音声を多言語で文字起こしする方法:2026年版ワークフローガイド
音声を多言語で文字起こしするための実践ワークフロー。言語自動検出、コードスイッチング、140以上のターゲット言語への翻訳、バイリンガルトランスクリプト、字幕、品質チェックまで。
最終確認日: 2026-06-23。Vocova 固有の上限(無料プランの分数/ファイルサイズ、Plus / Pro の機能、対応言語数)は同日時点の現行プロダクト構成に一致しています。本ガイドの数値とアプリ画面の表示が食い違う場合は、アプリ側が正です。
最も安全な多言語ワークフローは、まず原音声を文字起こしし、ソースのトランスクリプトを校正してから翻訳することです。タイムスタンプ、話者ラベル、ミスを後追い検証する力を犠牲にしてもよい場合を除き、音声から翻訳済みテキストへ一足飛びに進めてはいけません。
ほとんどのチームにとって、現実的なプロセスはこうなります。
- 音声をアップロード、または公開メディアの URL を貼り付ける。
- 話されている言語を自動検出させるか、手動で指定する。
- ソース言語でタイムスタンプ付きトランスクリプトを生成する。
- 名前、数値、専門用語を校正する。
- ターゲット言語に翻訳する。
- テキスト、バイリンガル文書、または翻訳済み字幕をエクスポートする。
Vocova は100以上の話し言葉での文字起こしと、Plus / Pro での140以上のターゲット言語への翻訳に対応しています。ファイルからの文字起こしは 音声からテキスト、動画は 動画からテキスト、翻訳ワークフローは 音声翻訳、字幕を含むなら 動画翻訳 から始めてください。
多言語文字起こしのワークフロー
| ステップ | 判断 | ベストプラクティス |
|---|---|---|
| インポート | ファイルアップロードか公開 URL か | プライベートファイルはアップロード。YouTube、Bilibili、SoundCloud、Dailymotion、ポッドキャスト、クラウドドライブの公開素材はリンク貼り付け |
| 言語設定 | 自動検出か手動か | 不明な音声には自動検出。言語が分かっている場合や冒頭がノイジーな場合は手動で指定 |
| 文字起こし | ソース言語のトランスクリプト | タイムスタンプと話者ラベルを保持し、後から検証可能にしておく |
| 校正 | 名前、用語、数値、話者 | 翻訳前に高インパクトの誤りを修正 |
| 翻訳 | 1言語または複数言語 | ソースを校正してから翻訳する(順序を逆にしない) |
| エクスポート | TXT、PDF、DOCX、SRT、VTT、CSV、バイリンガル出力 | 最終用途に合わせて出力形式を選ぶ |
言語自動検出で十分なケース
録音内の最初の明瞭な発話がメイン言語を表しているとき、言語自動検出はうまく機能します。次のような用途のデフォルトとして適しています。
- 話者の言語が事前に分からないインタビュー
- ユーザー投稿の音声ファイル
- 複数の国にまたがるポッドキャストエピソード
- 地域横断で集められた研究録音
- ファイル名がバラバラな動画ライブラリ
冒頭1分が音楽、無音、タイトルカード、効果音で占められていたり、別言語で短く挨拶している場合は精度が落ちます。そういう録音では、開始前に言語を手動指定してください。
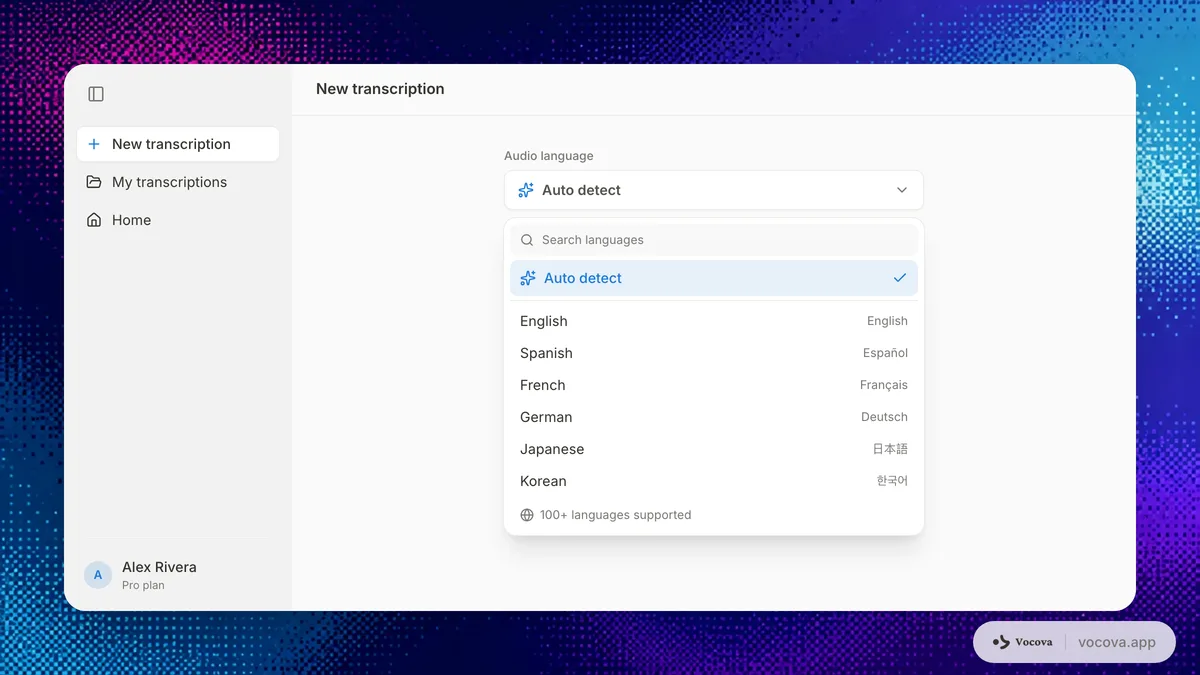
言語を手動で指定すべきケース
言語または方言系統が分かっている場合、手動指定は精度を高めます。特に以下の場面で有効です。
- イントロが長い日本語、韓国語、中国語、広東語、タイ語、アラビア語コンテンツ
- 最初の話者が、その後の主たる言語と異なる言語を使っている音声
- 英語タイトルスライドで始まり、別言語で続く教育動画
- 1つの言語が議論を支配する多言語会議
- 強い訛りやドメイン特有の用語を含む録音
手動指定はモデルを制限するためではありません。文字起こしシステムにより強力な出発点を与えることで、序盤の誤分類エラーを減らすためのものです。
複数言語が混在する録音の扱い方
多言語録音には、3つの代表的なパターンがあります。
1録音につき1言語
最も簡単なケースです。フランス語のインタビュー、日本語の講義、スペイン語のポッドキャストエピソードはソース言語で文字起こしし、校正したうえで英語など別の言語に翻訳できます。
推奨ワークフロー:
- 言語が分かっていればソース言語を選ぶ。
- 文字起こしする。
- 固有名詞や用語を校正する。
- 翻訳する。
- 校正が重要ならバイリンガル文書をエクスポートする。
同一録音内でのコードスイッチング
コードスイッチング(言語の切り替え)とは、同じ会話、ときに同じ文の中で話者が言語を行き来することです。例: ヒンディー語と英語、スペイン語と英語、中国語と英語、韓国語と英語、アラビア語とフランス語の混在会話。
推奨ワークフロー:
- 主たる言語を選ぶ。
- 録音全体を文字起こしする。
- 混合言語のセグメントを手動で校正する。
- ソーストランスクリプトが読める状態になってから翻訳する。
- 翻訳と並べて原文トランスクリプトを保持する。
完全自動の翻訳がすべての混合言語フレーズを解決すると期待してはいけません。トランスクリプトは検証層です。
話者ごとに異なる言語
国際会議、顧客インタビュー、学術フィールドワーク、多言語ウェビナーで起こります。ある話者がポルトガル語、別の話者が英語、また別の話者が日本語を使うかもしれません。
推奨ワークフロー:
- 話者識別が利用できるなら有効化する。
- 主言語で文字起こしするか、自動検出を使う。
- 話者名と言語固有の用語を訂正する。
- 校閲言語に翻訳する。
- レビュアーが原文と翻訳を比較できるよう、バイリンガル出力をエクスポートする。
ここでは話者ラベルが重要です。誰が何を言ったかを明確にしておくと、翻訳が会議記録、研究ノート、顧客の発言記録になったときに不可欠な情報が残ります。
トランスクリプト校正前に翻訳してはいけない理由
翻訳の品質はソースの品質に依存します。原文トランスクリプトに製品名、人名、法務用語、薬剤名、企業名、ゲームタイトル、地名の誤りがあると、その誤りは翻訳でも温存されることがほとんどです。
翻訳前に校正すべき項目:
- 人名、企業名、製品名、アーティスト名、番組名、ゲーム名、地名
- 数値、日付、時刻、価格、計量単位
- 略語と専門用語
- 話者ラベル
- 音声グリッチで反復した語句
- 話者の重なりがあるセグメント
すべての文を完璧にしてから翻訳する必要はありません。誤訳されると高くつく、または恥ずかしい用語だけ直しましょう。
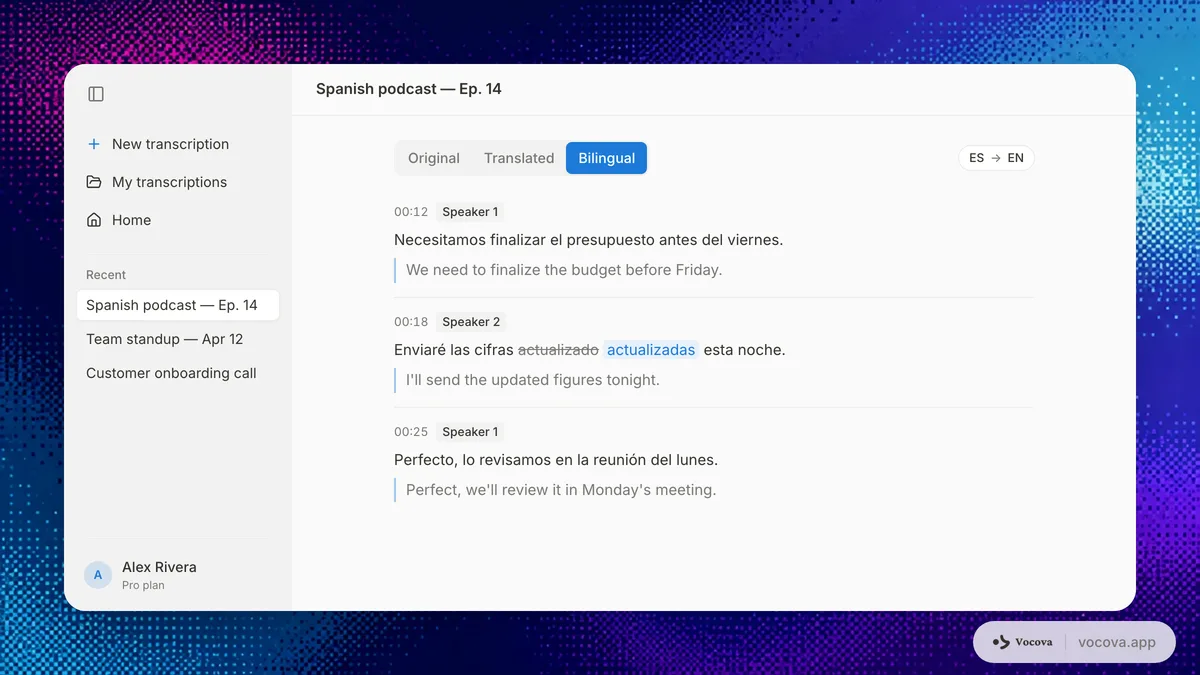
多言語業務向けのエクスポート選択
| 出力 | 用途 | 備考 |
|---|---|---|
| TXT | 素早いコピー、メモ、検索 | シンプルなテキスト再利用に最適 |
| 完成稿の共有 | クライアント、チーム、アーカイブ向け | |
| DOCX | 編集とコメント | 人手で改訂する前提のとき最適 |
| SRT | 動画字幕 | 動画プラットフォームと広く互換 |
| VTT | Web 動画キャプション | HTML5・Web プレーヤーに適合 |
| CSV | 研究、分析、QA | セグメント単位のレビューに有用 |
| バイリンガルエクスポート | 翻訳レビュー | 原文と訳文を並列保持 |
字幕ワークフローについては SRT generator、VTT generator、SRT vs VTT、字幕ファイル形式の完全ガイド を参照してください。
実例: 45分のスペイン語ポッドキャスト → 英語バイリンガル SRT
ワークフローを具体化するため、エピソード1本を端から端まで処理する典型例を示します。所要時間はクリーンなスタジオ収録で話者2名のケースです。荒いフィールド音声ではもっと時間がかかります。
| ステージ | 操作 | 所要時間 | 出力 |
|---|---|---|---|
| 1 | Plus で 45分の MP3(約 65 MB)をアップロード、または公開エピソードの URL を貼り付け | 1分 | ファイルがキューに入る |
| 2 | 自動検出でスペイン語と判定。文字起こしはサーバー側で実行 | 4〜6分 | タイムスタンプ付きソーストランスクリプト |
| 3 | 固有名詞をざっと洗う: ホスト、ゲスト、ブランド名、エピソード固有の語彙。8〜15項目を修正 | 8〜12分 | 校正済みソーストランスクリプト |
| 4 | トランスクリプトを英語に翻訳(Plus / Pro) | 2〜4分 | 英語トランスクリプト |
| 5 | 英語出力をスポットチェック: 名前、数値、日付、専門用語に集中 | 8〜12分 | レビュー済みの英語 |
| 6 | 字幕用にバイリンガル SRT を、コンテンツ再利用用にバイリンガル DOCX をエクスポート | 1分 | 最終成果物 |
合計: 45分のエピソードに対して人手で 約25〜35分(モデル時間はほぼバックグラウンド)。重い工程はステージ3と5、すなわちソーストランスクリプトでの固有名詞校正と、翻訳出力での確認パスです。これらを飛ばすと、流暢に聞こえるのにゲストを取り違えたり製品名を誤訳した英語が、安定して量産されます。
ソース言語によっていくつかの数値が変わります。
- 高リソース言語(英語、スペイン語、フランス語、ドイツ語、イタリア語、ポルトガル語、日本語、中国語)は上記の所要時間に近い。
- 中リソース言語(韓国語、オランダ語、ロシア語、アラビア語、ポーランド語、ベトナム語、タイ語)は、ステージ3と5の校正に通常 1.5〜2倍の時間がかかる。
- 低リソース言語(ティアの一覧は 言語別の文字起こし精度 を参照)では、翻訳工程に進む前にもう一度文字起こしを通した方が成果が安定します。
同じフローのバリエーション:
- 多言語インタビュー — ステップ6をタイムスタンプ付きのバイリンガル DOCX/PDF に差し替え。詳しくは multilingual interview workflows。
- グローバルなポッドキャスト再利用 — 同じソーストランスクリプトを並列で複数のターゲット言語に翻訳し、校正済みソースを正典として保持する。詳しくは AI文字起こしでポッドキャストやウェビナーを10以上のコンテンツに再利用する方法。
- 顧客電話・営業リサーチ — タイムスタンプ、話者ラベル、ソーストランスクリプトを翻訳の隣に表示し続け、引用を後追い検証可能に保つ。
- 翻訳済み字幕 — 動画翻訳 から開始。公開前に1行の長さを確認する。
よくある言語ペアと出発点
ターゲットが英語なら、音声翻訳 が下記すべてのソース言語に対応します——インポート時にソース、エクスポート時に English を選択してください。下の表は、翻訳なしでソース言語のトランスクリプトだけが必要なときに使う言語別ツールの一覧です。
| ソース言語 | ソース言語のトランスクリプトのみ |
|---|---|
| 日本語 | 日本語文字起こし |
| 韓国語 | 韓国語文字起こし |
| 中国語(標準語) | 中国語文字起こし |
| スペイン語 | スペイン語文字起こし |
| フランス語 | フランス語文字起こし |
| ポルトガル語 | ポルトガル語文字起こし |
| ドイツ語 | ドイツ語文字起こし |
| イタリア語 | イタリア語文字起こし |
| アラビア語 | アラビア語文字起こし |
| ヒンディー語 | ヒンディー語文字起こし |
上の表にないソース/ターゲットの組み合わせも、同じ 音声翻訳 ツールが 100 以上のソース言語の文字起こしと 140 以上のターゲット言語への翻訳をカバーします——インポート時にソース、エクスポート時にターゲットを選択してください。
多言語トランスクリプトの品質チェック
軽量なレビューチェックリストを使ってください。
- 検出された言語が、実際のメイン言語と一致しているか?
- 話者ラベルは用途に十分な精度か?
- 名前と製品用語が一貫した表記になっているか?
- 数値と日付は正しいか?
- 混合言語のフレーズが正しく保持されているか?
- 翻訳が、単語ではなく意味を保っているか?
- 字幕が、長すぎる行なしに画面に収まるか?
- エクスポート形式が、後段ツールに合っているか?
より技術的な精度フレームワークについては 単語エラー率 と 言語別の文字起こし精度 を参照してください。
よくあるミス
多言語音声に英語専用ツールを使う
会議系ツールには英語の会議に強いが、多言語ファイル、地方訛り、翻訳ワークフローには弱いものがあります。プロジェクトごとにソース言語が変わる業務では、最初から多言語向けに設計されたツールを選んでください。
翻訳を最初のステップとして扱う
精度が重要なら、必ず先にソーストランスクリプトを作ってください。ソースが、タイムスタンプ・話者・後追い検証の足がかりを与えてくれます。
字幕形式を意識しない
最終成果物がキャプションなら、SRT と VTT の選択を早い段階で決めてください。テキストエクスポートだけでは動画ローカライズには不十分です。
ファイル上限とエクスポート上限を確認しない
無料プランは検証には便利ですが、多言語ワークフローには大きなファイル、複数のエクスポート、翻訳、字幕が必要になることが多々あります。長尺の録音を流す前に、必要な機能が含まれているかを確認してください。
多言語文字起こしが重要な理由
言語の壁は高くつきます。グローバル企業では、意思疎通の抜け漏れが商談機会の損失、手戻り、確認作業の増加として実際の売上に影響します。国際案件を逃す理由として、多言語対応力の不足を挙げる企業も少なくありません。Ethnologue によれば、現在使われている生きた言語は 7,100 を超え、リモートワークとハイブリッドワークが一般化したことで、インタビュー、会議、顧客通話が複数言語にまたがる可能性は5年前よりずっと高くなっています。AI による文字起こしと翻訳は、以前なら人間の通訳や翻訳者に数日かかっていた作業を数分に圧縮します。だからこそ、上記のワークフローはグローバルチームの標準的な作業手順になりつつあります。
多言語文字起こしを支える技術
録音の期待値を設定するうえで、近年の多言語精度を押し上げた技術的変化を理解しておく価値があります。
- 統合型の多言語モデル。 現在の強力なエンジンは、言語ごとに別モデルを使うのではなく、1つのモデルで100以上の言語を処理します。Whisper は68万時間の多言語音声で学習されました。ElevenLabs Scribe は99言語対応で登場し、主要言語で高い精度を示しています。Meta の研究は、これまで AI 文字起こしの支援がほとんどなかった数百の言語を含め、1,000以上の言語へカバレッジを広げています。
- 転移学習。 言語は音声的・構造的な特徴を共有します。そのため、英語や中国語普通話のような高リソース言語で大量に学習したモデルは、関連する言語、たとえばスペイン語からポルトガル語にもその知識を転用でき、各言語に同量の学習データがなくても精度を底上げできます。
- 自己教師あり事前学習。 wav2vec のような手法では、まず大量のラベルなし音声から学習し、その後より小さなラベル付きデータで微調整します。これにより、低リソース言語でも実用的な文字起こしが可能になります。
- 自動言語検出と code-switching。 これらのモデルは複数言語を同時に学習しているため、手動設定なしで話されている言語を識別し、話者が文の途中で言語を切り替えるケースにも対応できます。どちらも現実の多言語音声には欠かせません。
まだ残る課題
多言語文字起こしは完全に解決済みの問題ではありません。次の点を前提に期待値を調整してください。
- 低リソース言語。 研究モデルでは1,000以上の言語をカバーするようになっていますが、多くの言語では、十分な学習データがある高リソース言語より精度が大きく下がります。
- 方言差。 標準アラビア語で学習したモデルはモロッコのダリジャに苦戦することがあり、中国語普通話モデルが広東語をうまく扱えないこともあります。言語単位の平均精度は、この長い裾野を隠してしまいます。
- アクセントのある発話。 非ネイティブ話者ではエラー率が上がりやすくなります。多くの参加者が第二・第三言語で働くグローバルチームにとって、これは公平性にも関わる問題です。
- 翻訳における文化的・文脈的ニュアンス。 文字起こしが正確でも、翻訳で慣用表現や専門分野の意味が失われることがあります。法務、医療、公開研究など高リスクの内容では、人間による確認を工程に残してください。だからこそ上記のワークフローでは、翻訳前にソースの文字起こしを確認します。
これらの制約の背景にある言語別ベンチマークは、言語別の文字起こし精度 を参照してください。
よくある質問
AI は多言語の音声を文字起こしできますか?
できます。最新の AI 文字起こしは多くの言語に対応しており、Vocova は100以上の話し言葉の文字起こしと言語自動検出に対応しています。精度は依然として言語、音声品質、訛り、コードスイッチングの有無で変動します。
音声を直接英語に翻訳できますか?
可能ですが、より安全なワークフローはまず原音声を文字起こしし、トランスクリプトを翻訳することです。これによりタイムスタンプが残り、翻訳結果に違和感があるときに参照できるソーステキストが得られます。
バイリンガルトランスクリプトに最適な形式は?
人手で読んでレビューするなら PDF または DOCX。バイリンガル出力が字幕用途なら SRT または VTT。セグメント単位の分析なら CSV を使ってください。
1つの文に2言語が混在する音声はどう扱いますか?
主言語を選んで文字起こしし、混合言語のセグメントを手動で校正します。コードスイッチングは単一言語より難しいので、翻訳の隣に必ず原文トランスクリプトを残してください。
文字起こしの後で字幕を翻訳できますか?
できます。ソーストランスクリプトを生成し、翻訳してから SRT または VTT をエクスポートしてください。公開前に1行の長さとタイミングを確認します。
文字起こしの精度が高い言語は?
クリーンな音声では、英語、スペイン語、フランス語、ドイツ語、イタリア語、ポルトガル語、日本語、中国語などの高リソース言語が概ね高精度です。低リソース言語、強い訛り、話者の重なり、ノイジーな録音はより多くの校正を要します。ベンチマークの文脈は 言語別の文字起こし精度 を参照してください。
無料プランで実務の多言語ワークフローを賄えますか?
録音の長さ次第です。無料プランでは 30分の文字起こしから始められ、ファイルサイズ最大30 MB、保存できる文字起こしは3件まで です。短いクリップで対象言語の精度を検証し、有料プランに進む前にワークフローが合うかを確認するには十分です。45分のポッドキャスト1本や1時間のインタビューだけで無料分数を超えますし、多くの多言語ワークフローでは翻訳、バイリンガルエクスポート、より大きなファイル、字幕エクスポートといった有料機能が必要になります。検証段階では、まず無料プランで3〜5分の代表的サンプルを試し、精度と言語カバレッジが確認できたら Plus に移るのが妥当です。
文字起こしの AI 翻訳は人間の翻訳と比べてどうですか?
AI 翻訳ははるかに速く低コストで、通常は数日ではなく数秒で結果を返します。会議メモ、字幕、社内ドキュメントのような日常的な用途では、手作業で大きく直さなくても十分な品質になることが多いです。一方、法務文書、公開研究、規制対応資料など重要度の高い内容では、AI が生成した翻訳を人間が確認することをおすすめします。
文字起こしと翻訳に別々のツールが必要ですか?
必ずしも必要ありません。統合型のプラットフォームなら、同じワークフロー内で文字起こしと翻訳を処理できるため、タイムスタンプ、話者ラベル、書式を保ったまま翻訳できます。文字起こしを別ツールから書き出し、翻訳サービスにアップロードし、結果を手作業で組み直す手間を避けられます。
出典・参考リンク
外部:
Vocova 関連ガイド:
- おすすめ無料文字起こしツール — 各無料プランで実際に何を完了できるか。
- YouTube 動画を文字起こしする方法 — 5つの方法を比較。YouTube は実際のところ多言語音声の最も一般的なソース。
- Bilibili動画の文字起こし方法 — Bilibili プラットフォームでの中国語→英語ディープダイブ。
- リンクを貼ってオンライン動画やPodcastを文字起こしする方法 — YouTube、Bilibili、SoundCloud、Dailymotion、ポッドキャスト、クラウドドライブを横断した URL インポートのワークフロー。
- 言語別の文字起こし精度 — 言語ティアごとの期待値。
ツール:
