聲道已經足夠。48 kHz 以上對語音辨識沒有好處。
位元深度。 以 16-bit 或 24-bit 錄製。差異在安靜段落最為明顯:24-bit 以更少的量化噪音捕捉柔和的語音,當說話者距離麥克風較遠時會有幫助。
單聲道 vs 立體聲。 對於單一說話者,單聲道就夠了,而且檔案更小。對於多位說話者,將每個聲音錄製到獨立的聲道能明顯改善說話者分離,因為模型可以分離抵達不同、乾淨聲道的聲音。
檔案格式。 WAV 和 FLAC 是無損的,最適合轉錄。192 kbps 或更高的 MP3 可以接受;AAC/M4A(大多數手機使用)在相同位元率下略優於 MP3;OGG/Opus 在較低位元率下提供良好品質。如果儲存空間允許,請以 WAV 或 FLAC 封存。包括 Vocova 在內的大多數工具都接受所有常見格式——重點是保留錄音本身的細節,而非容器格式。
選擇麥克風類型與連接方式
上述麥克風指引著重於用指向性來抑制噪音。另外兩個選擇則決定了任何錄音的基礎品質。
- 電容式 vs 動圈式。 電容式麥克風更敏感,能捕捉更多人聲細節,在安靜、受控的房間中會有幫助——但它們也會拾取更多環境噪音。動圈式麥克風的設計本身就能抑制更多背景噪音,在未經處理或嘈雜的空間中是更穩妥的選擇。
- USB vs XLR。 USB 麥克風(例如 Rode NT-USB Mini 或 Audio-Technica AT2020USB+)內建音訊介面,對大多數人來說是務實的選擇。XLR 麥克風需要獨立的介面,但提供更低的底噪和更多控制——主要在您已經擁有介面的情況下才值得。
對於轉錄而言,環境比特定麥克風更重要。一支放置正確、置於安靜房間中的 50–100 美元 USB 麥克風就能產生轉錄等級的音訊。
特定錄音情境的技巧
- 會議: 在桌子中央使用專用的會議麥克風(如 Jabra Speak 或 Anker PowerConf),而非筆電麥克風。對於遠端會議,直接錄製會議軟體的音訊輸出,並請與會者配戴耳機以避免迴音。
- 訪談: 給訪問者和受訪者各自的麥克風——理想情況下是錄製到獨立聲道的無線領夾式麥克風。對於電話訪談,透過軟體錄製,而非將麥克風對著免持聽筒。
- 講座: 在主講人身上配戴領夾式麥克風是最可靠的設置。讓主講人在回答前重複聽眾的問題,因為聽眾的音訊很少能被乾淨地捕捉到。
- Podcast: 給每位主持人和來賓各自的麥克風,錄製在獨立的音軌上。對於遠端錄製,讓每位參與者在本地錄製(使用 Riverside.fm 或 Zencastr 等工具),事後再合併音軌,以避免視訊通話的壓縮偽影。
損害轉錄的常見錄音錯誤
- 手機放在口袋或包包裡。 布料會悶住區分輔音所需的高頻,而且移動會增加摩擦的雜音。將手機放在穩定的表面上,面向說話者。
- 坐得離麥克風太遠。 距離會削弱語音信號,而背景噪音保持不變,因此錄音最終會由噪音主導。保持靠近。
- 增益設定太高。 削波是無法修復的永久性失真。將音量設定為使正常語音的峰值約在 -12 dB 到 -6 dB。
- 增益設定太低。 錄得太小聲會迫使您事後放大,這也會放大底噪。
- 透過藍牙錄音。 免持藍牙設定檔會大幅壓縮通話音訊。錄音時盡可能使用有線連接。
- 沒有測試錄音。 在正式作業前先錄製並播放 30 秒。事先發現房間迴音、嗡嗡聲或操作噪音,遠比錄製兩小時後才發現便宜得多。
如何在轉錄前清理嘈雜音訊
如果您已經有了嘈雜的錄音,音訊處理工具可以在傳送到轉錄服務之前改善信號品質。結果不會比乾淨的原始錄音好,但可能有幫助。
一個常讓人意外的提醒:降噪不一定有助於 AI 轉錄。 Whisper 類模型接受過大量不完美音訊訓練,而多項 2025-2026 年研究(例如 When De-noising Hurts,2025,以及 When Denoising Hinders,2026)發現,語音增強與降噪工具有時反而會提高字詞錯誤率,即使人耳聽起來更乾淨也是如此,因為處理過程會引入模型訓練時沒見過的偽影。可靠做法是:取一小段樣本,原始版與處理版都轉錄,保留結果較準的那個。 出乎意料地,勝出的常常是原始音訊。以下工具最適合穩定、特徵明確的噪音;對類似語音的干擾與殘響幫助最少,甚至可能造成傷害。
Audacity(免費、開源)
Audacity 是一個免費的音訊編輯器,內建噪音消除工具。
- 選擇音訊中僅包含噪音(沒有語音)的部分
- 前往 Effect > Noise Reduction > Get Noise Profile
- 選擇整個音訊軌道
- 應用噪音消除,設定約 12 dB 消除量、6 靈敏度和 3 頻率平滑
- 預覽結果,如果語音聽起來失真則調整
Audacity 也有高通濾波器(Effect > Filter Curve),可以移除風或空調系統的低頻隆隆聲。對語音錄音剪切 80-100 Hz 以下的頻率。
Adobe Podcast Enhance Speech(免費、網頁式)
Adobe 提供一個免費的線上工具,使用 AI 增強語音錄音。上傳您的音訊檔案,工具會嘗試隔離語音、降低噪音和正規化音量。它對中度噪音水準效果很好,對非技術使用者來說足夠簡單。限制是有檔案大小上限,且它在沒有精細控制的情況下處理整個檔案。
iZotope RX
iZotope RX 是用於廣播和電影後製的專業音訊修復套件。它提供噪音消除、消殘響、消雜聲、消嗡聲和對話隔離的進階工具。它是最有能力的選項,但學習曲線和成本都很高。對於經常處理挑戰性音訊的轉錄工作,值得投資。
音訊清理的一般技巧
- 保守地應用噪音消除。 激進的設定會移除噪音但引入像金屬顫音般的偽影。這些偽影可能像原始噪音一樣混淆 ASR 模型。
- 使用高通濾波器移除 80 Hz 以下的隆隆聲。人類語音在此頻率以下不包含有意義的資訊。
- 正規化音訊音量,使語音峰值在約 -3 dB 到 -6 dB。ASR 模型在音量一致時表現更好。
- 不要過度壓縮動態範圍。 一些壓縮有助於處理耳語或喊叫語音,但重度壓縮會提高底噪。
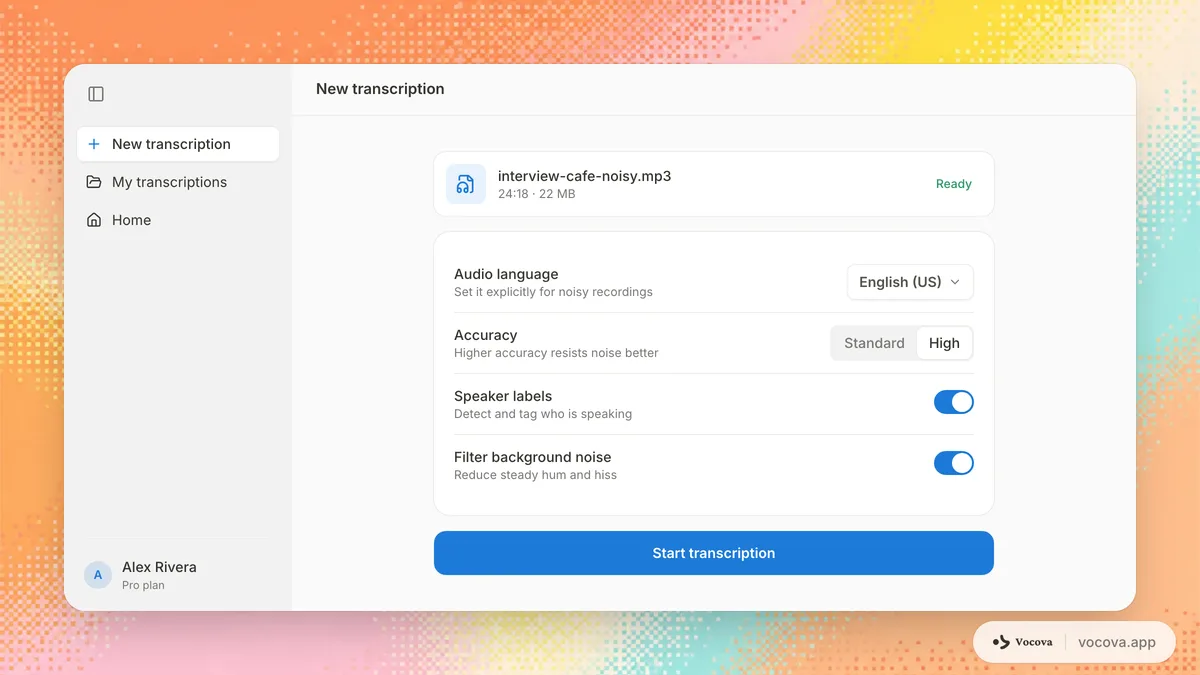
嘈雜音訊的 AI 轉錄設定
一旦您盡可能清理了音訊,正確的轉錄設定可以進一步提升準確度。
指定語言
大多數 ASR 系統在您指定口說語言時表現更好,而非依賴自動偵測。自動偵測增加了額外的推理步驟,在嘈雜音訊中可能出錯,可能選擇錯誤的語言模型應用於整個轉錄。如果您知道語言,明確設定它。
選擇正確的模型層級
許多轉錄服務提供多個模型層級,而較高準確度層級通常更能處理噪音,因為它們使用更大的模型,有更多能力分離語音和干擾。如果您的服務商有這類層級,很值得拿困難樣本測試;您也可以用自己的片段在音訊轉文字工具中試跑。
謹慎使用說話者分離
說話者分離——辨識誰說了什麼的過程——依賴於偵測說話者之間的聲學差異。背景噪音可能遮蓋這些差異,導致分離模型將一個說話者分成多個標籤或將不同說話者合併為一個。如果您的音訊嘈雜且分離結果看起來不可靠,您可能會得到更好的結果:不使用分離進行轉錄,然後手動添加說話者標籤。
將長錄音分段
如果長錄音中只有部分是嘈雜的,考慮將檔案分段並分別轉錄。這可以防止嘈雜的部分影響模型在較乾淨部分的表現。您還可以根據不同段落的噪音特性應用不同的噪音消除設定。
轉錄後的清理技巧
即使有最佳的音訊準備和轉錄設定,嘈雜的錄音仍會產生需要人工審閱的逐字稿。以下是高效清理的策略。
首先處理高錯誤區段
邊聽音訊邊閱讀逐字稿,辨識轉錄與實際語音差異最大的區段。這些通常是噪音水準最高的時刻。優先修正這些區段,而非線性閱讀整個逐字稿。
使用時間戳記導航
提供字詞級或段落級時間戳記的轉錄工具讓您直接點擊到相關的音訊位置。這比手動拖曳音訊快得多,可以驗證和修正個別字詞。Vocova 為每個段落提供時間戳記,讓您直接跳到錄音中的任何位置。
注意常見的噪音引起錯誤
嘈雜音訊會產生特徵性的轉錄錯誤:
- 幻影字詞——模型將噪音解讀為語音而插入的字詞
- 遺漏字詞——噪音完全遮蓋語音信號的地方
- 同音字和近似字——模型選擇了發音類似的字詞,因為噪音模糊了區別聲音
- 混亂的專有名詞——因為名稱和技術術語從上下文中較難預測
使用搜尋和取代處理系統性錯誤
如果模型在整個錄音中一致地錯誤轉錄特定術語(人名、公司名、技術詞彙),使用搜尋和取代一次修正所有實例,而非逐個修復。
考慮翻譯前的二次處理
如果原始轉錄有顯著錯誤且您還需要翻譯版本,先修正來源逐字稿至關重要。翻譯模型會傳播甚至有時放大來源文字中的錯誤。翻譯前先清理逐字稿。
當嘈雜音訊無法挽救時
有些情況下,無論多少噪音消除或 AI 調整都無法產生可用的逐字稿。早期識別這些情況可以節省時間和挫折感。
音訊可能無法挽救的跡象:
- 您戴著耳機仔細聆聽也無法理解語音
- 多位說話者長時間同時說話,沒有明確的主導聲音
- SNR 低於 5 dB,意味著噪音幾乎與語音一樣大或更大
- 嚴重的削波(錄音音量過高導致的失真)已永久損壞波形
- 嚴重的殘響使語音聽起來像在隧道或樓梯間錄製的
當 AI 轉錄失敗時的選項
- 人工轉錄,由專業人員使用上下文線索、讀唇(如果有影片)和主題專業知識來解碼困難的音訊。這更慢且更昂貴,但能處理 AI 無法處理的邊緣案例。如需更深入的比較,請參閱我們的 AI vs 人工轉錄指南。
- 如果可能重新錄製。 如果內容允許,安排使用更好的設備和環境的新錄音作業通常比嘗試挽救嚴重劣化的錄音更快。
- 部分轉錄。 轉錄音訊品質可接受的部分,並標注空白。有明確標記 [無法辨識] 的逐字稿比充滿錯誤猜測的逐字稿更有用。
常見問題
影響轉錄準確度的最大因素是什麼?
信噪比。語音相對於背景噪音越大,任何轉錄工具,無論是 AI 還是人工,辨識字詞就越準確。在安靜房間中使用近距離麥克風能產生最佳結果。請參考上方關於錄音設定、麥克風選擇與降低背景噪音的段落,這些是最快提高信噪比的方法。
AI 轉錄工具能處理背景音樂嗎?
在一定程度上。如果音樂安靜且語音清晰,大多數現代 ASR 模型可以透過音樂進行轉錄。大聲的音樂,特別是有歌聲的,會造成顯著的準確度問題,因為模型無法可靠地區分目標語音和歌唱。低音量的器樂背景音樂比任何音量的有歌聲音樂的干擾性都小。
上傳音訊進行轉錄前應該使用噪音消除嗎?
不要自動套用,請先測試。直覺上音訊越乾淨越好轉錄,但 Whisper 這類現代 AI 模型本來就用含噪資料訓練過;2025-2026 年研究發現,降噪與語音增強即使讓人耳聽起來更好,也常因處理偽影而提高字詞錯誤率。可靠做法是取一小段樣本,分別轉錄原始音訊與降噪後音訊,保留更準的版本。如果要降噪,請保持溫和:激進設定會引入金屬感偽影,通常弊大於利。
指定語言能改善嘈雜音訊的準確度嗎?
可以。當您手動設定語言時,ASR 模型從一開始就使用正確的詞彙和語言模型。對於嘈雜音訊,自動偵測步驟更可能誤判語言,然後對整個轉錄應用錯誤的模型。當您知道語言時,始終明確指定。
音訊品質對字詞錯誤率的影響有多大?
影響很大,但實際數字會依模型、語言與噪音類型而變,因此請把這些視為粗略示例,而不是量測保證。乾淨的錄音室音訊用現代 ASR 通常低於 5% WER;中度辦公室噪音或輕微交通聲通常落在低兩位數;擁擠餐廳或建築工地可能超過 30%。這種關係不是線性的;當 SNR 降至約 15 dB 以下時,準確度會快速下降。若想了解乾淨音訊基準本身在各語言間差多少,請看各語言轉錄準確度。
用 AI 還是人工轉錄員轉錄嘈雜音訊更好?
對於中度嘈雜的音訊,AI 工具通常足夠且快得多。對於嚴重劣化的音訊,即使仔細聆聽也很困難時,有技能的人工轉錄員通常會優於 AI,因為他們可以使用上下文推理、主題知識和影片中的視覺線索來填補空白。AI 和人工轉錄的比較在很大程度上取決於特定的噪音條件和您的準確度要求。
轉錄最適合用哪種音訊格式?
WAV 和 FLAC 最好,因為它們是無損格式,能保留完整音訊細節。實務上,192 kbps 或更高位元率的 MP3 也能有不錯效果。多數 AI 轉錄工具都接受常見格式,因此重點是用足夠高的位元率錄音,而不是糾結於容器格式。
為了轉錄值得買昂貴麥克風嗎?
通常不需要。一支 50-100 美元的 USB 麥克風,只要放在安靜房間並正確擺位,就能產生足以轉錄的音訊品質。昂貴麥克風增加的人聲厚度,對音樂和廣播比對語音轉文字準確度更重要。先投資房間處理與麥克風擺位,再考慮升級麥克風本身。
來源與延伸閱讀
- Chondhekar et al., "When De-noising Hurts: A Systematic Study of Speech Enhancement Effects on Modern Medical ASR Systems"(arXiv, 2025)-- 語音增強可能讓 Whisper 類模型的字詞錯誤率升高,即使音訊聽起來更乾淨
- Islam, Nahar & Hamid, "When Denoising Hinders: Revisiting Zero-Shot ASR with SAM-Audio and Whisper"(arXiv, 2026)
- Mu et al., "Performance evaluation of automatic speech recognition systems on integrated noise-network distorted speech", Frontiers in Signal Processing(2022)-- WER 與 SNR 的關係
- Hugging Face Audio Course -- preprocessing -- 現代 ASR 模型通常預期 16 kHz 音訊
- Engineering ToolBox -- inverse-square law -- 距離每增加一倍約衰減 6 dB 的經驗法則
- National Center for Voice and Speech -- fundamental frequency -- 理解 80-100 Hz 高通截止點的背景資料
