Comment transcrire un audio bruité et réduire les erreurs dues au bruit de fond (2026)
Le bruit de fond est la principale cause d'erreurs de transcription. Guide pratique pour enregistrer un audio plus propre, choisir les bons réglages, savoir quand réduire le bruit avant transcription — ou non — et gérer l'audio irrécupérable.
Le bruit de fond est la cause principale des erreurs de transcription. Même les modèles de reconnaissance vocale IA les plus avancés peinent lorsque le signal audio est en concurrence avec la circulation, le bourdonnement de la climatisation, les conversations croisées ou l'écho de la pièce. Un enregistrement qui se transcrit presque parfaitement dans une pièce calme peut se dégrader fortement dans un environnement bruyant, transformant une transcription utile en quelque chose nécessitant une correction manuelle intensive.
La bonne nouvelle est que la plupart des problèmes liés au bruit audio sont soit évitables, soit corrigibles. Ce guide couvre l'ensemble de la chaîne : comment enregistrer un audio plus propre dès le départ, comment traiter les enregistrements bruités avant de les transcrire, comment configurer vos paramètres de transcription pour de meilleurs résultats, et comment gérer les cas où l'audio est véritablement irrécupérable.
Pourquoi le bruit de fond affecte la précision de transcription
Pour comprendre pourquoi le bruit cause des erreurs de transcription, il est utile de savoir comment fonctionne la reconnaissance automatique de la parole (ASR) à un niveau basique.
Les modèles ASR convertissent l'audio en texte en analysant les propriétés acoustiques du son, en découpant le signal en petites fenêtres temporelles, et en prédisant quels mots ou phonèmes sont les plus probables à chaque point. Le modèle a été entraîné sur des milliers d'heures de parole et a appris les schémas statistiques qui distinguent un mot d'un autre.
Le bruit de fond perturbe ce processus en ajoutant de l'énergie acoustique qui ne correspond pas à de la parole. Lorsque le bourdonnement d'un ventilateur ou le murmure d'une foule occupe la même plage de fréquences que la voix du locuteur, le modèle ne peut pas séparer proprement les deux signaux. Il fait sa meilleure estimation, mais ces estimations deviennent moins fiables à mesure que le niveau de bruit augmente.
Le terme technique pour cela est le rapport signal sur bruit (SNR). Le SNR mesure à quel point le signal vocal est plus fort que le bruit de fond, exprimé en décibels. Un SNR de 30 dB ou plus (la parole est beaucoup plus forte que le bruit) produit de bons résultats de transcription. Un SNR inférieur à 10 dB (la parole est à peine plus forte que le bruit) entraîne une perte de précision significative. La perte est brutale, pas progressive : le taux d'erreur grimpe fortement à mesure que le SNR baisse, c'est pourquoi un peu plus de distance au micro, ou une seule climatisation allumée, peut faire chuter la précision.
La précision de transcription est généralement mesurée à l'aide du taux d'erreur de mots (WER). Une interview calme et bien enregistrée peut rester sous 5 % WER; la même conversation dans un café animé peut dépasser 20-25 %. Les chiffres exacts dépendent du modèle, de la langue et du type de bruit — voir la précision de transcription par langue pour comprendre à quel point la base en audio propre varie déjà — mais l'écart ici est presque entièrement attribuable au bruit.
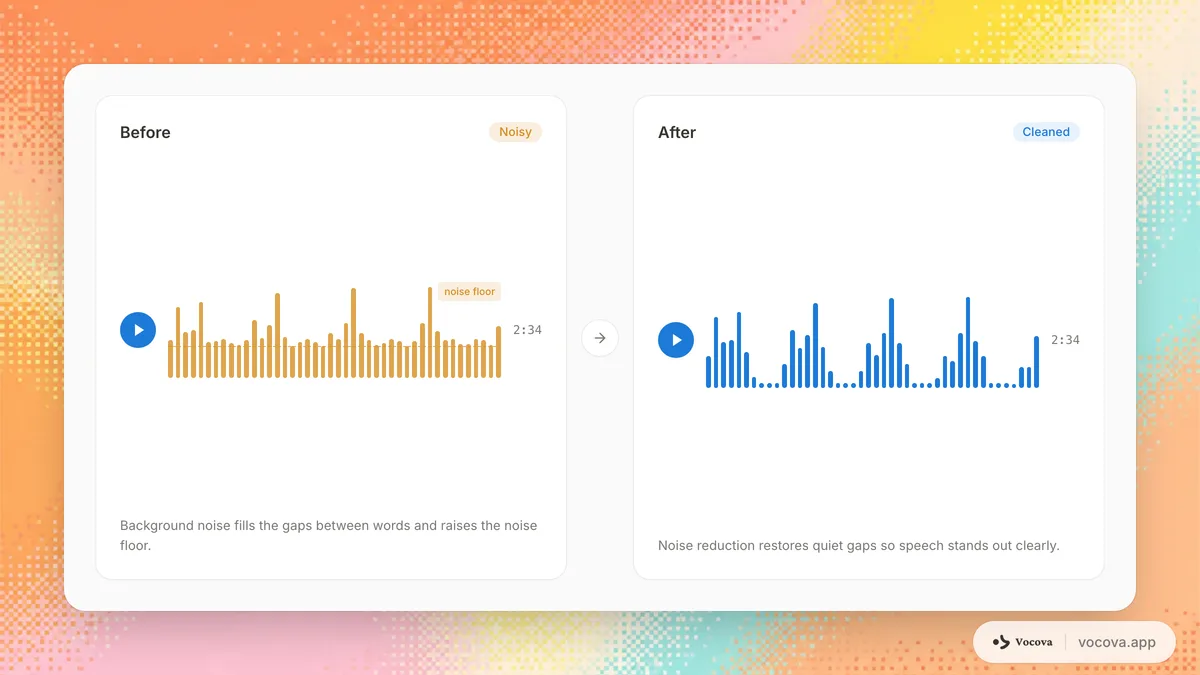
Types de bruit audio
Tous les bruits n'affectent pas la transcription de la même manière. Comprendre le type de bruit dans votre enregistrement vous aide à choisir la bonne approche pour y faire face.
Bruit ambiant
Sons de fond constants tels que la climatisation, la circulation, les ventilateurs ou le bourdonnement d'un réfrigérateur. Ce type de bruit est relativement constant en volume et en fréquence, ce qui le rend le plus facile à supprimer avec des outils de réduction du bruit. Cependant, s'il est suffisamment fort, il dégrade tout de même la précision de transcription.
Bruit électronique
Sifflement, bourdonnement ou ronronnement introduits par l'équipement d'enregistrement lui-même. Les causes courantes incluent les microphones de mauvaise qualité, les boucles de masse dans les installations filaires, les interférences électromagnétiques des appareils électroniques proches et les interfaces audio avec des planchers de bruit élevés. Le bruit électronique est généralement constant et traitable par la réduction du bruit.
Réverbération
Écho causé par le son rebondissant sur les surfaces dures d'une pièce. La réverbération étale le signal vocal dans le temps, rendant plus difficile pour les modèles ASR d'identifier les limites des mots. Un locuteur dans une salle de bain carrelée ou une salle de conférence vide produira significativement plus de réverbération que dans un bureau moquetté et meublé. La réverbération est plus difficile à supprimer que le bruit ambiant car c'est une version transformée du signal original.
Parole croisée et chevauchement
Plusieurs personnes parlant en même temps. C'est l'un des types de bruit les plus difficiles pour la transcription car le signal interférent est lui-même de la parole, et le modèle a du mal à séparer les deux locuteurs. La parole croisée se produit fréquemment dans les réunions, les tables rondes et les interviews de groupe.
Bruit de vent
Grondement basse fréquence causé par le mouvement de l'air sur le microphone. Le bruit de vent est courant dans les enregistrements en extérieur et peut complètement masquer la parole lors de rafales fortes. Il affecte principalement le bas du spectre de fréquences et peut souvent être réduit avec un filtre passe-haut ou une bonnette anti-vent.
Bruit impulsionnel
Sons soudains et de courte durée tels que les clics de clavier, le froissement de papier, la toux ou les impacts de chantier. Ceux-ci sont brefs mais peuvent corrompre des mots ou des phrases individuels. Les modèles ASR peuvent interpréter un clic sec comme un son consonantique, insérant des mots fantômes dans la transcription.
Conseils de pré-enregistrement pour un audio plus propre
Le moyen le plus efficace d'obtenir des transcriptions précises à partir d'environnements bruités est de capturer un meilleur audio dès le départ. Quelques minutes de préparation avant d'appuyer sur le bouton d'enregistrement peuvent vous faire gagner des heures de nettoyage par la suite.
Choisir le bon microphone
Le choix du microphone a un impact majeur sur le rejet du bruit.
- Les microphones-cravates (lavaliers) se clipsent près de la bouche du locuteur, maintenant le signal vocal fort par rapport au bruit ambiant. Ils sont idéaux pour les interviews et les présentations.
- Les microphones directionnels (cardioïdes ou canon) captent le son principalement depuis l'avant et rejettent le son venant des côtés et de l'arrière. Dirigez-les vers le locuteur et loin des sources de bruit.
- Les microphones omnidirectionnels captent le son de toutes les directions de manière égale. Ils sont utiles pour les discussions de groupe mais captent plus de bruit ambiant.
- Les microphones-casques positionnent la capsule près de la bouche et sont excellents pour les environnements bruyants, c'est pourquoi les centres d'appels et les pilotes les utilisent.
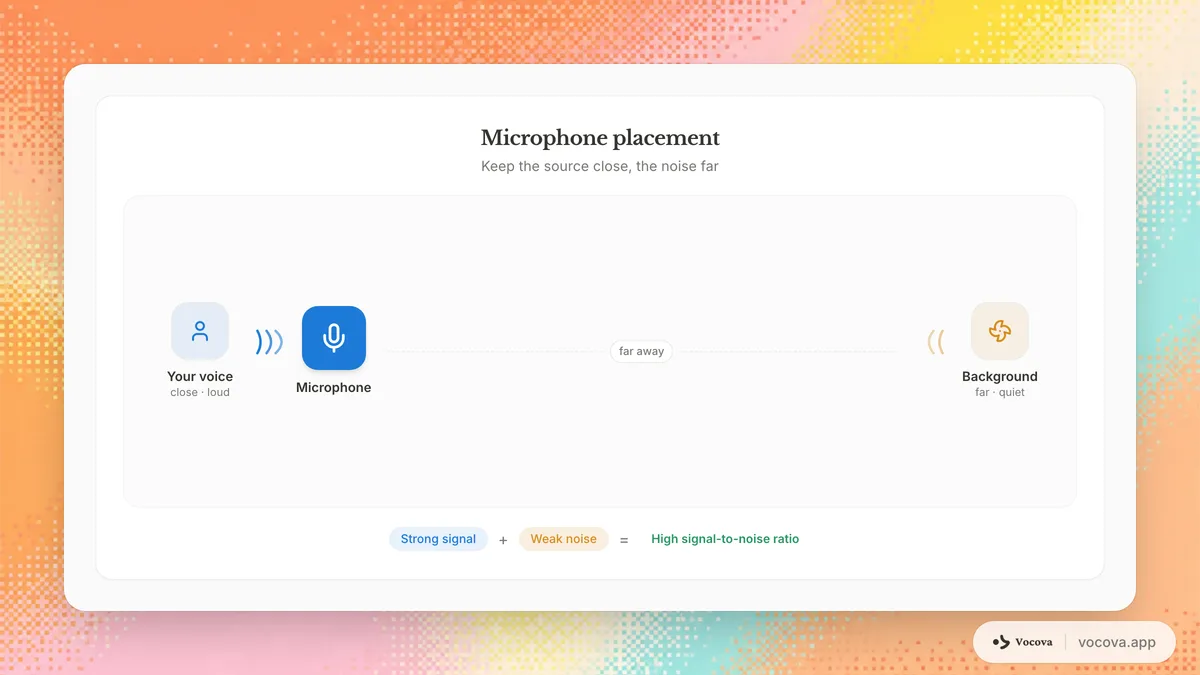
Positionner correctement le microphone
La distance compte plus que la plupart des gens ne le réalisent. Doubler la distance entre le microphone et le locuteur réduit le signal vocal d'environ 6 dB tandis que le niveau de bruit ambiant reste le même. Gardez le microphone aussi proche du locuteur que possible.
Pour un micro-cravate, clipsez-le 15-20 cm sous le menton. Pour un microphone de bureau, positionnez-le à 15-30 cm de la bouche du locuteur. Évitez de placer les microphones près de sources de bruit comme les ventilateurs d'ordinateur, les bouches de ventilation ou les fenêtres donnant sur une rue passante.
Traiter la pièce
Vous n'avez pas besoin d'un studio professionnel pour réduire significativement le bruit et la réverbération.
- Fermez les fenêtres et les portes pour bloquer le bruit extérieur
- Éteignez la climatisation, les ventilateurs et les appareils électroniques non nécessaires pendant l'enregistrement
- Ajoutez des matériaux souples (rideaux, tapis, meubles rembourrés) pour réduire l'écho
- Évitez les pièces avec des surfaces dures et parallèles (sols carrelés, murs vitrés) qui créent de la réverbération
- Si vous enregistrez dans un bureau, choisissez une pièce plus petite et moquettée plutôt qu'une grande salle de conférence
Utiliser une bonnette anti-vent en extérieur
Si vous enregistrez en extérieur, utilisez une bonnette en mousse ou une couverture anti-vent à fourrure (souvent appelée « dead cat ») sur votre microphone. Le bruit de vent est extrêmement perturbateur pour la transcription et presque impossible à supprimer complètement en post-traitement.
Enregistrer un échantillon de bruit de référence
Avant que le locuteur ne commence à parler, enregistrez 10 à 15 secondes du bruit ambiant seul. Cette « empreinte de bruit » est utile pour les outils de réduction du bruit, qui l'utilisent pour apprendre les caractéristiques du bruit et le soustraire de l'enregistrement.
Paramètres d'enregistrement qui affectent la précision de transcription
Au-delà du choix du microphone et du traitement de la pièce, quelques paramètres techniques d'enregistrement déterminent la quantité de détails vocaux qui survit jusqu'à l'étape de transcription.
Fréquence d'échantillonnage. La plupart des modèles ASR modernes rééchantillonnent tout en interne à 16 kHz — la fréquence sur laquelle ils ont été entraînés — donc une fréquence plus élevée n'améliore pas la précision. Enregistrez à 44,1 kHz ou 48 kHz pour la compatibilité et l'archivage propre, pas pour la précision de transcription; du mono 16 kHz suffit déjà au modèle. Au-delà de 48 kHz, il n'y a aucun bénéfice pour la reconnaissance vocale.
Profondeur de bits. Enregistrez en 16 bits ou 24 bits. La différence compte surtout pour les passages calmes : le 24 bits capture la parole douce avec moins de bruit de quantification, ce qui aide lorsque le locuteur est plus éloigné du microphone.
Mono vs stéréo. Pour un seul locuteur, le mono convient et produit des fichiers plus petits. Pour plusieurs locuteurs, enregistrer chaque voix sur un canal séparé améliore sensiblement la diarisation des locuteurs, car le modèle peut séparer des voix qui arrivent sur des canaux distincts et propres.
Format de fichier. WAV et FLAC sont sans perte et idéaux pour la transcription. Le MP3 à 192 kbps ou plus est acceptable ; l'AAC/M4A (utilisé par la plupart des téléphones) est légèrement meilleur que le MP3 au même débit ; l'OGG/Opus offre une bonne qualité à des débits plus faibles. Si le stockage le permet, archivez en WAV ou FLAC. La plupart des outils, y compris Vocova, acceptent tous les formats courants — la priorité est de préserver les détails dans l'enregistrement lui-même, pas le conteneur.
Choisir le type de microphone et la connexion
Les conseils sur le microphone ci-dessus se concentrent sur la directivité pour le rejet du bruit. Deux autres choix déterminent la qualité de base de tout enregistrement.
- Statique (condensateur) vs dynamique. Les microphones statiques sont plus sensibles et capturent plus de détails vocaux, ce qui aide dans des pièces calmes et contrôlées — mais ils captent aussi plus de bruit ambiant. Les microphones dynamiques rejettent davantage le bruit de fond par conception, ce qui en fait le choix le plus sûr dans des espaces non traités ou bruyants.
- USB vs XLR. Les microphones USB (par exemple le Rode NT-USB Mini ou l'Audio-Technica AT2020USB+) intègrent une interface audio et constituent le choix pragmatique pour la plupart des gens. Les microphones XLR nécessitent une interface séparée mais offrent des planchers de bruit plus bas et plus de contrôle — cela en vaut la peine surtout si vous possédez déjà l'interface.
Pour la transcription, l'environnement compte plus que le microphone spécifique. Un microphone USB à 50–100 $ correctement placé dans une pièce calme produit un audio de qualité transcription.
Conseils pour des scénarios d'enregistrement spécifiques
- Réunions : Utilisez un microphone de conférence dédié (comme le Jabra Speak ou l'Anker PowerConf) au centre de la table plutôt que le microphone d'un ordinateur portable. Pour les réunions à distance, enregistrez directement la sortie audio du logiciel de réunion et demandez aux participants de porter un casque pour éviter l'écho.
- Interviews : Donnez à l'intervieweur et à l'interviewé des microphones séparés — idéalement des micros-cravates sans fil enregistrés sur des canaux séparés. Pour les interviews téléphoniques, enregistrez via un logiciel plutôt que de pointer un microphone vers un haut-parleur.
- Conférences : Un micro-cravate sur le présentateur est l'installation la plus fiable. Faites répéter les questions du public par le présentateur avant d'y répondre, car l'audio du public est rarement capté proprement.
- Podcasts : Donnez à chaque animateur et invité son propre microphone sur une piste séparée. Pour l'enregistrement à distance, faites enregistrer chaque participant localement (avec des outils comme Riverside.fm ou Zencastr) et combinez les pistes ensuite pour éviter les artefacts de compression des appels vidéo.
Erreurs d'enregistrement courantes qui nuisent à la transcription
- Téléphone dans une poche ou un sac. Le tissu étouffe les hautes fréquences nécessaires pour distinguer les consonnes, et le mouvement ajoute un bruit de froissement. Posez le téléphone sur une surface stable face au locuteur.
- S'asseoir trop loin du microphone. La distance affaiblit le signal vocal tandis que le bruit de fond reste constant, de sorte que l'enregistrement finit par être dominé par le bruit. Restez proche.
- Gain réglé trop haut. L'écrêtage est une distorsion permanente qui ne peut pas être réparée. Réglez les niveaux pour que la parole normale culmine autour de -12 dB à -6 dB.
- Gain réglé trop bas. Enregistrer trop faiblement vous oblige à amplifier ensuite, ce qui amplifie aussi le plancher de bruit.
- Enregistrer via Bluetooth. Le profil Bluetooth mains-libres compresse fortement l'audio des appels. Utilisez une connexion filaire pour l'enregistrement chaque fois que possible.
- Aucun enregistrement de test. Enregistrez et réécoutez 30 secondes avant la vraie session. Détecter l'écho de la pièce, un bourdonnement ou un bruit de manipulation à l'avance coûte bien moins cher que de le découvrir après un enregistrement de deux heures.
Comment nettoyer un audio bruité avant la transcription
Si vous avez déjà un enregistrement bruité, des outils de traitement audio peuvent améliorer la qualité du signal avant de l'envoyer à un service de transcription. Les résultats n'égaleront pas un enregistrement original propre, mais ils peuvent aider.
Un avertissement qui surprend : le débruitage n'aide pas toujours la transcription IA. Les modèles de type Whisper ont été entraînés sur beaucoup d'audio imparfait, et plusieurs études de 2025-2026 (par exemple, When De-noising Hurts, 2025, et When Denoising Hinders, 2026) ont montré que les outils d'amélioration de la parole et de réduction du bruit pouvaient en réalité augmenter le taux d'erreur de mots — parfois fortement — même quand l'audio semblait plus propre à l'oreille humaine, parce que le traitement introduit des artefacts inconnus du modèle. La règle fiable : traitez un court échantillon dans les deux versions, transcrivez les deux, et gardez celle qui gagne. Étonnamment souvent, c'est l'audio brut. Les outils ci-dessous aident surtout sur les bruits stables et bien caractérisés; ils aident le moins, et peuvent nuire, sur les interférences proches de la parole et la réverbération.
Audacity (gratuit, open source)
Audacity est un éditeur audio gratuit avec un outil de réduction du bruit intégré.
- Sélectionnez une portion de l'audio qui contient uniquement du bruit (pas de parole)
- Allez dans Effet > Réduction du bruit > Prendre le profil du bruit
- Sélectionnez l'intégralité de la piste audio
- Appliquez la réduction du bruit avec des paramètres autour de 12 dB de réduction, 6 de sensibilité et 3 de lissage en fréquence
- Écoutez le résultat en aperçu et ajustez si la parole semble déformée
Audacity dispose également d'un filtre passe-haut (Effet > Courbe de filtre) qui peut supprimer les grondements basse fréquence du vent ou des systèmes CVC. Coupez les fréquences en dessous de 80-100 Hz pour les enregistrements vocaux.
Adobe Podcast Enhance Speech (gratuit, en ligne)
Adobe propose un outil en ligne gratuit qui utilise l'IA pour améliorer les enregistrements vocaux. Téléversez votre fichier audio et l'outil tente d'isoler la voix, de réduire le bruit et de normaliser le volume. Il fonctionne bien pour les niveaux de bruit modérés et est suffisamment simple pour les utilisateurs non techniques. La limitation est un plafond de taille de fichier et le fait qu'il traite l'ensemble du fichier sans contrôle granulaire.
iZotope RX
iZotope RX est une suite professionnelle de réparation audio utilisée dans la post-production pour la diffusion et le cinéma. Elle offre des outils avancés de réduction du bruit, de dé-réverbération, de dé-clic, de dé-ronronnement et d'isolation du dialogue. C'est l'option la plus performante mais elle s'accompagne d'une courbe d'apprentissage et d'un coût significatifs. Pour un travail régulier de transcription avec de l'audio difficile, l'investissement en vaut la peine.
Conseils généraux pour le nettoyage audio
- Appliquez la réduction du bruit de manière conservative. Des paramètres agressifs suppriment le bruit mais introduisent des artefacts qui sonnent comme un gargouillement métallique. Ces artefacts peuvent perturber les modèles ASR autant que le bruit original.
- Utilisez un filtre passe-haut pour supprimer les grondements en dessous de 80 Hz. La parole humaine ne contient pas d'informations significatives en dessous de cette fréquence.
- Normalisez le niveau audio pour que les pics de parole soient autour de -3 dB à -6 dB. Les modèles ASR fonctionnent mieux avec des niveaux de volume constants.
- Ne compressez pas excessivement la plage dynamique. Une certaine compression aide pour la parole chuchotée ou criée, mais une compression lourde relève le plancher de bruit.
Paramètres de transcription IA pour l'audio bruité
Une fois que vous avez nettoyé votre audio autant que possible, les bons paramètres de transcription peuvent encore améliorer la précision.
Spécifier la langue
La plupart des systèmes ASR fonctionnent mieux lorsque vous spécifiez la langue parlée plutôt que de vous fier à la détection automatique. La détection automatique ajoute une étape d'inférence supplémentaire qui peut mal se passer avec de l'audio bruité, sélectionnant potentiellement le mauvais modèle de langue pour l'ensemble de la transcription. Si vous connaissez la langue, définissez-la explicitement.
Choisir le bon niveau de modèle
De nombreux services de transcription proposent plusieurs niveaux de modèle, et les niveaux de plus haute précision gèrent généralement mieux le bruit, car ils utilisent des modèles plus grands avec davantage de capacité à séparer la parole des interférences. Si votre fournisseur en propose un, cela vaut la peine de l'essayer sur un échantillon difficile ; vous pouvez le tester avec votre propre extrait via l'outil audio en texte.
Utiliser la diarisation des locuteurs avec précaution
La diarisation des locuteurs, le processus d'identification de qui a dit quoi, repose sur la détection de différences acoustiques entre les locuteurs. Le bruit de fond peut masquer ces différences, faisant que le modèle de diarisation divise un locuteur en plusieurs étiquettes ou fusionne différents locuteurs en un seul. Si votre audio est bruité et que les résultats de diarisation semblent peu fiables, vous pouvez obtenir de meilleurs résultats en transcrivant sans diarisation et en ajoutant les étiquettes de locuteurs manuellement.
Découper les longs enregistrements en segments
Si seules certaines parties d'un long enregistrement sont bruitées, envisagez de diviser le fichier en segments et de les transcrire séparément. Cela empêche une section bruitée d'affecter les performances du modèle sur les portions plus propres. Vous pouvez également appliquer différents paramètres de réduction du bruit à différents segments selon leurs caractéristiques de bruit.
Conseils de nettoyage post-transcription
Même avec une préparation audio optimale et les bons paramètres de transcription, les enregistrements bruités produiront des transcriptions nécessitant une relecture manuelle. Voici des stratégies pour un nettoyage efficace.
Se concentrer d'abord sur les sections à fort taux d'erreur
Écoutez l'audio parallèlement à la transcription et identifiez les sections où la transcription diverge le plus de la parole réelle. Ce sont généralement les moments avec les niveaux de bruit les plus élevés. Priorisez la correction de ces sections plutôt que de lire l'ensemble de la transcription de manière linéaire.
Utiliser les horodatages pour naviguer
Les outils de transcription qui fournissent des horodatages au niveau du mot ou du segment vous permettent de cliquer directement sur la position audio correspondante. Cela rend la vérification et la correction des mots individuels beaucoup plus rapides que le balayage manuel de l'audio. Vocova fournit des horodatages pour chaque segment, vous permettant de sauter directement à n'importe quel point de l'enregistrement.
Surveiller les erreurs courantes induites par le bruit
L'audio bruité produit des erreurs de transcription caractéristiques :
- Mots fantômes insérés là où le modèle a interprété le bruit comme de la parole
- Mots manquants là où le bruit a complètement masqué le signal vocal
- Homophones et approximations où le modèle a choisi un mot similaire car le bruit obscurcissait les sons distinctifs
- Noms propres déformés puisque les noms et termes techniques sont moins prévisibles à partir du contexte
Utiliser rechercher-et-remplacer pour les erreurs systématiques
Si le modèle transcrit systématiquement mal un terme spécifique tout au long de l'enregistrement (un nom de personne, un nom d'entreprise, un mot technique), utilisez rechercher-et-remplacer pour corriger toutes les instances en une fois plutôt que de les corriger individuellement.
Envisager un second passage avec la traduction
Si la transcription originale comporte des erreurs significatives et que vous avez également besoin d'une version traduite, corriger d'abord la transcription source est essentiel. Les modèles de traduction propagent et amplifient parfois les erreurs du texte source. Nettoyez la transcription avant de traduire.
Quand l'audio bruité est irrécupérable
Il existe des situations où aucune réduction de bruit ni aucun réglage IA ne produira une transcription exploitable. Reconnaître ces cas tôt permet de gagner du temps et d'éviter la frustration.
Signes que l'audio peut être irrécupérable :
- Vous ne comprenez pas vous-même la parole en écoutant attentivement avec un casque
- Plusieurs locuteurs parlent simultanément pendant de longues périodes sans voix dominante claire
- Le SNR est inférieur à 5 dB, ce qui signifie que le bruit est presque aussi fort ou plus fort que la parole
- Un écrêtage sévère (distorsion due à un niveau d'enregistrement trop élevé) a corrompu définitivement la forme d'onde
- Une réverbération intense fait que la parole semble enregistrée dans un tunnel ou une cage d'escalier
Options quand la transcription IA échoue
- Transcription humaine par un professionnel qui peut utiliser des indices contextuels, la lecture labiale (si la vidéo est disponible) et l'expertise du domaine pour décoder un audio difficile. C'est plus lent et plus coûteux mais gère les cas limites que l'IA ne peut pas traiter. Pour une comparaison approfondie, consultez notre guide sur la transcription IA vs humaine.
- Réenregistrer si possible. Si le contenu le permet, programmer une nouvelle session d'enregistrement avec un meilleur équipement et un meilleur environnement est souvent plus rapide que d'essayer de sauver un enregistrement sévèrement dégradé.
- Transcription partielle. Transcrivez les sections avec une qualité audio acceptable et notez les lacunes. Une transcription avec des sections clairement marquées [inaudible] est plus utile qu'une remplie de suppositions incorrectes.
Questions fréquemment posées
Quel est le facteur le plus important affectant la précision de transcription ?
Le rapport signal sur bruit. Plus la parole est forte par rapport au bruit de fond, plus précisément tout outil de transcription, qu'il soit IA ou humain, peut identifier les mots. Un microphone positionné près du locuteur dans une pièce calme produit les meilleurs résultats. Consultez les sections ci-dessus sur les paramètres d'enregistrement, le choix du microphone et la réduction du bruit de fond pour les moyens les plus rapides de l'augmenter.
Les outils de transcription IA peuvent-ils gérer la musique de fond ?
Modérément. Si la musique est discrète et la parole est claire, la plupart des modèles ASR modernes peuvent transcrire à travers. La musique forte, en particulier avec des voix, cause des problèmes de précision significatifs car le modèle ne peut pas distinguer de manière fiable la parole cible du chant. La musique instrumentale de fond à faible volume est moins perturbatrice que la musique vocale à n'importe quel volume.
Devrais-je utiliser la réduction du bruit avant de téléverser l'audio pour la transcription ?
Pas automatiquement : testez d'abord. Il semble logique qu'un audio plus propre se transcrive mieux, mais les modèles modernes comme Whisper ont été entraînés sur des données bruitées, et des études de 2025-2026 ont montré que le débruitage et l'amélioration de la parole augmentaient souvent le taux d'erreur de mots, même quand l'audio sonnait mieux pour un humain, parce que le traitement ajoute des artefacts inconnus du modèle. L'approche fiable consiste à transcrire un court échantillon brut et un échantillon débruité, puis à garder le plus précis. Si vous débruitez, restez doux : les réglages agressifs introduisent des artefacts métalliques qui font plus de mal que de bien.
Spécifier la langue améliore-t-il la précision pour l'audio bruité ?
Oui. Lorsque vous définissez manuellement la langue, le modèle ASR utilise le bon vocabulaire et le bon modèle de langue dès le départ. Avec de l'audio bruité, l'étape de détection automatique est plus susceptible de mal identifier la langue, ce qui applique alors le mauvais modèle pour l'ensemble de la transcription. Spécifiez toujours la langue lorsque vous la connaissez.
Dans quelle mesure la qualité audio affecte-t-elle le taux d'erreur de mots ?
Considérablement, même si les chiffres exacts varient selon le modèle, la langue et le type de bruit; traitez-les donc comme des illustrations approximatives, pas comme des garanties mesurées. Un audio studio propre se situe souvent sous 5 % WER avec l'ASR moderne; un bruit modéré de bureau ou de circulation légère se place plutôt dans les faibles deux chiffres; un restaurant bondé ou un chantier peut dépasser 30 %. La relation n'est pas linéaire : la précision se dégrade rapidement lorsque le SNR descend sous environ 15 dB. Pour voir à quel point la base en audio propre varie déjà entre les langues, consultez la précision de transcription par langue.
Vaut-il mieux transcrire de l'audio bruité avec l'IA ou un transcripteur humain ?
Pour de l'audio modérément bruité, les outils IA sont généralement suffisants et beaucoup plus rapides. Pour de l'audio sévèrement dégradé où même une écoute attentive est difficile, un transcripteur humain qualifié surpassera généralement l'IA car il peut utiliser le raisonnement contextuel, la connaissance du sujet et les indices visuels de la vidéo pour combler les lacunes. La comparaison entre transcription IA et humaine dépend fortement des conditions de bruit spécifiques et de vos exigences de précision.
Quel est le meilleur format audio pour la transcription ?
WAV et FLAC sont les meilleurs car ils sont sans perte et préservent l'intégralité des détails audio. En pratique, le MP3 à 192 kbps ou plus fonctionne aussi très bien. La plupart des outils de transcription IA acceptent tous les formats courants, donc la priorité est d'enregistrer à un débit élevé plutôt que de se soucier du format de conteneur spécifique.
Vaut-il la peine d'acheter un microphone coûteux pour la transcription ?
Généralement non. Un microphone USB à 50–100 $ dans une pièce calme avec un placement correct produit un audio de qualité transcription. Les microphones coûteux ajoutent une richesse vocale qui compte davantage pour la musique et la diffusion que pour la précision de la reconnaissance vocale. Investissez dans le traitement de la pièce et le placement du microphone avant d'améliorer le microphone lui-même.
Sources et lectures complémentaires
- Chondhekar et al., "When De-noising Hurts: A Systematic Study of Speech Enhancement Effects on Modern Medical ASR Systems" (arXiv, 2025) -- l'amélioration vocale a augmenté le taux d'erreur de mots sur des modèles de type Whisper, même lorsque l'audio semblait plus propre
- Islam, Nahar & Hamid, "When Denoising Hinders: Revisiting Zero-Shot ASR with SAM-Audio and Whisper" (arXiv, 2026)
- Mu et al., "Performance evaluation of automatic speech recognition systems on integrated noise-network distorted speech", Frontiers in Signal Processing (2022) -- WER en fonction du SNR
- Hugging Face Audio Course -- preprocessing -- les modèles ASR modernes attendent un audio à 16 kHz
- Engineering ToolBox -- inverse-square law -- la règle pratique d'environ 6 dB perdus à chaque doublement de la distance
- National Center for Voice and Speech -- fundamental frequency -- contexte pour le filtre passe-haut autour de 80-100 Hz
