如何將音訊轉成多語言文字:2026 工作流程指南
一份實用的多語言音訊轉錄工作流程,涵蓋語言偵測、code-switching、翻譯到 140+ 種目標語言、雙語逐字稿、字幕與品質檢查。
最後驗證日期:2026-06-23。本文中 Vocova 專屬的數字(免費方案分鐘數/檔案大小、Plus / Pro 功能、支援語言數)對應該日期當下的產品設定——若 App 上看到的數字與本文不同,請以 App 為準。
最安全的多語言工作流程是:先用原始口語把音訊轉錄出來,校對來源逐字稿,再翻譯。除非你能接受失去時間軸、講者標籤,以及審查錯誤的能力,否則不要直接從音訊跳到翻譯後的文字。
對多數團隊而言,實務流程像這樣:
- 上傳音訊,或貼上一條公開的媒體 URL。
- 讓工具偵測口語,或手動選擇。
- 用來源語言產出帶時間軸的逐字稿。
- 校對名稱、數字與專業術語。
- 把逐字稿翻譯成目標語言。
- 匯出文字、雙語文件,或翻譯後的字幕。
Vocova 支援 100 種以上的口語轉錄,並在 Plus / Pro 提供 140 種以上的目標語言翻譯。如果是檔案,從 音訊轉文字 開始;影片用 影片轉文字;翻譯流程用 音訊翻譯;要做字幕請看 影片翻譯。
多語言轉錄工作流程
| 步驟 | 決策 | 最佳實務 |
|---|---|---|
| 匯入 | 上傳檔案或公開 URL | 私人檔案上傳;公開的 YouTube、Bilibili、SoundCloud、Dailymotion、Podcast 或雲端硬碟錄音則貼連結 |
| 語言設定 | 自動偵測或手動指定 | 不確定時用自動偵測;已知語言或開頭雜訊多時手動指定 |
| 轉錄 | 來源語言逐字稿 | 保留時間軸與講者標籤,讓逐字稿可審查 |
| 校對 | 名稱、術語、數字、講者 | 翻譯前先修高影響的錯誤 |
| 翻譯 | 一種或多種目標語言 | 來源校對完才翻譯,不要先翻 |
| 匯出 | TXT、PDF、DOCX、SRT、VTT、CSV、雙語輸出 | 依最終用途挑格式 |
自動語言偵測夠用的時機
當錄音中第一段清楚的口語就代表主要語言時,自動語言偵測表現很好。以下情境可以放心使用:
- 不確定口語是哪種語言的訪談。
- 使用者上傳的音訊檔案。
- 來自不同國家的 Podcast 節目。
- 跨地區收集的研究錄音。
- 檔名命名不一致的影片庫。
當第一分鐘是配樂、靜音、標題卡、音效,或講者短暫用另一種語言問候觀眾時,自動偵測就不那麼可靠。這些情況下,請在開始前手動選擇語言。
手動選擇語言的時機
當你已經知道語言或方言族群時,手動選語言能改善準確度。下列情境特別有用:
- 開頭很長的日文、韓文、普通話、廣東話、泰文或阿拉伯文內容。
- 第一位講者使用的語言與其餘錄音不同。
- 以英文標題卡開場、但接下來改用其他語言的教育影片。
- 主要由某一種語言主導的多語言會議。
- 帶有強烈口音或領域術語的錄音。
手動選擇不是在限制模型;它給轉錄系統一個更穩固的起點,能減少早期分類錯誤。
如何處理含多種語言的錄音
常見的多語言型態有三種。
一段錄音一種語言
這是最簡單的情況。一場法文訪談、一場日文講座,或一集西班牙文 Podcast,可以先用來源語言轉錄,再校對,最後翻成英文或其他目標語言。
建議流程:
- 已知語言時手動指定來源語言。
- 轉錄。
- 校對專有名詞與術語。
- 翻譯。
- 若需要校對,匯出雙語文件。
同一段錄音裡 code-switching
Code-switching 指說話者在同一段對話中切換語言,有時甚至在同一句話裡。常見組合包括印地文-英文、西班牙文-英文、中英夾雜、韓英夾雜,以及阿拉伯文-法文。
建議流程:
- 選擇主導語言。
- 把整段錄音轉錄完。
- 對混合語言的段落進行手動校對。
- 等來源逐字稿可讀後再翻譯。
- 把原文逐字稿與翻譯並列保留。
不要期望全自動翻譯能解決每個混合語言的片段。逐字稿才是審查層。
多位講者使用不同語言
這常見於國際會議、客戶訪談、學術田野調查,以及多語言 webinar。可能一位講者用葡萄牙文,一位用英文,一位用日文。
建議流程:
- 若可,啟用講者識別。
- 用主導語言轉錄,或用自動偵測。
- 修正講者名稱與語言相關的術語。
- 翻譯成審查語言。
- 匯出雙語輸出,讓校對者能對照原文與翻譯。
這裡講者標籤很重要。它能清楚標明誰說了什麼,當這份翻譯日後變成會議紀錄、研究筆記或客戶證據時,這是不可或缺的。
為什麼不要在校對前就翻譯
翻譯品質取決於來源品質。如果來源逐字稿寫錯產品名、人名、法律術語、藥名、公司、遊戲標題或地名,翻譯通常會把錯誤照樣保留。
翻譯前請先校對:
- 人名、公司、產品、藝人、節目、遊戲與地名。
- 數字、日期、時間、價格與度量。
- 縮寫與專業術語。
- 講者標籤。
- 因音訊瑕疵造成的重複片段。
- 講者重疊的段落。
你不必把每一句話都打磨完美才翻譯。把那些一旦翻錯就會代價高昂或令人尷尬的詞先修對即可。
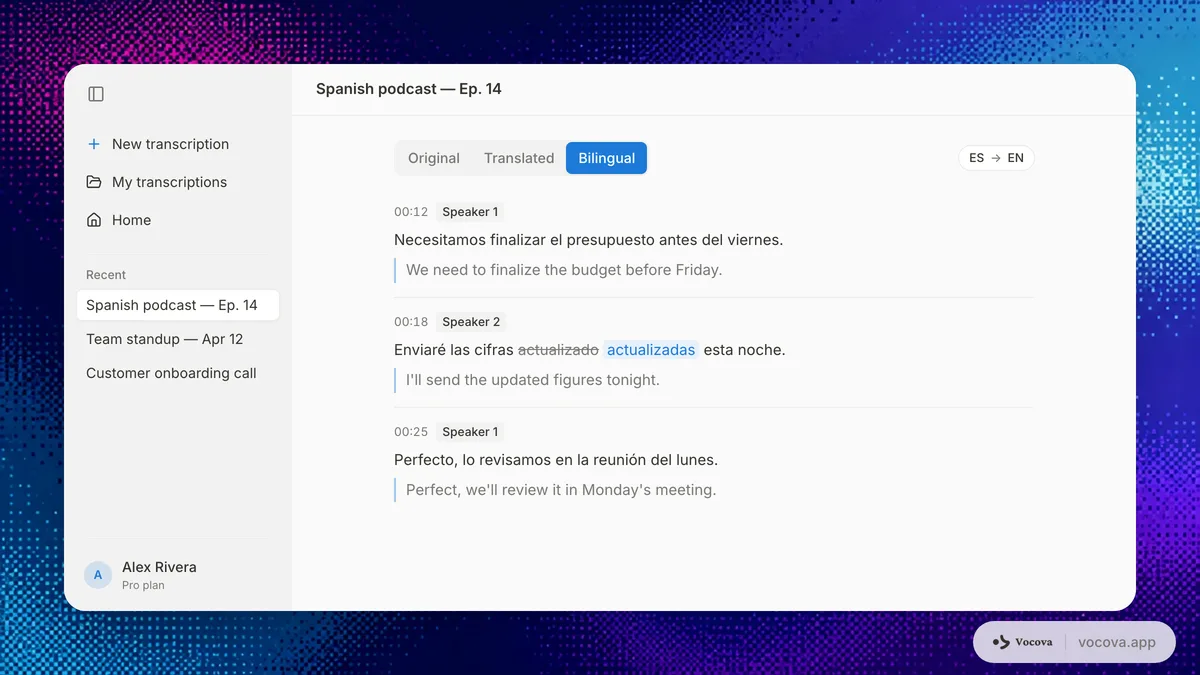
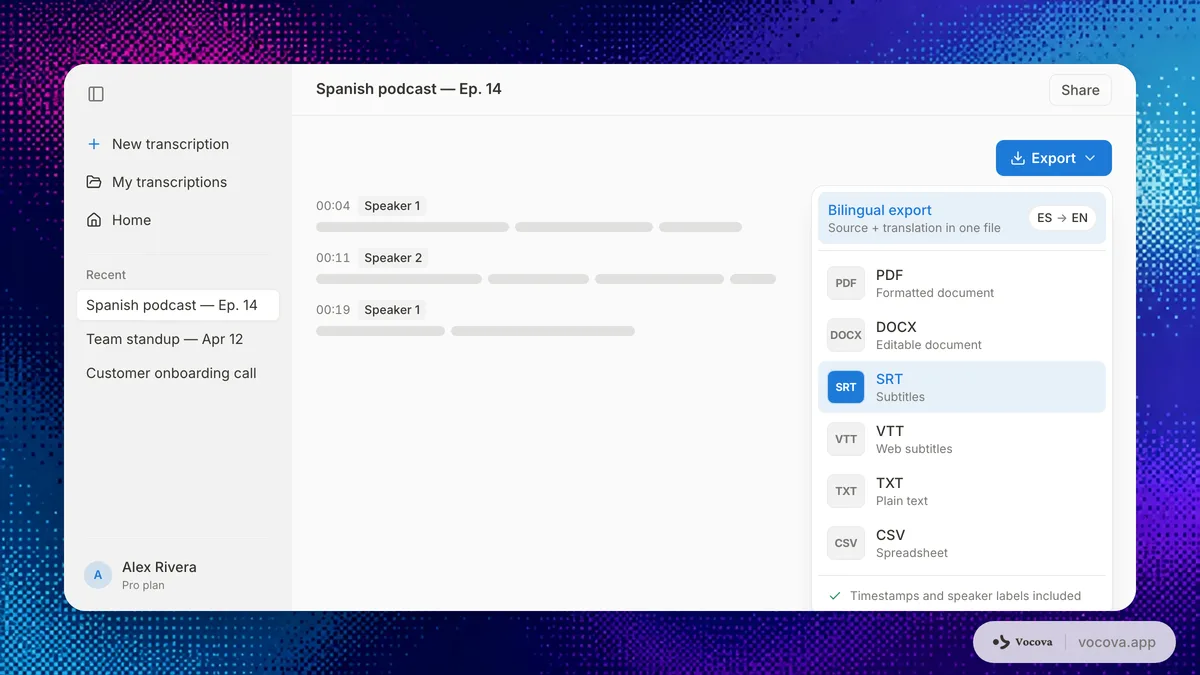
多語言工作的匯出選擇
| 輸出 | 適用情境 | 備註 |
|---|---|---|
| TXT | 快速複製、筆記、搜尋 | 最適合單純的文字再利用 |
| 分享完成的逐字稿 | 適合給客戶、團隊與歸檔 | |
| DOCX | 編輯與留言 | 需要人工修訂時最佳 |
| SRT | 影片字幕 | 與影片平台相容性佳 |
| VTT | 網頁影片字幕 | 較適合 HTML5 與網頁播放器 |
| CSV | 研究、分析、QA | 適合做片段層級的審查 |
| 雙語匯出 | 翻譯校對 | 來源與目標並排呈現 |
字幕工作流程可參考 SRT generator、VTT generator、SRT vs VTT,以及 字幕檔案格式完整指南。
工作示範:45 分鐘的西班牙文 Podcast → 英文雙語 SRT
把流程具體化:以下是處理一集 Podcast 從頭到尾大約會花的時間。數字是兩位講者的乾淨錄音的典型值;雜訊較多的田野音訊會更慢。
| 階段 | 動作 | 時間 | 產出 |
|---|---|---|---|
| 1 | 在 Plus 上傳 45 分鐘的 MP3(約 65 MB),或貼上公開節目 URL | 1 分鐘 | 檔案排隊中 |
| 2 | 自動偵測選擇西班牙文;轉錄在伺服器端執行 | 4–6 分鐘 | 帶時間軸的來源逐字稿 |
| 3 | 掃讀專有名詞:主持人、來賓、品牌名、單集特定詞彙;修正 8–15 個項目 | 8–12 分鐘 | 校對後的來源逐字稿 |
| 4 | 把逐字稿翻譯成英文(Plus / Pro) | 2–4 分鐘 | 英文逐字稿 |
| 5 | 抽查英文輸出——重點放在名稱、數字、日期與技術術語 | 8–12 分鐘 | 校對後的英文 |
| 6 | 為字幕工作流程匯出雙語 SRT;或為內容再利用匯出雙語 DOCX | 1 分鐘 | 最終交付物 |
合計:人力大約花 25–35 分鐘處理 45 分鐘的節目(模型時間多半在背景跑)。最花時間的是階段 3 與 5——對來源逐字稿做專有名詞校對,以及對翻譯後輸出做完整檢查。跳過這兩步,必然會產出讀起來流暢、卻把來賓搞錯或把產品名翻錯的英文。
來源語言不同時,幾件事會變:
- 高資源語言(英文、西班牙文、法文、德文、義大利文、葡萄牙文、日文、普通話)大致符合上面的時間表。
- 中等資源語言(韓文、荷蘭文、俄文、阿拉伯文、波蘭文、越南文、泰文)在階段 3 與 5 通常需要 1.5–2 倍的清理時間。
- 低資源語言(語言分級可看 各語言轉錄準確度)通常需要再多一輪校對,翻譯這一步才會划得來。
同樣流程的變化版:
- 多語訪談——把步驟 6 換成帶時間軸的雙語 DOCX/PDF,可看 multilingual interview workflows。
- 全球 Podcast 內容再利用——以同一份來源逐字稿,平行翻譯到多種目標語言;保留一份已校對的來源作為基準,可看 如何用 AI 轉錄將 Podcast 和線上研討會轉化為 10+ 篇內容。
- 客戶通話與業務研究——保留時間軸、講者標籤,並在翻譯旁同時呈現來源逐字稿,讓引文可以被審查。
- 翻譯字幕——從 影片翻譯 開始;發布前確認每行長度。
常見語言對與起點
如果目標是英文,音訊翻譯 能處理下方所有來源語言——匯入時選來源、匯出時選英文即可。下表列出只需要原文逐字稿(不需翻譯)時對應的語言專屬轉錄工具。
| 來源語言 | 只需要原文逐字稿 |
|---|---|
| 日文 | 日文語音轉文字 |
| 韓文 | 韓語轉錄 |
| 普通話/中文 | 中文語音轉錄 |
| 西班牙文 | 西班牙語轉錄 |
| 法文 | 法語轉錄 |
| 葡萄牙文 | 葡萄牙語轉錄 |
| 德文 | 德語轉錄 |
| 義大利文 | 義大利文轉錄 |
| 阿拉伯文 | 阿拉伯語轉錄 |
| 印地文 | 印地語轉錄 |
對於上表未列出的來源/目標組合,同一個 音訊翻譯 工具仍涵蓋 100+ 種來源語言的轉錄與 140+ 種目標語言的翻譯——匯入時挑來源、匯出時挑目標。
多語言逐字稿的品質檢查
請使用一份輕量的審查清單:
- 偵測到的語言是否符合實際的主要語言?
- 講者標籤對於用途來說夠正確嗎?
- 名稱與產品術語的拼寫是否一致?
- 數字與日期是否正確?
- 混合語言的句子是否被正確保留?
- 翻譯有沒有保留意思,而不只是字面?
- 字幕能不能在不過長的情況下顯示?
- 匯出格式是否符合工作流程下一個工具的需求?
更技術性的準確度框架可看 字詞錯誤率(WER) 與 各語言轉錄準確度。
常見錯誤
用只支援英文的工具處理多語言音訊
部分會議工具對英文會議很出色,但在多語言檔案、地區口音或翻譯流程上偏弱。如果你的來源語言會跨專案變動,從一開始就選擇為多語言轉錄而生的工具。
把翻譯當成第一步
需要準確時,請務必先建立來源逐字稿。來源逐字稿給你時間軸、講者,以及一條可審查的軌跡。
忽略字幕格式
如果最終交付物是字幕,請早早決定 SRT 與 VTT。光匯出文字不足以做影片在地化。
沒有確認檔案與匯出限制
免費方案適合做測試,但多語言工作流程經常需要更大檔案、多次匯出、翻譯與字幕。在處理長錄音之前,先確認這些功能是否包含在內。
為什麼多語言轉錄很重要
語言隔閡很昂貴。對跨國團隊而言,溝通落差會以錯失交易、重工、反覆確認的形式變成實際營收損失。企業也經常把缺乏多語言能力列為失去國際業務的原因。根據 Ethnologue,目前仍在使用的活語言超過 7,100 種,而遠距與混合辦公已成常態;一場訪談、會議或客戶通話跨越多種語言的機率,比五年前高得多。AI 轉錄與翻譯把過去需要人工口譯或翻譯數天完成的工作壓縮到幾分鐘內,這也是上方工作流程逐漸成為全球團隊標準作業方式的原因。
多語言轉錄背後的技術
多語言準確度快速提升,背後有幾個值得理解的技術轉變。它們有助於你為一段錄音設定合理期待。
- 統一的多語言模型。 最強的引擎現在不是每種語言各用一個模型,而是在單一模型中處理 100 種以上語言。Whisper 使用 680,000 小時多語言音訊訓練;ElevenLabs Scribe 推出時支援 99 種語言,並在主要語言上回報高準確度;Meta 的研究把覆蓋範圍推進到 1,000 種以上語言,其中包含數百種過去幾乎沒有 AI 轉錄支援的語言。
- 遷移學習。 語言之間共享語音與結構特徵,因此在英文、普通話等高資源語言上大量訓練的模型,可以把部分知識遷移到相關語言,例如從西班牙文到葡萄牙文,在不需要每種語言都有同等訓練資料的情況下提升準確度。
- 自監督預訓練。 wav2vec 這類技術讓模型先從大量未標註音訊中學習,再用規模較小的標註資料微調。這正是低資源語言能被實務處理的關鍵。
- 自動語言偵測與 code-switching。 因為模型同時學習多種語言,它們能在沒有手動設定的情況下辨識說話語言,也能處理說話者在句子中途切換語言的情況。這兩點都是真實多語言音訊不可或缺的能力。
仍然存在的挑戰
多語言轉錄還不是完全解決的問題。請依照下列限制設定期待:
- 低資源語言。 研究模型的覆蓋範圍已經超過 1,000 種語言,但許多語言的準確度仍明顯低於訓練資料充足的高資源語言。
- 方言差異。 用標準阿拉伯語訓練的模型可能難以處理摩洛哥達里賈;普通話模型也可能無法妥善處理廣東話。按語言統計的平均準確度會遮蔽這條長尾。
- 帶口音的語音。 非母語者通常會有較高錯誤率。對許多成員使用第二或第三語言工作的全球團隊來說,這也是實際的公平性問題。
- 翻譯中的文化與語境細微差異。 即使逐字稿正確,翻譯也可能遺失慣用語或專業領域含義。法律、醫療、已發表研究等高風險內容,應保留人工審閱環節。這正是上方流程在翻譯前先檢查來源逐字稿的原因。
這些限制背後的分層基準可參考各語言的轉錄準確度。
常見問題
AI 可以做多語言語音轉文字嗎?
可以。現代 AI 轉錄能處理多種語言,Vocova 支援 100 種以上的口語轉錄並具備自動偵測。準確度仍會受到語言、音質、口音與是否有 code-switching 影響。
我可以把音訊直接翻成英文嗎?
可以,但更安全的工作流程是先把原始音訊轉錄出來,再翻譯逐字稿。這樣會保留時間軸,並讓你在翻譯看起來怪的時候有來源文字可以審查。
雙語逐字稿的最佳格式是什麼?
需要人工閱讀與校對時用 PDF 或 DOCX。雙語輸出要做字幕時用 SRT 或 VTT。需要片段層級的分析時用 CSV。
同一句話有兩種語言怎麼辦?
選擇主導語言、轉錄、再對混合語言的段落手動校對。Code-switching 比單一語言難,所以請在翻譯旁同時保留來源逐字稿。
轉錄完成後可以翻譯字幕嗎?
可以。先產生來源逐字稿,翻譯後再匯出 SRT 或 VTT。發布前請檢查行長與時間。
哪些語言的轉錄最準確?
英文、西班牙文、法文、德文、義大利文、葡萄牙文、日文與普通話這類高資源語言,在乾淨音訊上通常表現較好。低資源語言、強烈口音、講者重疊與雜訊錄音會需要更多校對。基準對照可看 各語言轉錄準確度。
免費方案能跑得動真實的多語言工作流程嗎?
要看錄音長度。免費方案提供30 分鐘的入門轉錄額度、檔案最大 30 MB、3 個儲存的轉錄——足以在你的目標語言上用一段短片驗證準確度,並確認流程是否合用,再決定是否升級到付費方案。一集 45 分鐘的 Podcast 或一場 1 小時的訪談本身就會超過免費分鐘數,多數多語言工作流程也會用到付費功能,例如翻譯、雙語匯出、更大檔案或字幕匯出。如果你正在評估,先用 Free 試一段 3–5 分鐘的代表性樣本,確認準確度與語言覆蓋後再升級到 Plus。
逐字稿的 AI 翻譯和人工翻譯相比如何?
AI 翻譯更快也更便宜,通常幾秒內就能產生結果,而不是等上數天。對會議記錄、字幕、內部文件等日常用途來說,品質通常已足夠,不需要大量手動編修。若是法律文件、已發表研究、法規送審資料等高風險內容,仍建議由人類審閱 AI 產生的翻譯。
轉錄和翻譯需要分開使用不同工具嗎?
不一定。整合式平台能在同一個工作流程中完成兩個步驟,讓時間戳記、講者標籤與格式在轉錄和翻譯之間保持一致。這樣就不用先從一個工具匯出逐字稿,再上傳到翻譯服務,最後手動重組結果。
資料來源與延伸閱讀
外部來源:
相關 Vocova 指南:
- 最佳免費語音轉文字工具——每個免費方案實際能讓你完成什麼。
- 如何轉錄 YouTube 影片——比較五種方法,YouTube 是多語言音訊最常見的來源之一。
- 如何轉錄 Bilibili 影片——以 Bilibili 平台為例的中翻英深入指南。
- 如何貼上連結轉錄線上影片與 Podcast——跨 YouTube、Bilibili、SoundCloud、Dailymotion、Podcast 與雲端硬碟的 URL 匯入工作流程。
- 各語言轉錄準確度——各語言分級的預期表現。
工具:
