Como transcrever áudio com ruído e reduzir erros de ruído de fundo (2026)
Ruído de fundo é a maior causa de erros de transcrição. Um guia prático para gravar áudio mais limpo, ajustar o que importa, saber quando usar ou evitar redução de ruído antes de transcrever e lidar com áudio que não tem salvação.
O ruído de fundo é a maior causa de erros de transcrição. Mesmo os modelos mais avançados de reconhecimento automático de fala com IA têm dificuldade quando o sinal de áudio compete com trânsito, zumbido de ar-condicionado, conversas cruzadas ou eco de sala. Uma gravação que transcreve quase perfeitamente em uma sala silenciosa pode degradar rapidamente em um ambiente ruidoso, transformando uma transcrição útil em algo que requer extensa correção manual.
A boa notícia é que a maioria dos problemas com áudio ruidoso é prevenível ou corrigível. Este guia cobre toda a cadeia: como gravar áudio mais limpo desde o início, como processar gravações com ruído antes de transcrever, como configurar suas definições de transcrição para melhores resultados e como lidar com casos onde o áudio está genuinamente além de salvação.
Por que o ruído de fundo afeta a precisão da transcrição
Para entender por que o ruído causa erros de transcrição, é útil saber como o reconhecimento automático de fala (ASR) funciona em um nível básico.
Modelos de ASR convertem áudio em texto analisando as propriedades acústicas do som, dividindo o sinal em pequenas janelas de tempo e prevendo quais palavras ou fonemas são mais prováveis em cada ponto. O modelo foi treinado em milhares de horas de fala e aprendeu os padrões estatísticos que distinguem uma palavra da outra.
O ruído de fundo interrompe esse processo adicionando energia acústica que não corresponde à fala. Quando um zumbido de ventilador ou murmúrio de multidão ocupa a mesma faixa de frequência da voz do falante, o modelo não consegue separar os dois sinais de forma limpa. Ele faz sua melhor estimativa, mas essas estimativas se tornam menos confiáveis à medida que o nível de ruído aumenta.
O termo técnico para isso é relação sinal-ruído (SNR). A SNR mede quão mais alto o sinal de fala é comparado ao ruído de fundo, expresso em decibéis. Uma SNR de 30 dB ou superior (fala muito mais alta que o ruído) produz bons resultados de transcrição. Uma SNR abaixo de 10 dB (fala apenas um pouco mais alta que o ruído) leva a perda significativa de precisão. A perda é brusca, não gradual: as taxas de erro sobem acentuadamente à medida que a SNR cai, e é por isso que um pouco mais de distância do microfone, ou um único ar-condicionado ligado, pode derrubar a precisão.
A precisão de transcrição é tipicamente medida usando a taxa de erro de palavras (WER). Uma entrevista silenciosa e bem gravada pode ficar abaixo de 5% de WER; a mesma conversa em um café movimentado pode passar de 20-25%. Os números exatos dependem do modelo, idioma e tipo de ruído — veja precisão de transcrição por idioma para entender quanto a base com áudio limpo já varia — mas a diferença aqui é quase inteiramente atribuível ao ruído.
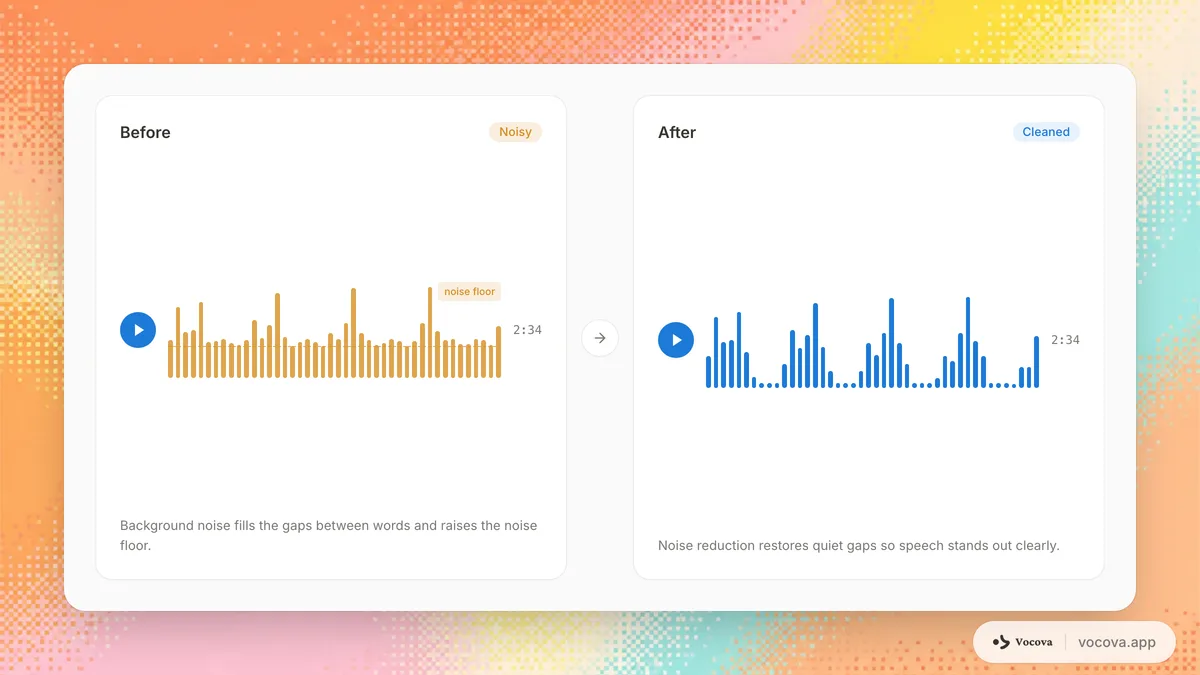
Tipos de ruído de áudio
Nem todo ruído afeta a transcrição igualmente. Entender o tipo de ruído na sua gravação ajuda a escolher a abordagem correta para lidar com ele.
Ruído ambiente
Sons de fundo constantes como ar-condicionado, trânsito, ventiladores ou zumbido de geladeira. Esse tipo de ruído é relativamente consistente em volume e frequência, o que o torna o mais fácil de remover com ferramentas de redução de ruído. No entanto, se for alto o suficiente, ele ainda degrada a precisão da transcrição.
Ruído eletrônico
Chiado, zumbido ou ronco introduzidos pelo próprio equipamento de gravação. Causas comuns incluem microfones de baixa qualidade, loops de terra em configurações com fio, interferência eletromagnética de eletrônicos próximos e interfaces de áudio com alto piso de ruído. O ruído eletrônico é geralmente consistente e tratável com redução de ruído.
Reverberação
Eco causado pelo som ricocheteando em superfícies duras de uma sala. A reverberação "borra" o sinal de fala ao longo do tempo, tornando mais difícil para modelos de ASR identificar limites de palavras. Um falante em um banheiro azulejado ou sala de conferências vazia produzirá significativamente mais reverberação do que um em um escritório com carpete e mobília. A reverberação é mais difícil de remover do que o ruído ambiente porque é uma versão transformada do sinal original.
Conversa cruzada e fala sobreposta
Múltiplas pessoas falando ao mesmo tempo. Este é um dos tipos de ruído mais difíceis para transcrição porque o sinal interferente é ele mesmo fala, e o modelo tem dificuldade em separar os dois falantes. A conversa cruzada ocorre comumente em reuniões, discussões em painel e entrevistas em grupo.
Ruído de vento
Estrondo de baixa frequência causado pelo movimento do ar através do microfone. O ruído de vento é comum em gravações ao ar livre e pode mascarar completamente a fala em rajadas fortes. Ele afeta principalmente a faixa baixa do espectro de frequência e frequentemente pode ser reduzido com um filtro passa-alta ou proteção contra vento.
Ruído impulsivo
Sons súbitos e de curta duração como cliques de teclado, folhear de papel, tosses ou impactos de construção. Estes são breves, mas podem corromper palavras ou frases individuais. Modelos de ASR podem interpretar um clique acentuado como um som de consoante, inserindo palavras fantasmas na transcrição.
Dicas pré-gravação para áudio mais limpo
A forma mais eficaz de obter transcrições precisas de ambientes ruidosos é capturar áudio melhor desde o início. Alguns minutos de preparação antes de começar a gravar podem economizar horas de limpeza depois.
Escolha o microfone certo
A seleção do microfone tem um grande impacto na rejeição de ruído.
- Microfones de lapela se prendem perto da boca do falante, mantendo o sinal de fala forte em relação ao ruído da sala. São ideais para entrevistas e apresentações.
- Microfones direcionais (cardioide ou shotgun) capturam som principalmente da frente e rejeitam som dos lados e de trás. Aponte-os para o falante e para longe das fontes de ruído.
- Microfones omnidirecionais capturam som igualmente de todas as direções. São úteis para discussões em grupo, mas captam mais ruído ambiente.
- Microfones de headset posicionam a cápsula perto da boca e são excelentes para ambientes ruidosos, razão pela qual call centers e pilotos os usam.
Posicione o microfone corretamente
A distância importa mais do que a maioria das pessoas percebe. Dobrar a distância entre o microfone e o falante reduz o sinal de fala em aproximadamente 6 dB, enquanto o nível de ruído de fundo permanece o mesmo. Mantenha o microfone o mais próximo possível do falante.
Para um microfone de lapela, prenda-o 15-20 cm abaixo do queixo. Para um microfone de mesa, posicione-o a 15-30 cm da boca do falante. Evite colocar microfones perto de fontes de ruído como ventiladores de computador, saídas de ar ou janelas voltadas para uma rua movimentada.
Trate a sala
Você não precisa de um estúdio profissional para reduzir significativamente ruído e reverberação.
- Feche janelas e portas para bloquear ruído externo
- Desligue ar-condicionado, ventiladores e eletrônicos desnecessários durante a gravação
- Adicione materiais macios (cortinas, tapetes, móveis estofados) para reduzir eco
- Evite salas com superfícies duras e paralelas (pisos de azulejo, paredes de vidro) que criam reverberação
- Se estiver gravando em um escritório, escolha uma sala menor e com carpete em vez de uma grande sala de conferências
Use proteção contra vento ao ar livre
Se você está gravando ao ar livre, use uma espuma protetora ou uma cobertura de pelo (frequentemente chamada de "dead cat") no seu microfone. O ruído de vento é extremamente disruptivo para transcrição e quase impossível de remover completamente na pós-produção.
Grave uma amostra de referência de ruído
Antes do falante começar a falar, grave 10 a 15 segundos apenas do ruído da sala. Essa "impressão de ruído" é útil para ferramentas de redução de ruído, que a usam para aprender as características do ruído e subtraí-lo da gravação.
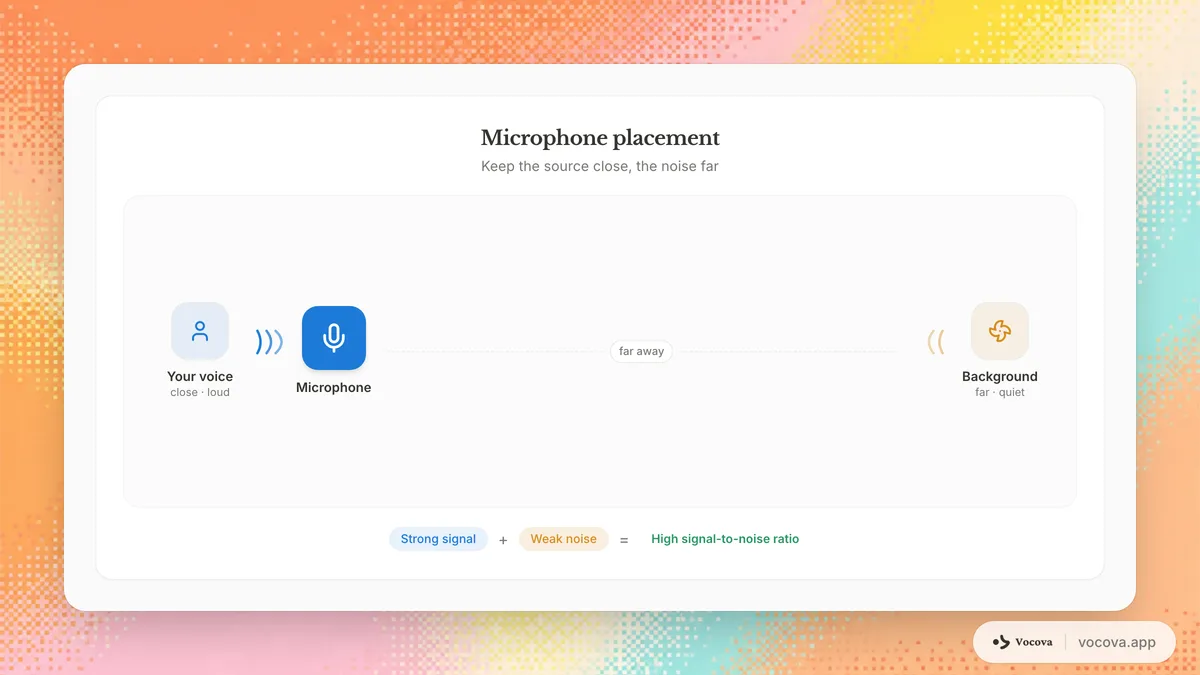
Configurações de gravação que afetam a precisão da transcrição
Além da escolha do microfone e do tratamento da sala, algumas configurações técnicas de gravação determinam quanto detalhe vocal sobrevive até a etapa de transcrição.
Taxa de amostragem. A maioria dos modelos modernos de ASR reamostra tudo internamente para 16 kHz — a taxa em que foram treinados — então uma taxa maior não melhora a precisão. Grave em 44.1 kHz ou 48 kHz por compatibilidade e arquivamento limpo, não por precisão de transcrição; 16 kHz mono já é suficiente para o modelo. Acima de 48 kHz não há benefício para reconhecimento de fala.
Profundidade de bits. Grave em 16-bit ou 24-bit. A diferença importa mais em trechos silenciosos: 24-bit captura fala suave com menos ruído de quantização, o que ajuda quando o falante está mais distante do microfone.
Mono vs estéreo. Para um único falante, mono é suficiente e produz arquivos menores. Para múltiplos falantes, gravar cada voz em um canal separado melhora mensuravelmente a diarização de falantes, porque o modelo pode separar vozes que chegam em canais distintos e limpos.
Formato de arquivo. WAV e FLAC são sem perdas e ideais para transcrição. MP3 a 192 kbps ou superior é aceitável; AAC/M4A (usado pela maioria dos celulares) é ligeiramente melhor que MP3 na mesma taxa de bits; OGG/Opus oferece boa qualidade em taxas de bits mais baixas. Se o armazenamento permitir, arquive em WAV ou FLAC. A maioria das ferramentas, incluindo o Vocova, aceita todos os formatos comuns — a prioridade é preservar o detalhe na própria gravação, não o contêiner.
Escolhendo o tipo e a conexão do microfone
A orientação sobre microfones acima foca na direcionalidade para rejeição de ruído. Duas escolhas adicionais definem a qualidade básica de qualquer gravação.
- Condensador vs dinâmico. Microfones condensadores são mais sensíveis e capturam mais detalhe vocal, o que ajuda em salas silenciosas e controladas — mas também captam mais ruído ambiente. Microfones dinâmicos rejeitam mais ruído de fundo por design, tornando-os a escolha mais segura em espaços não tratados ou ruidosos.
- USB vs XLR. Microfones USB (por exemplo, o Rode NT-USB Mini ou o Audio-Technica AT2020USB+) incluem uma interface de áudio integrada e são a escolha pragmática para a maioria das pessoas. Microfones XLR precisam de uma interface separada, mas oferecem pisos de ruído mais baixos e mais controle — algo que vale a pena principalmente se você já tem a interface.
Para transcrição, o ambiente importa mais do que o microfone específico. Um microfone USB de $50–100 posicionado corretamente em uma sala silenciosa produz áudio de qualidade para transcrição.
Dicas para cenários de gravação específicos
- Reuniões: Use um microfone de conferência dedicado (como o Jabra Speak ou o Anker PowerConf) no centro da mesa em vez do microfone do laptop. Para reuniões remotas, grave diretamente a saída de áudio do software de reunião e peça aos participantes que usem headsets para evitar eco.
- Entrevistas: Dê ao entrevistador e ao entrevistado microfones separados — idealmente microfones de lapela sem fio gravados em canais separados. Para entrevistas por chamada, grave através de software em vez de apontar um microfone para um viva-voz.
- Palestras: Um microfone de lapela no apresentador é a configuração mais confiável. Peça ao apresentador para repetir as perguntas da plateia antes de respondê-las, já que o áudio da plateia raramente é capturado de forma limpa.
- Podcasts: Dê a cada apresentador e convidado seu próprio microfone em uma faixa separada. Para gravação remota, faça cada participante gravar localmente (com ferramentas como Riverside.fm ou Zencastr) e combine as faixas depois para evitar artefatos de compressão de chamadas de vídeo.
Erros comuns de gravação que prejudicam a transcrição
- Celular no bolso ou na bolsa. O tecido abafa as altas frequências necessárias para distinguir consoantes, e o movimento adiciona ruído de farfalhar. Coloque o celular em uma superfície estável voltada para o falante.
- Ficar muito longe do microfone. A distância enfraquece o sinal de fala enquanto o ruído de fundo permanece constante, então a gravação acaba dominada pelo ruído. Fique perto.
- Ganho ajustado muito alto. O corte (clipping) é uma distorção permanente que não pode ser reparada. Ajuste os níveis para que a fala normal tenha picos em torno de -12 dB a -6 dB.
- Ganho ajustado muito baixo. Gravar muito baixo força você a amplificar depois, o que também amplifica o piso de ruído.
- Gravar por Bluetooth. O perfil Bluetooth de mãos-livres comprime fortemente o áudio da chamada. Use uma conexão com fio para gravar sempre que possível.
- Sem gravação de teste. Grave e reproduza 30 segundos antes da sessão real. Detectar eco de sala, zumbido ou ruído de manuseio antecipadamente é muito mais barato do que descobri-lo após uma gravação de duas horas.
Como limpar áudio ruidoso antes de transcrever
Se você já tem uma gravação ruidosa, ferramentas de processamento de áudio podem melhorar a qualidade do sinal antes de enviá-lo a um serviço de transcrição. Os resultados não igualarão uma gravação original limpa, mas podem ajudar.
Um alerta que surpreende: remover ruído nem sempre ajuda a transcrição por IA. Modelos da classe Whisper foram treinados com muito áudio imperfeito, e vários estudos de 2025-2026 (por exemplo, When De-noising Hurts, 2025, e When Denoising Hinders, 2026) descobriram que ferramentas de melhoria de fala e redução de ruído podem aumentar a taxa de erro de palavras — às vezes muito — mesmo quando o áudio soa mais limpo para uma pessoa, porque o processamento introduz artefatos que o modelo nunca viu no treinamento. A regra confiável é: processe uma amostra curta dos dois jeitos, transcreva as duas e fique com a que vencer. Surpreendentemente, muitas vezes é o áudio bruto. As ferramentas abaixo ajudam mais em ruídos constantes e bem caracterizados; ajudam menos, e podem piorar, em interferência parecida com fala e reverberação.
Audacity (gratuito, open source)
O Audacity é um editor de áudio gratuito com uma ferramenta de redução de ruído integrada.
- Selecione uma parte do áudio que contenha apenas ruído (sem fala)
- Vá em Efeito > Redução de Ruído > Obter Perfil de Ruído
- Selecione toda a trilha de áudio
- Aplique a Redução de Ruído com configurações em torno de 12 dB de redução, 6 de sensibilidade e 3 de suavização de frequência
- Pré-visualize o resultado e ajuste se a fala soar distorcida
O Audacity também tem um filtro passa-alta (Efeito > Curva de Filtro) que pode remover estrondo de baixa frequência de vento ou sistemas de ar-condicionado. Corte frequências abaixo de 80-100 Hz para gravações de voz falada.
Adobe Podcast Enhance Speech (gratuito, baseado na web)
A Adobe oferece uma ferramenta online gratuita que usa IA para melhorar gravações de fala. Faça upload do seu arquivo de áudio e a ferramenta tenta isolar a voz, reduzir ruído e normalizar o volume. Funciona bem para níveis moderados de ruído e é simples o suficiente para usuários não técnicos. A limitação é um limite de tamanho de arquivo e o fato de que processa o arquivo inteiro sem controle granular.
iZotope RX
O iZotope RX é uma suíte profissional de reparo de áudio usada em broadcast e pós-produção de filmes. Ele oferece ferramentas avançadas para redução de ruído, de-reverb, de-click, de-hum e isolamento de diálogo. É a opção mais capaz, mas vem com uma curva de aprendizado significativa e custo. Para trabalho regular de transcrição com áudio desafiador, vale o investimento.
Dicas gerais para limpeza de áudio
- Aplique redução de ruído conservadoramente. Configurações agressivas removem ruído, mas introduzem artefatos que soam como ondulação metálica. Esses artefatos podem confundir modelos de ASR tanto quanto o ruído original.
- Use um filtro passa-alta para remover estrondo abaixo de 80 Hz. A fala humana não contém informação significativa abaixo dessa frequência.
- Normalize o nível de áudio para que os picos de fala fiquem em torno de -3 dB a -6 dB. Modelos de ASR funcionam melhor com níveis de volume consistentes.
- Não comprima a faixa dinâmica excessivamente. Alguma compressão ajuda com fala sussurrada ou gritada, mas compressão pesada eleva o piso de ruído.
Configurações de transcrição com IA para áudio ruidoso
Uma vez que você limpou seu áudio o máximo possível, as configurações corretas de transcrição podem melhorar ainda mais a precisão.
Especifique o idioma
A maioria dos sistemas de ASR funciona melhor quando você especifica o idioma falado em vez de depender da detecção automática. A detecção automática adiciona uma etapa extra de inferência que pode dar errado com áudio ruidoso, potencialmente selecionando o modelo de idioma errado para toda a transcrição. Se você sabe o idioma, defina-o explicitamente.
Escolha o nível de modelo certo
Muitos serviços de transcrição oferecem múltiplos níveis de modelo, e níveis de maior precisão geralmente lidam melhor com ruído porque usam modelos maiores com mais capacidade para separar fala de interferência. Se seu provedor tiver um, vale a pena testar em uma amostra difícil; você pode fazer isso com seu próprio clipe na ferramenta de áudio para texto.
Use diarização de falantes com cuidado
A diarização de falantes, o processo de identificar quem disse o quê, depende da detecção de diferenças acústicas entre falantes. O ruído de fundo pode mascarar essas diferenças, fazendo com que o modelo de diarização divida um falante em múltiplos identificadores ou funda diferentes falantes em um só. Se seu áudio é ruidoso e os resultados de diarização parecem não confiáveis, você pode obter melhores resultados transcrevendo sem diarização e adicionando identificadores de falantes manualmente.
Divida gravações longas em segmentos
Se apenas partes de uma gravação longa são ruidosas, considere dividir o arquivo em segmentos e transcrevê-los separadamente. Isso evita que uma seção ruidosa afete o desempenho do modelo nas partes mais limpas. Você também pode aplicar diferentes configurações de redução de ruído a diferentes segmentos com base em suas características de ruído.
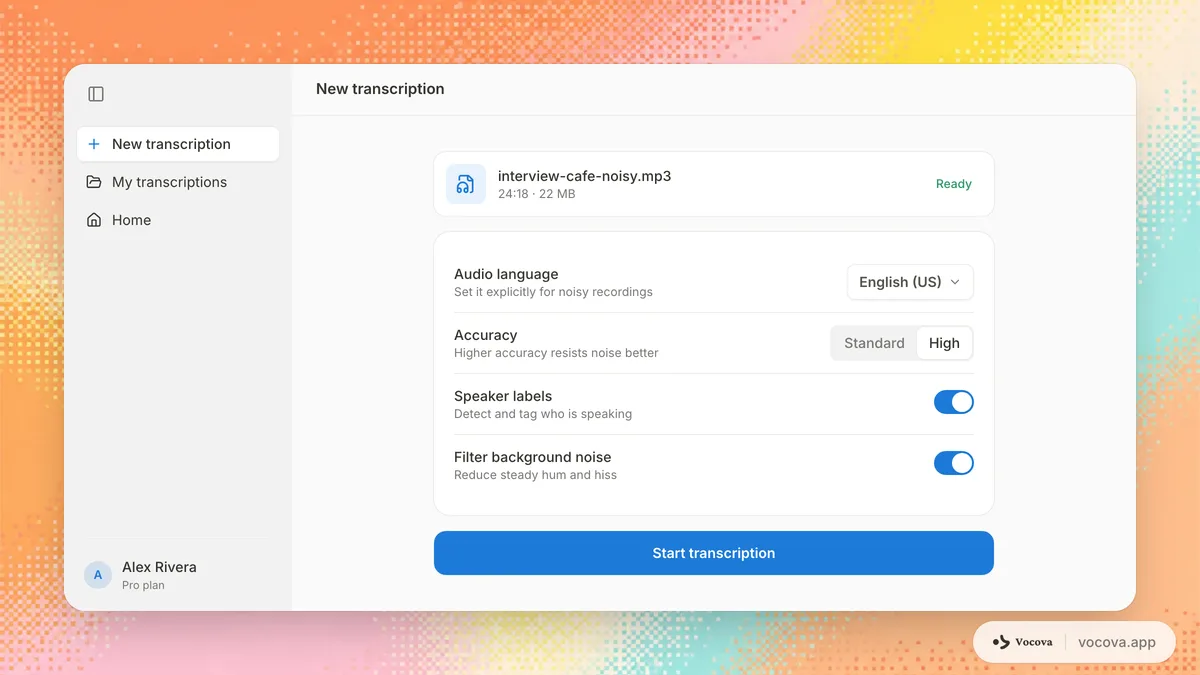
Dicas de limpeza pós-transcrição
Mesmo com preparação ideal de áudio e configurações de transcrição, gravações ruidosas produzirão transcrições que precisam de revisão manual. Aqui estão estratégias para limpeza eficiente.
Foque nas seções com mais erros primeiro
Ouça o áudio junto com a transcrição e identifique as seções onde a transcrição diverge mais da fala real. Estas são geralmente os momentos com os maiores níveis de ruído. Priorize a correção dessas seções em vez de ler a transcrição inteira linearmente.
Use marcações de tempo para navegar
Ferramentas de transcrição que fornecem marcações de tempo no nível da palavra ou do segmento permitem clicar diretamente na posição relevante do áudio. Isso torna muito mais rápido verificar e corrigir palavras individuais comparado a navegar pelo áudio manualmente. O Vocova fornece marcações de tempo para cada segmento, para que você possa pular diretamente para qualquer ponto da gravação.
Fique atento a erros comuns induzidos por ruído
Áudio ruidoso produz erros de transcrição característicos:
- Palavras fantasmas inseridas onde o modelo interpretou ruído como fala
- Palavras perdidas onde o ruído mascarou o sinal de fala completamente
- Homófonos e quase-acertos onde o modelo escolheu uma palavra de som similar porque o ruído obscureceu os sons distinguidores
- Nomes próprios distorcidos já que nomes e termos técnicos são menos previsíveis pelo contexto
Use localizar e substituir para erros sistemáticos
Se o modelo consistentemente transcreve incorretamente um termo específico ao longo da gravação (o nome de uma pessoa, o nome de uma empresa, uma palavra técnica), use localizar e substituir para corrigir todas as ocorrências de uma vez em vez de corrigi-las individualmente.
Considere uma segunda passagem com tradução
Se a transcrição original tem erros significativos e você também precisa de uma versão traduzida, corrigir a transcrição de origem primeiro é crítico. Modelos de tradução propagam e às vezes amplificam erros do texto de origem. Limpe a transcrição antes de traduzir.
Quando o áudio ruidoso está além de salvação
Há situações em que nenhuma quantidade de redução de ruído ou ajuste de IA produzirá uma transcrição utilizável. Reconhecer esses casos cedo economiza tempo e frustração.
Sinais de que o áudio pode ser irrecuperável:
- Você não consegue entender a fala ao ouvir cuidadosamente com fones de ouvido
- Múltiplos falantes estão falando simultaneamente por períodos prolongados sem uma voz dominante clara
- A SNR está abaixo de 5 dB, significando que o ruído é quase tão alto ou mais alto que a fala
- Corte severo (distorção de nível de gravação muito alto) corrompeu permanentemente a forma de onda
- Reverberação pesada faz a fala soar como se fosse gravada em um túnel ou escadaria
Opções quando a transcrição com IA falha
- Transcrição humana por um profissional que pode usar pistas contextuais, leitura labial (se vídeo estiver disponível) e expertise no assunto para decodificar áudio difícil. Isso é mais lento e mais caro, mas lida com casos extremos que a IA não consegue. Para uma comparação mais aprofundada, veja nosso guia sobre transcrição com IA vs transcrição humana.
- Regravar se possível. Se o conteúdo permitir, agendar uma nova sessão de gravação com equipamento e ambiente melhores é frequentemente mais rápido do que tentar salvar uma gravação severamente degradada.
- Transcrição parcial. Transcreva as seções com qualidade de áudio aceitável e anote as lacunas. Uma transcrição com seções claramente marcadas como [inaudível] é mais útil do que uma cheia de suposições incorretas.
Perguntas frequentes
Qual é o maior fator que afeta a precisão da transcrição?
Relação sinal-ruído. Quanto mais alta a fala é em relação ao ruído de fundo, mais precisamente qualquer ferramenta de transcrição, seja IA ou humana, pode identificar as palavras. Um microfone posicionado de perto em uma sala silenciosa produz os melhores resultados. Veja as seções acima sobre configuração de gravação, escolha de microfone e redução de ruído de fundo para as formas mais rápidas de aumentar essa relação.
Ferramentas de transcrição com IA conseguem lidar com música de fundo?
Moderadamente. Se a música é baixa e a fala é clara, a maioria dos modelos modernos de ASR consegue transcrever através dela. Música alta, especialmente com vocais, causa problemas significativos de precisão porque o modelo não consegue distinguir confiavelmente a fala alvo do canto. Música instrumental de fundo em volume baixo é menos disruptiva que música vocal em qualquer volume.
Devo usar redução de ruído antes de fazer upload de áudio para transcrição?
Não automaticamente — teste primeiro. É intuitivo pensar que áudio mais limpo transcreve melhor, mas modelos modernos como Whisper foram treinados com dados ruidosos, e estudos de 2025-2026 descobriram que redução de ruído e melhoria de fala frequentemente aumentavam a taxa de erro de palavras mesmo quando o áudio soava melhor para humanos, porque o processamento adiciona artefatos que o modelo não viu no treinamento. A abordagem confiável é transcrever uma amostra curta bruta e outra com redução de ruído, e ficar com a mais precisa. Se reduzir ruído, seja conservador: configurações agressivas introduzem artefatos metálicos que prejudicam mais do que ajudam.
Especificar o idioma melhora a precisão para áudio ruidoso?
Sim. Quando você define manualmente o idioma, o modelo de ASR usa o vocabulário e modelo de linguagem corretos desde o início. Com áudio ruidoso, a etapa de detecção automática é mais propensa a identificar incorretamente o idioma, o que então aplica o modelo errado para toda a transcrição. Sempre especifique o idioma quando souber qual é.
Quanto a qualidade do áudio afeta a taxa de erro de palavras?
Substancialmente, embora os números exatos variem por modelo, idioma e tipo de ruído; trate-os como ilustrações aproximadas, não como garantias medidas. Áudio limpo de estúdio frequentemente fica abaixo de 5% de WER com ASR moderno; ruído moderado de escritório ou trânsito leve tende a cair nos dois dígitos baixos; um restaurante lotado ou canteiro de obras pode passar de 30%. A relação não é linear — a precisão degrada rapidamente quando a SNR cai abaixo de cerca de 15 dB. Para ver quanto a base com áudio limpo varia entre idiomas, consulte precisão de transcrição por idioma.
É melhor transcrever áudio ruidoso com IA ou com um transcritor humano?
Para áudio moderadamente ruidoso, ferramentas de IA geralmente são suficientes e muito mais rápidas. Para áudio severamente degradado onde até ouvir com cuidado é difícil, um transcritor humano qualificado normalmente superará a IA porque pode usar raciocínio contextual, conhecimento do assunto e pistas visuais do vídeo para preencher lacunas. A comparação entre transcrição com IA e humana depende fortemente das condições específicas de ruído e dos seus requisitos de precisão.
Qual é o melhor formato de áudio para transcrição?
WAV e FLAC são os melhores porque são sem perdas e preservam todos os detalhes do áudio. Na prática, MP3 a 192 kbps ou mais também funciona bem. A maioria das ferramentas de transcrição com IA aceita os formatos comuns, então a prioridade é gravar em bitrate alto, não escolher um contêiner específico.
Vale a pena comprar um microfone caro para transcrição?
Normalmente, não. Um microfone USB de US$ 50-100 em uma sala silenciosa, com posicionamento correto, já produz áudio em qualidade adequada para transcrição. Microfones caros acrescentam riqueza vocal, algo mais importante para música e broadcast do que para precisão de speech-to-text. Invista primeiro em tratamento do ambiente e posicionamento do microfone.
Fontes e leituras adicionais
- Chondhekar et al., "When De-noising Hurts: A Systematic Study of Speech Enhancement Effects on Modern Medical ASR Systems" (arXiv, 2025) -- o aprimoramento de fala aumentou a taxa de erro de palavras em modelos da família do Whisper, mesmo quando o áudio parecia mais limpo
- Islam, Nahar & Hamid, "When Denoising Hinders: Revisiting Zero-Shot ASR with SAM-Audio and Whisper" (arXiv, 2026)
- Mu et al., "Performance evaluation of automatic speech recognition systems on integrated noise-network distorted speech", Frontiers in Signal Processing (2022) -- WER em relação ao SNR
- Hugging Face Audio Course -- preprocessing -- modelos ASR modernos esperam áudio a 16 kHz
- Engineering ToolBox -- inverse-square law -- a regra prática de cerca de 6 dB a menos a cada duplicação da distância
- National Center for Voice and Speech -- fundamental frequency -- contexto para o corte passa-alta entre 80 e 100 Hz
